📝 Paper Summary
Memory recall
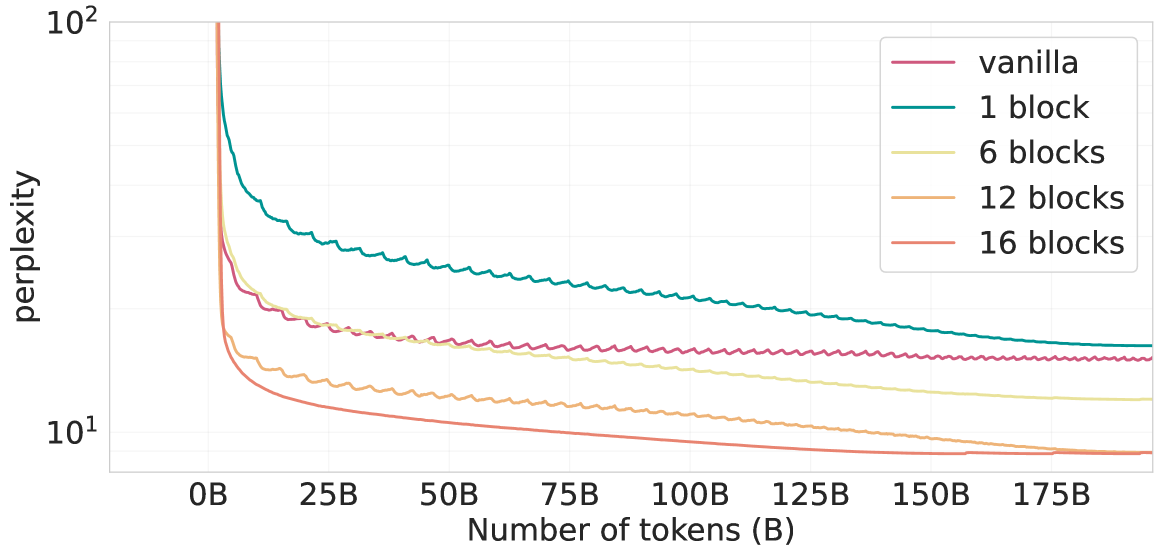
Linear memory
LM2 augments decoder-only Transformers with an explicit, gated memory bank that processes a parallel information flow to handle long-context reasoning without degrading general capabilities.
Core Problem
Standard Transformers and current memory-augmented models struggle with 'needle-in-a-haystack' reasoning over extremely long contexts, often degrading in performance as context grows or sacrificing general LLM capabilities.
Why it matters:
- Tasks like synthesizing facts scattered across 100k+ token documents remain unsolved by standard attention due to distraction by irrelevant data.
- Existing memory approaches often summarize history into static prompts, losing fidelity over long sequences (e.g., MemReasoner drops from 60.6 to 18.5 accuracy as context doubles).
- Specialized memory models typically compromise the general reasoning abilities of the base LLM, limiting their real-world utility.
Concrete Example:
In the BABILong benchmark, when a model must answer a question requiring facts scattered across a 16k+ token document, the baseline RMT model's performance drops significantly, while MemReasoner fails to integrate long-term information effectively.
Key Novelty
Dual-Stream Memory Transformer with Gated Updates
- Introduces a dedicated memory bank (matrix) alongside the standard attention flow, where memory slots are read/written via cross-attention with input tokens.
- Uses differentiable gating (Input, Forget, Output) analogous to LSTMs but applied to the memory bank to dynamically update or preserve long-term information.
- Maintains two distinct information flows—standard Transformer embeddings and memory embeddings—merging them via a learned gate only when necessary to preserve general performance.
Architecture
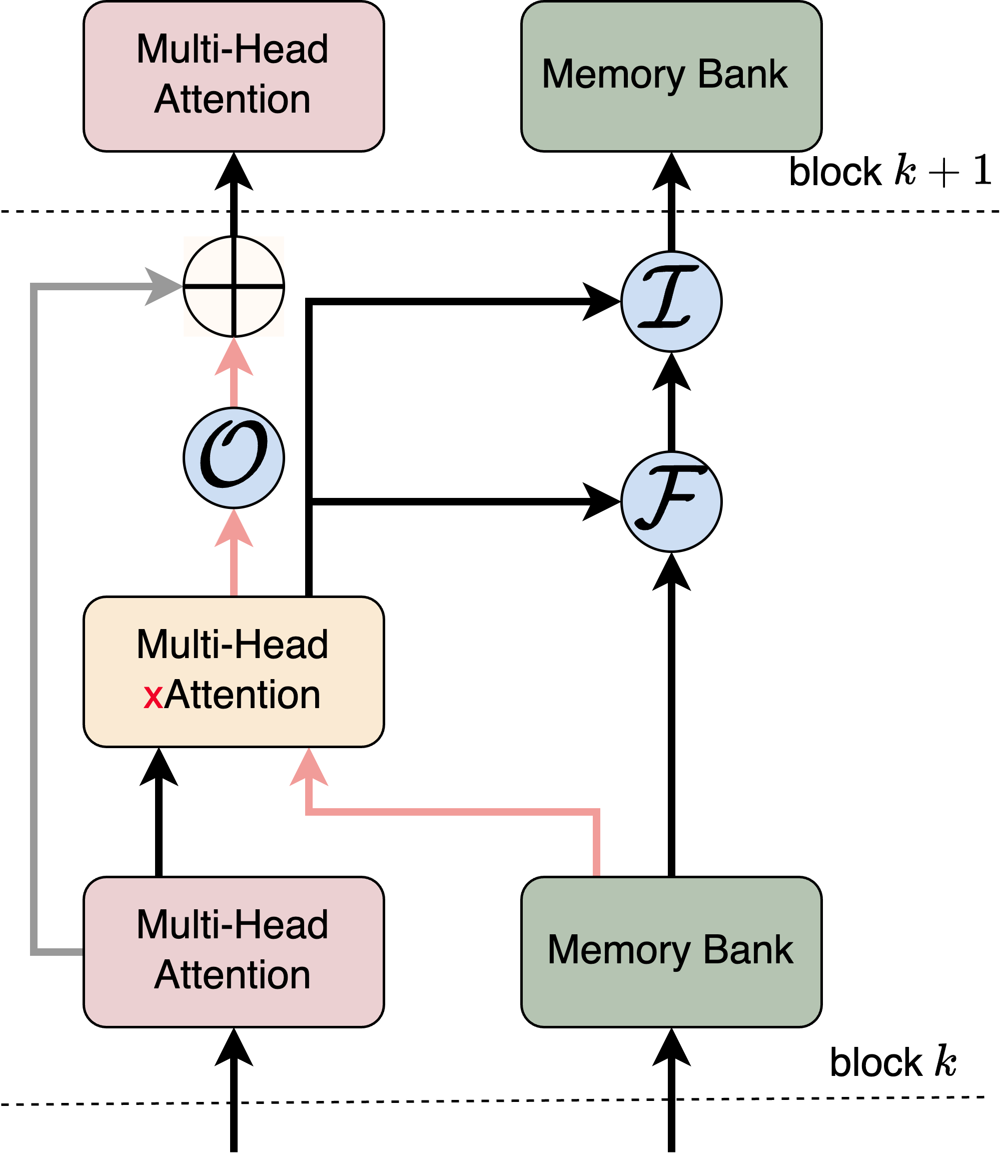
The overall architecture of LM2, highlighting the dual information flow: the standard Attention Information Flow and the new Memory Information Flow.
Evaluation Highlights
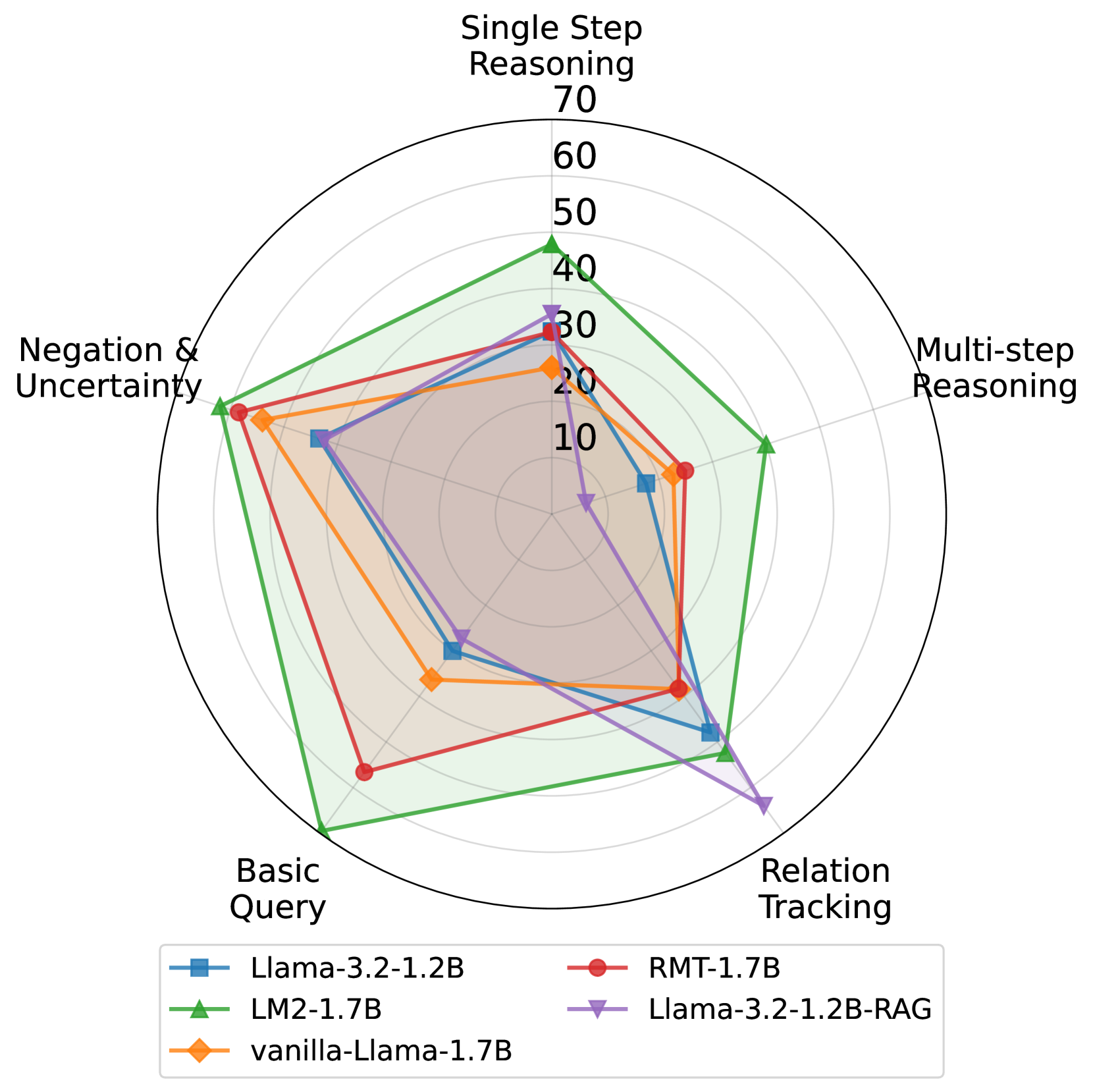
- Outperforms memory-augmented baseline RMT by 37.1% on average across BABILong tasks, showing superior long-context handling.
- Surpasses the vanilla Llama-3.2 baseline by 86.3% on average on BABILong, validating the benefit of the explicit memory module.
- Achieves a 5.0% improvement on the MMLU benchmark over the vanilla model, proving that memory augmentation enhances rather than harms general reasoning capabilities.
Breakthrough Assessment
8/10
Significantly outperforms RMT and standard Llama on rigorous long-context benchmarks while improving general MMLU performance. The dual-flow architecture offers a robust solution to the stability vs. memory trade-off.