📝 Paper Summary
Memory management in Deep Learning
Tensor Rematerialization (Gradient Checkpointing)
Coop co-optimizes tensor rematerialization and memory allocation by using a sliding window to evict contiguous memory blocks and allocating tensors strategically to minimize fragmentation.
Core Problem
Existing rematerialization methods assume all free memory is identical, leading to the eviction of discontiguous tensors that create fragmentation rather than usable contiguous blocks.
Why it matters:
- Fragmentation prevents training large models even when total free memory is theoretically sufficient
- Inefficient eviction strategies increase computational overhead by recomputing tensors that didn't help allocate the new object
- Current heuristics penalize sequential evictions, inadvertently worsening fragmentation since sequential tensors are often adjacent
Concrete Example:
In a CNN, DTR might evict two small discontiguous activation tensors (x0, x2) to free 100MB total. Because the holes are separated by x1, the allocator cannot fit a new 100MB tensor, forcing DTR to evict x1 as well, wasting compute.
Key Novelty
Co-optimization of Tensor Allocation and Rematerialization (Coop)
- Sliding Window Eviction: Instead of picking individual tensors, search for a contiguous window of tensors to evict that satisfies the size requirement with minimal recompute cost
- Cheap Tensor Partitioning: Allocator groups tensors by compute cost (cheap vs. expensive) at opposite ends of memory to create large, low-cost contiguous regions for potential eviction
- Recomputable In-Place: Allows in-place mutations on unevictable tensors (like parameters) without copying, preserving the contiguous memory layout
Architecture
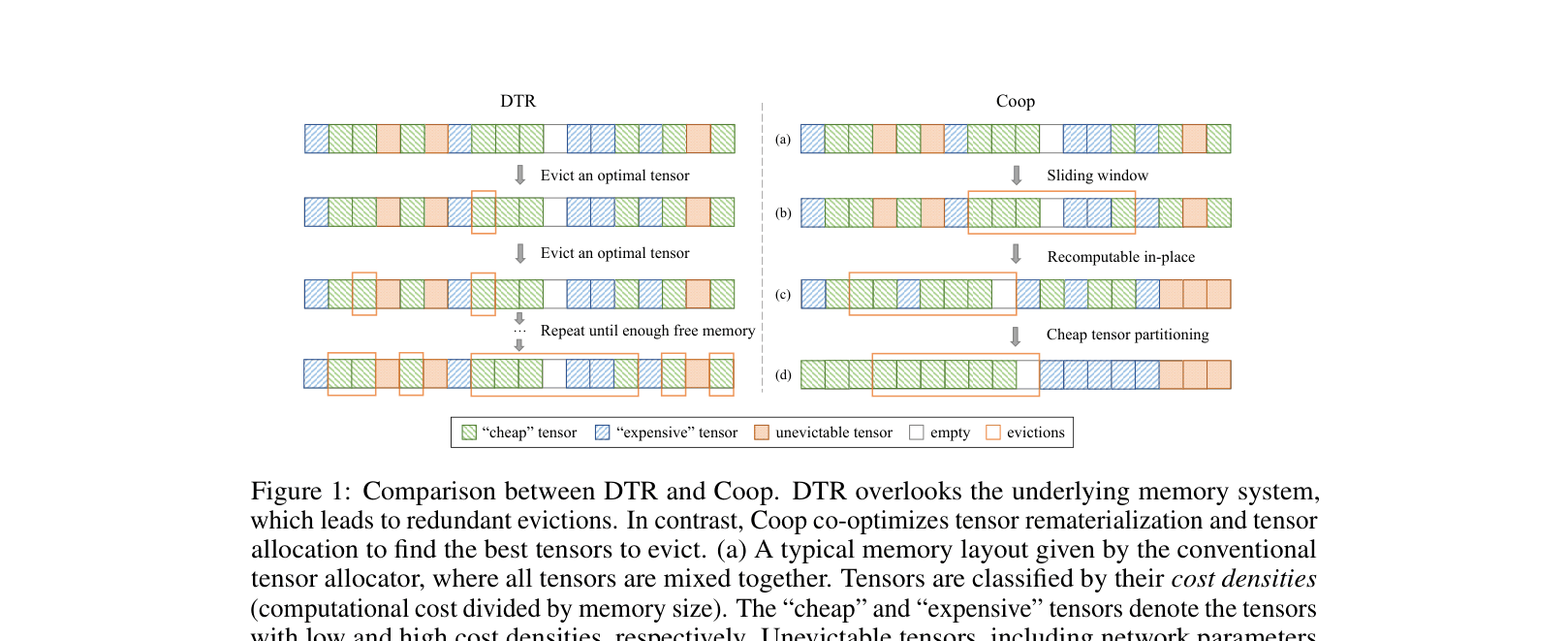
Contrast between DTR's fragmented eviction and Coop's structured approach. Shows memory layout with 'cheap', 'expensive', and 'unevictable' tensors.
Evaluation Highlights
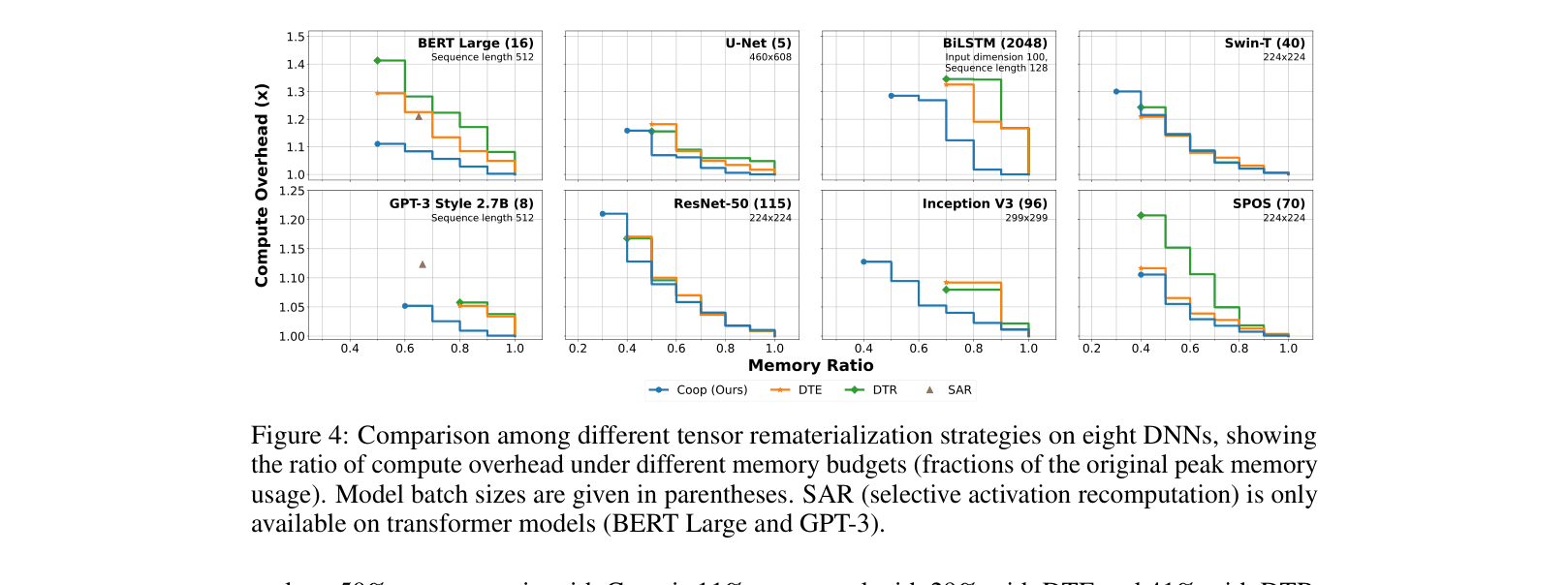
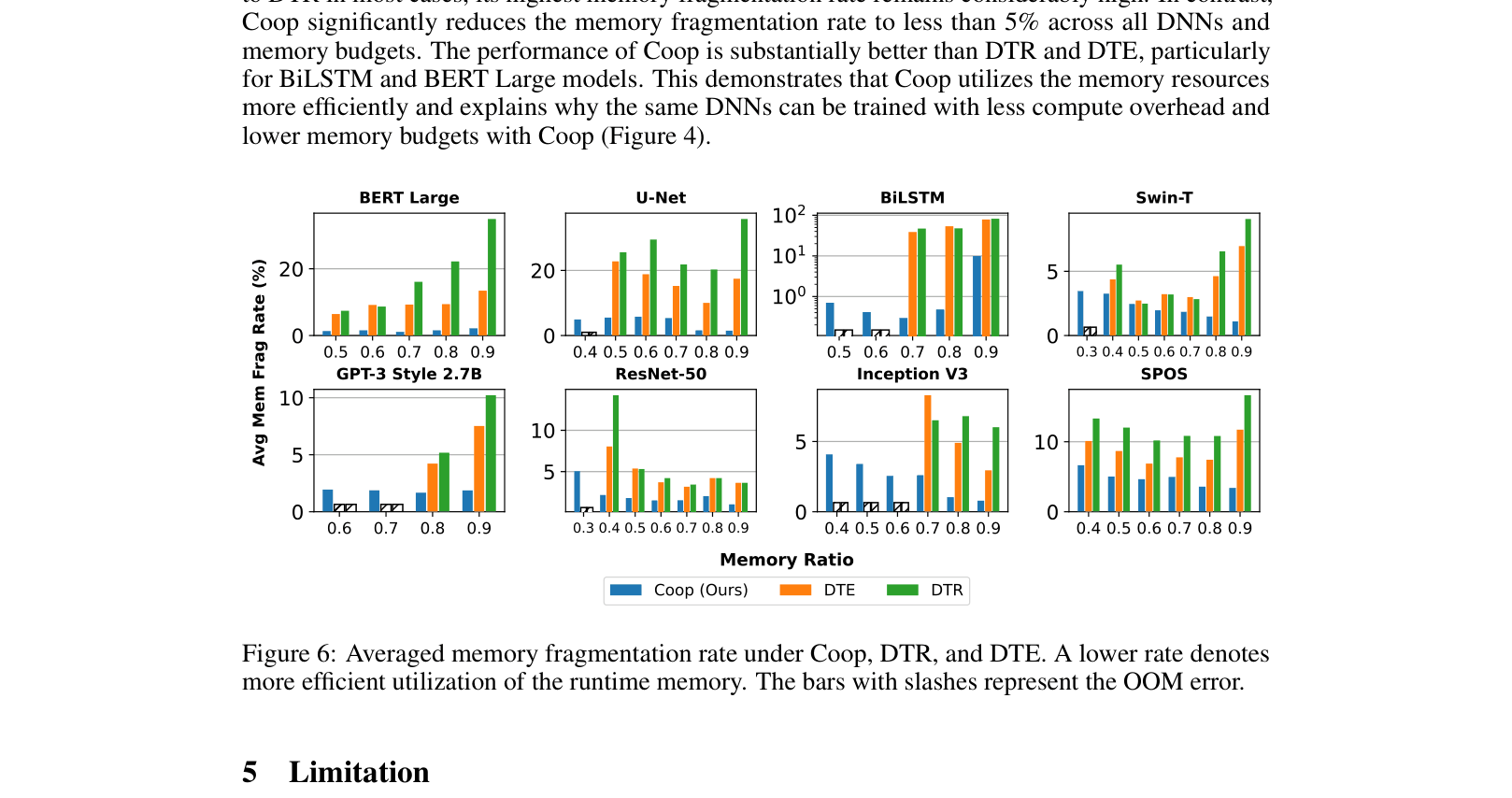
- Reduces memory fragmentation rate to <5% across 8 representative DNNs (e.g., GPT-3 2.7B, Swin-T), compared to much higher rates in baselines
- Achieves up to 2x memory savings compared to standard training and outperforms DTR/DTE in minimum memory budget
- Lowers compute overhead significantly; e.g., 11% overhead for BERT Large at 50% memory ratio vs. 41% for DTR
Breakthrough Assessment
8/10
Strong conceptual advance by linking memory layout to checkpointing. Addresses a fundamental inefficiency in prior work (fragmentation) with a practical, unified system solution.