📝 Paper Summary
Episodic Control
Reinforcement Learning
2M is a reinforcement learning agent that switches between fast episodic memory and slow parametric learning for action selection, sharing data between them to combine speed with asymptotic optimality.
Core Problem
Deep Reinforcement Learning (DRL) is sample-inefficient due to slow reward propagation and representation learning, while Episodic Memory (EM) learns quickly but struggles with generalization and stochasticity.
Why it matters:
- Current DRL methods require massive amounts of interaction data, making them impractical for real-world tasks where samples are expensive
- Pure episodic approaches (like MFEC) hit performance plateaus early because they lack the generalization capabilities of neural networks
- Existing hybrid methods mostly use memory to estimate training targets rather than for direct control, failing to fully exploit the speed of episodic action selection
Concrete Example:
In a simple grid world, an episodic agent quickly finds a path to a reward but gets stuck on a sub-optimal route because it lacks the look-ahead mechanism to correct itself. A standard RL agent eventually finds the optimal path but takes many more episodes to propagate the reward signal back to the start state.
Key Novelty
Dual-Memory Switching & Data Sharing
- Maintain two distinct decision-making systems: a fast non-parametric Episodic Control (EC) memory and a slow parametric Reinforcement Learning (RL) network
- Use a probabilistic schedule to select which memory controls the agent per episode, favoring EC early for speed and RL later for optimality
- Share all collected experience between systems: EC data trains the RL network (providing diverse samples), and RL data updates the EC memory (providing exploration)
Architecture
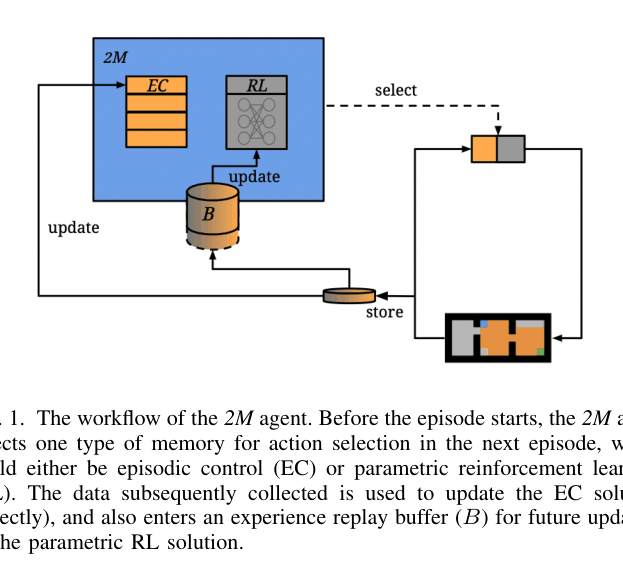
Workflow of the 2M agent illustrating the switching mechanism and data flow.
Evaluation Highlights
- Outperforms or matches baselines (DQN, MFEC, EMDQN) across 5 MinAtar games
- Data sharing increases Episodic Control return from ~3 to ~6 in ablation studies, proving RL helps EC escape local optima
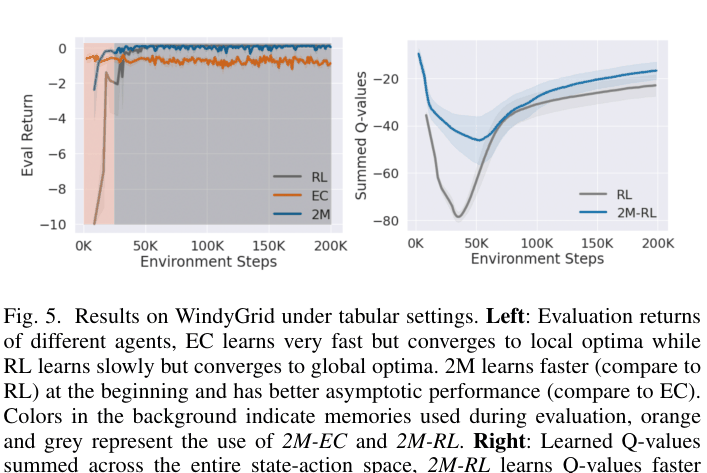
- Demonstrates faster initial learning than pure RL and better final convergence than pure Episodic Control
Breakthrough Assessment
7/10
Simple but effective framework combining two fundamental approaches. Strong empirical results on small benchmarks (MinAtar), but evaluation on larger suites (ALE) is missing.