📝 Paper Summary
Alternative Architectures to Transformers
In-Context Learning
Long-Context Modeling
Memory Mosaics v2 scales networks of associative memories to 8B parameters by introducing adaptive bandwidth and hierarchical memory, significantly outperforming Transformers on new-task adaptation and long-context retrieval.
Core Problem
Transformers exhibit in-context learning capabilities that are poorly understood and often degrade when given many examples (shots), while their reliance on position encoding limits context extrapolation.
Why it matters:
- Transformers are opaque, making it difficult to understand how composition or disentanglement occurs during learning
- Standard attention mechanisms struggle to extrapolate to longer context lengths without extensive fine-tuning
- Current models often fail to effectively utilize large numbers of in-context examples, sometimes performing worse as more data is provided
Concrete Example:
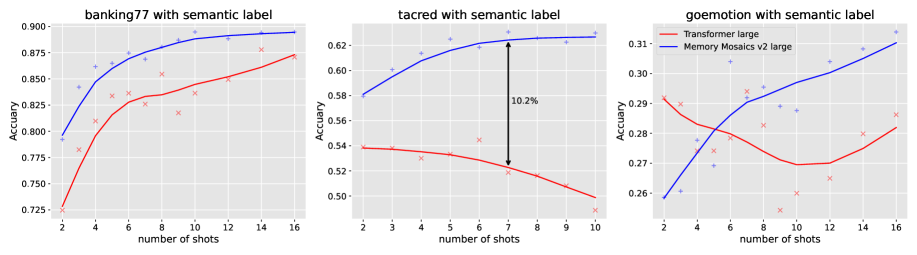
In a many-shot classification task (e.g., Banking77), a standard Transformer's accuracy actually decreases as the number of demonstration examples increases beyond a certain point. In contrast, Memory Mosaics v2 consistently improves accuracy with more shots.
Key Novelty
Memory Mosaics v2 (Hierarchical Associative Memory Network)
- Replaces Transformer attention with 'Associative Memories' that use symmetric kernels and adaptive bandwidths, treating context as a key-value store without explicit position encoding
- Separates memory into three distinct levels: Short-term (recent tokens), Long-term (distant tokens), and Persistent (global knowledge/FFN replacement) to handle different signal dependencies
- Introduces a gated time-variant key extractor that creates input-dependent keys, unlike the fixed averaging used in previous versions
Architecture
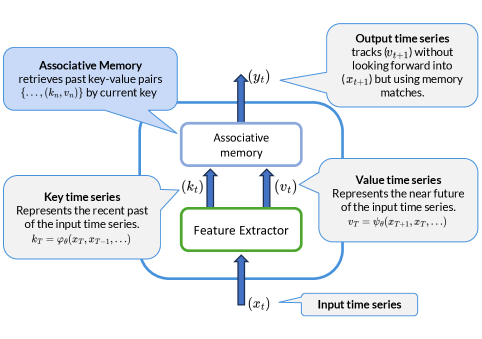
The architecture of Memory Mosaics v2 compared to v1, detailing the split into Short-term and Long-term associative memories.
Evaluation Highlights
- Outperforms Transformers by 12.3% to 14.8% on 'multi-unrelated-documents' QA tasks (Ruler benchmark) at 32k context length
- Achieves >10% higher accuracy than Transformers on in-context classification tasks (Banking77, Tacred) and avoids performance degradation with more shots
- Matches Transformer performance on 13 standard persistent-knowledge benchmarks (e.g., MMLU) while offering superior interpretability and context extrapolation
Breakthrough Assessment
8/10
Successfully scales a non-Transformer architecture to 8B parameters with competitive performance on standard tasks and superior performance on in-context/long-context tasks. Offers a transparent alternative to attention.