📊 Experiments & Results
Evaluation Setup
Agentic evaluation on synthetic scenarios requiring structured memory
Benchmarks:
- StructMemEval (Tree-structured) (Genealogy and corporate hierarchy graph maintenance) [New]
- StructMemEval (State tracking) (Tracking entity states (e.g., location) over time to answer validity questions) [New]
- StructMemEval (Counting) (Financial transaction logging and netting (calculating final debt)) [New]
Metrics:
- Exact Match (accuracy)
- LLM-as-a-judge score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| StructMemEval | Unique Scenarios | 0 | 73 | +73 |
| StructMemEval | Evaluation Questions | 0 | 544 | +544 |
Experiment Figures
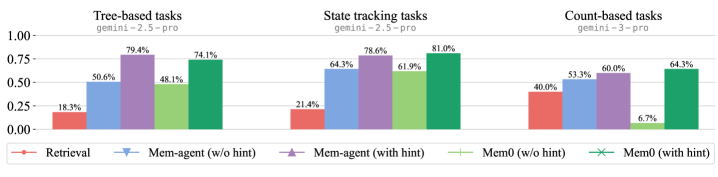
Comparison of Retrieval, Mem-agent, and Mem0 across Tree, Count, and State Tracking tasks, with and without hints
Main Takeaways
- Simple retrieval-augmented LLMs (RAG) struggle significantly with tasks requiring state tracking or global calculations (netting), often retrieving out-of-date information.
- Memory agents (Mem0, Mem-agent) perform well when explicitly prompted (hinted) on how to organize memory (e.g., 'keep a ledger'), effectively solving tasks that defeat RAG.
- A critical 'autonomy gap' exists: without explicit hints, memory agents often fail to recognize the need for a specific structure, performing much worse than their potential, suggesting LLMs lack training in applying algorithmic structures to their own memory.