📝 Paper Summary
Conversational personalization
Representation editing
Chameleon personalizes LLMs without fine-tuning by generating synthetic user preference data from history and applying inference-time representation editing to steer model embeddings toward personalized subspaces.
Core Problem
Existing personalization methods are either computationally prohibitive (fine-tuning per user) or rely on high-quality datasets that are often unavailable (retrieval-based methods).
Why it matters:
- Fine-tuning approaches are resource-intensive and difficult to scale to large, rapidly evolving user bases
- Retrieval-based methods (RAG) struggle with limited context windows and the scarcity of high-quality retrieval datasets for individual users
- Current methods fail to meet the dual requirements of data efficiency (minimal interaction) and compute efficiency (scalable deployment)
Concrete Example:
A standard LLM might answer a query in a generic, formal tone. A user with a history of 'funny' interactions prefers a humorous response. Fine-tuning a model just for this user is too costly, while RAG might retrieve irrelevant history if the exact context is missing. Chameleon synthesizes a 'funny' profile and steers the model's internal vectors to output humor without retraining.
Key Novelty
Chameleon (Synthetic Data + Representation Editing)
- Generates 'fake' synthetic preference pairs (personalized vs. neutral) using the model itself, guided by insights extracted from a small subset of user history
- Identifies personalized vs. non-personalized directions in the model's embedding space using these synthetic pairs via SVD (Singular Value Decomposition) and CCS (Contrastive Consistent Search)
- Performs inference-time editing by mathematically adding the personalized direction and subtracting the neutral direction from the model's hidden states
Architecture
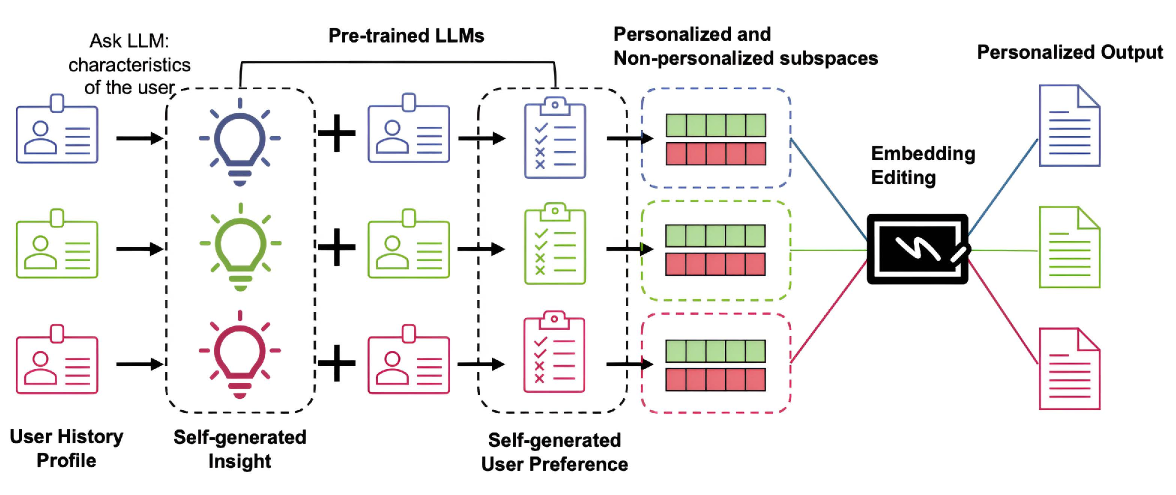
Overview of the Chameleon framework showing the two-stage process: generating synthetic data and then editing representations.
Evaluation Highlights
- Improves upon instruction-tuned models and two personalization baselines by an average of 40% across two model architectures on the LaMP benchmark
- Demonstrates capability to personalize for new, unseen users (cold start) by leveraging group-level profiles from users with similar characteristics
Breakthrough Assessment
7/10
Proposes a clever, compute-efficient alternative to fine-tuning for personalization. While the 40% gain is impressive, the reliance on synthetic 'hallucinated' preferences needs robustness checks across more domains.