📝 Paper Summary
Conversational personalization
User-profile based personalization
Linear memory
TAI is a teachable conversational system that learns user preferences from cold start by simulating diverse teaching dialogues to train models for action prediction and argument filling.
Core Problem
Users expect personalized assistants, but existing systems struggle to learn preferences from scratch (cold start) because they lack training data for how users naturally teach concepts and handle complex dialogue flows.
Why it matters:
- Commercial assistants (like Alexa/Siri) need to harmonize preferences across domains but often fail without explicit pre-configuration
- Scarcity of training data for 'teaching' interactions makes it difficult to bootstrap models that understand diverse user instructions
- Users need a natural way to iteratively clarify and update preferences rather than filling out static forms
Concrete Example:
When a user says 'I prefer big sky for weather update,' a standard agent might fail if it doesn't know 'big sky' is a provider. TAI proactively asks 'Which weather service do you mean?' or learns the mapping through a clarification loop, rather than crashing or ignoring the constraint.
Key Novelty
Teachable AI (TAI) with Seeker-Provider Simulation
- Introduces a seeker-provider interaction loop to simulate synthetic training data, modeling the user as a 'seeker' with a goal and the agent as a 'provider' using API transitions
- Implements a multi-turn action prediction loop that combines Named Entity Recognition (NER), Action Prediction (AP), and Argument Filling (AF) to manage state and store preferences
- Enables centralized knowledge storage that standardizes learned preferences into a persistent graph, allowing reuse across different domains (e.g., cuisine preferences used for restaurant booking)
Architecture
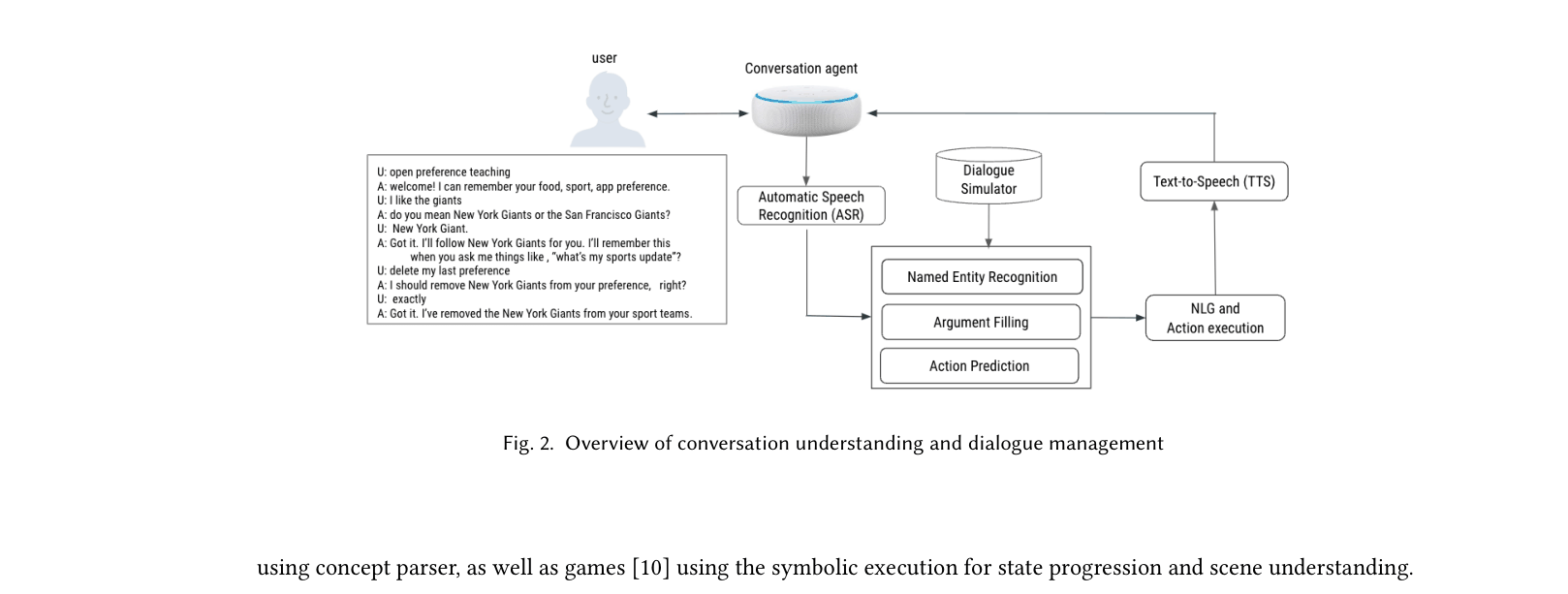
Overview of conversation understanding and dialogue management modules.
Evaluation Highlights
- Achieves 97.40% turn-level accuracy (all models correct) on in-sample evaluation data generated by the simulator
- Maintains 91.22% turn-level accuracy on out-of-sample data (collected via crowdsourcing to represent real-world variation)
- Adding N-gram catalog features improved NER accuracy from 94.48% to 96.79% on out-of-sample data
Breakthrough Assessment
7/10
Strong practical application of simulation to solve cold-start data scarcity in production systems. While the architecture is standard (BERT+LSTM), the end-to-end synthetic data loop and high production reliability are significant.