📝 Paper Summary
Memory Efficient Models
Meta-learning
Constant Memory Attentive Neural Processes achieve memory efficiency and fast updates by using a specialized attention block with fixed latent queries that supports exact, incremental cross-attention updates.
Core Problem
State-of-the-art Neural Processes leverage expensive attention mechanisms (like Transformers) that scale linearly or quadratically with context size, making them too memory-intensive for low-resource devices.
Why it matters:
- High memory costs limit deployment on battery-powered edge devices (IoT, mobile robots) where energy efficiency is crucial.
- Existing methods require re-processing the entire context dataset from scratch when new data arrives, which is computationally wasteful.
- Current approaches struggle to scale to large context datasets due to $O(N^2)$ or $O(Nk)$ memory complexity.
Concrete Example:
When a robot receives 10 new observational data points, a standard Transformer Neural Process must re-compute attention over its entire history of thousands of points (scaling quadratically). CMANP updates its representation using only the 10 new points in constant memory, without accessing the full history.
Key Novelty
Constant Memory Attention Block (CMAB) with Exact Updates
- Uses a set of fixed, learnable latent vectors as queries in Cross Attention, decoupling the memory cost from the size of the input context dataset.
- Reformulates Cross Attention as a rolling average operation (using log-sum-exp), enabling the model to update attention weights with new data without re-processing old data.
- Ensures permutation invariance and stackability while maintaining constant memory complexity throughout the conditioning phase.
Architecture
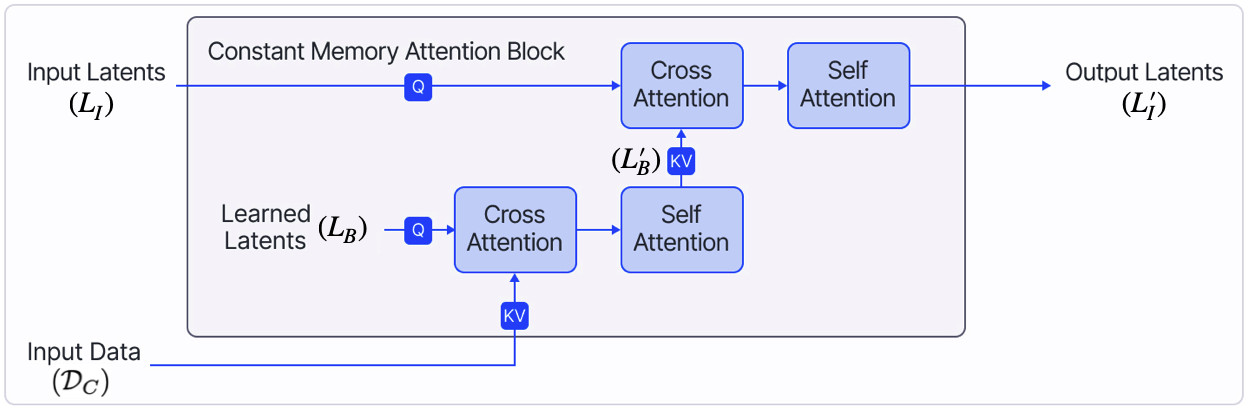
The Constant Memory Attention Block (CMAB) architecture.
Breakthrough Assessment
8/10
The theoretical contribution of an exact, constant-memory update for Cross Attention is significant for efficient meta-learning, directly addressing the primary bottleneck of attention-based Neural Processes.