📝 Paper Summary
Personalized Text Generation
Decoding Strategies
CoPe personalizes LLM outputs by contrasting the logits of a user-tuned model against a base model during decoding, effectively maximizing an implicit user reward without external reward models.
Core Problem
Existing personalization methods are either prompt-based (limited memory, no learning) or training-based (costly, prone to forgetting), while decoding-time strategies for personalization remain unexplored.
Why it matters:
- Generic LLMs fail to align with individual writing styles and preferences required for assistants and recommendation systems.
- Frequent retraining of full models to reflect evolving user preferences is computationally prohibitive and risks catastrophic forgetting.
- Prompting methods struggle with context length limitations and cannot deeply internalize user behavior like parametric methods can.
Concrete Example:
A generic model might answer a news query with a neutral summary, whereas a specific user might prefer a witty, editorial-style headline. Standard fine-tuning might lose general knowledge, while CoPe dynamically steers the generic model's output toward the user's style during generation.
Key Novelty
Implicit Reward-Guided Decoding (CoPe)
- Leverages the insight that the log-likelihood ratio between a user-tuned model and a base model serves as an 'implicit reward' signal for user preference.
- Implements this signal via contrastive decoding: the model boosts tokens favored by the personalized adapter while penalizing generic tokens favored by the base model.
- Introduces a training scheme that synthesizes 'negative' user examples (generic outputs) to optimize the adapter via Direct Preference Optimization (DPO) before decoding.
Architecture
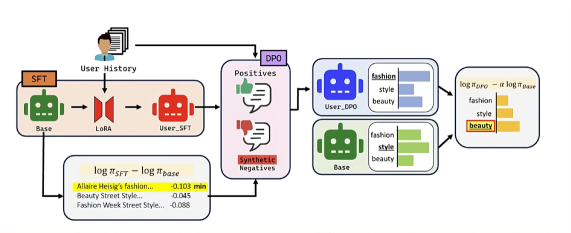
Overview of the CoPe pipeline including the training phase (constructing preference datasets via implicit reward) and the decoding phase (contrasting logits).
Evaluation Highlights
- Achieves an average relative improvement of 10.57% in ROUGE-L across five open-ended generation tasks compared to standard task-finetuned models.
- Outperforms a simply personalized model (without contrastive decoding) by an average of 5.67% in ROUGE-L, demonstrating the specific value of the decoding strategy.
- Demonstrates generalization across different model scales and architectures (Llama-2, Mistral, Solar) without requiring external reward models.
Breakthrough Assessment
7/10
Offers a clever link between contrastive decoding and implicit rewards for personalization. While mathematically grounded in existing concepts (DPO/Contrastive Decoding), applying it to personalization to avoid external reward models is a practical and effective innovation.