📝 Paper Summary
Personalized Text Generation
Recommendation Personalization
This survey unifies the disconnected fields of personalized text generation and downstream task personalization into a single framework, formalizing shared definitions, granularities, and evaluation metrics.
Core Problem
Research on personalized LLMs is fragmented into two isolated communities: one focusing on text generation quality and another on downstream tasks like recommendation, utilizing different terminologies and metrics despite sharing underlying mechanisms.
Why it matters:
- Prior surveys examine these aspects in isolation, missing opportunities to transfer techniques (e.g., retrieval methods) between generative and task-oriented personalization
- Lack of a unified formalism hinders the development of generalist agents that can seamlessly transition from personalized conversation to task-oriented reasoning
Concrete Example:
A 'personalized text generation' researcher might evaluate a chatbot's empathy directly against user writings, while a 'downstream task' researcher uses LLM embeddings to improve movie rating predictions. Both use user history and retrieval, but they optimize for different objectives (text quality vs. prediction accuracy) without cross-pollinating insights.
Key Novelty
Unified Personalization Taxonomy
- Conceptualizes personalization as two sides of the same coin: 'Direct' (optimizing the text itself for user alignment) and 'Indirect' (using intermediate text/embeddings to optimize a separate function like a recommender system)
- Formalizes personalization granularity into three levels: User-level (finest), Persona-level (group-based), and Global (general public), characterizing the trade-offs between data requirements and specificity
Architecture
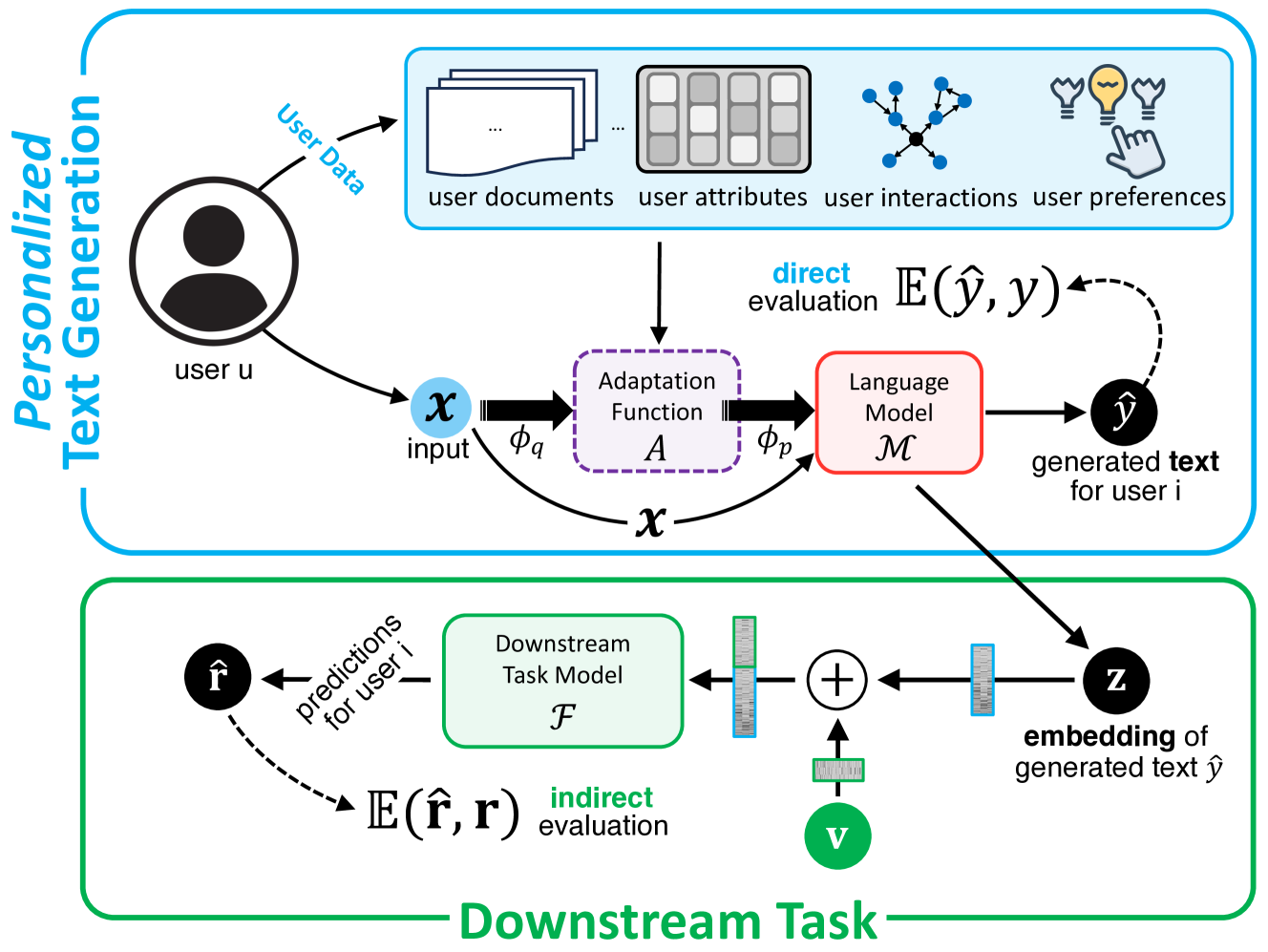
A taxonomy and workflow diagram illustrating the two main usage categories of personalized LLMs: Personalized Text Generation and Downstream Task Personalization.
Breakthrough Assessment
5/10
A comprehensive survey that provides a necessary structural framework and taxonomy for a fragmented field, though it does not introduce a new algorithm or experimental breakthrough itself.