📝 Paper Summary
Conversational personalization
User-profile based personalization
PediaMind-R1 personalizes parenting advice by embedding the Thomas–Chess temperament framework into an LLM via supervised reasoning training and group-relative reinforcement learning.
Core Problem
Generic LLMs provide one-size-fits-all parenting advice that ignores individual infant temperaments, which is critical because infants cannot articulate their own needs.
Why it matters:
- Infant care requires proxy-driven personalization because the end-user (the infant) is non-verbal
- Mismatched caregiving strategies (e.g., forcing a 'slow-to-warm-up' child to socialize immediately) can negatively impact long-term development
- Existing personalization methods rely on interaction history or explicit feedback, which are often unavailable in cold-start parenting scenarios
Concrete Example:
Scenario: A child hides when guests visit. A generic model might suggest 'insisting the child come out to build confidence.' PediaMind-R1, identifying the 'slow-to-warm-up' temperament, advises 'waiting for the child to adjust and gently inviting them later,' aligning with psychological best practices.
Key Novelty
Temperament-Aware Reasoning via Cognitive Modeling & GRPO
- Integrates the Thomas–Chess psychological framework (Easy, Difficult, Slow-to-Warm-Up) directly into the model's reasoning process as a structured personalization signal
- Uses Group Relative Policy Optimization (GRPO) to enforce psychological consistency by rewarding outputs that align with expert-curated temperament strategies relative to a group of sampled responses
Architecture
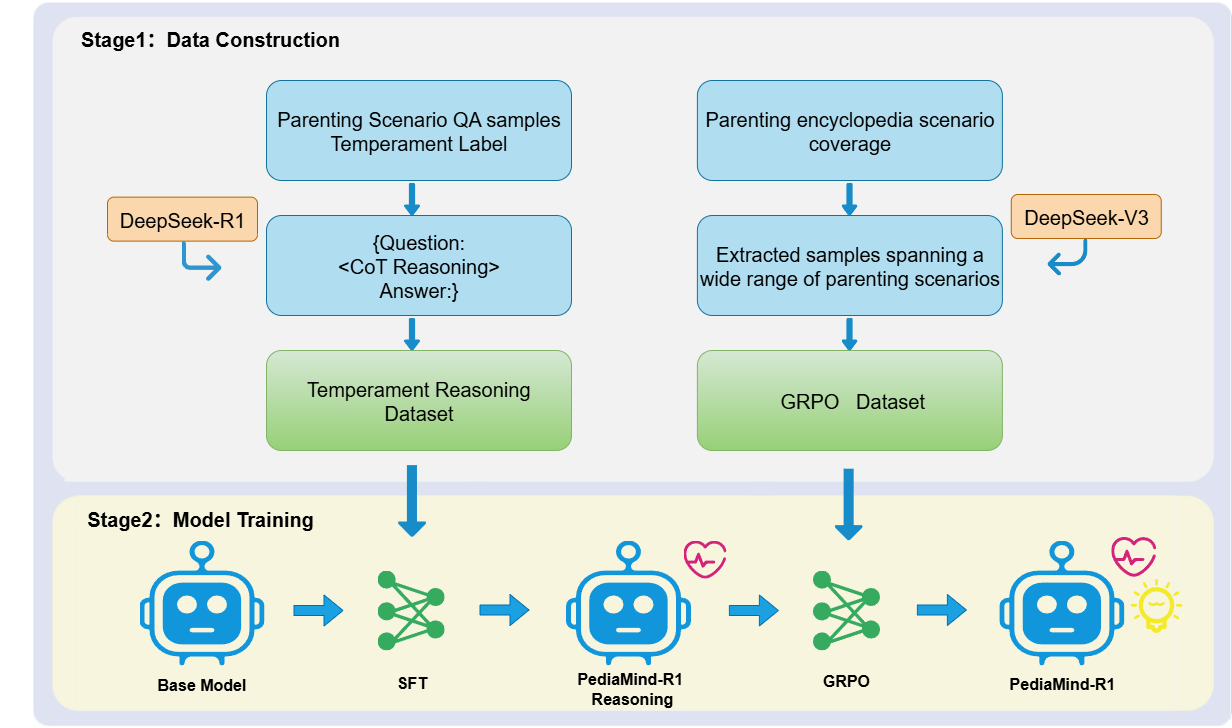
The two-stage training pipeline comprising SFT and GRPO.
Evaluation Highlights
- +36.5% accuracy improvement on temperament-sensitive multiple-choice benchmarks compared to the Qwen2.5-7B-Instruct baseline
- GRPO alignment improved 'Psychological Appropriateness' scores in human expert evaluations from 0.76 (SFT only) to 0.88
- Achieved 0.85 expert rating on 'Caregiving Suitability', significantly outperforming the unaligned baseline
Breakthrough Assessment
7/10
Strong domain application of established psychological theory to LLM personalization. Methodologically standard (SFT+RL), but the proxy-driven personalization for non-verbal users is a valuable insight.
