📝 Paper Summary
Memory internalization
Domain adaptation
Memory Decoder is a small, standalone transformer trained to mimic external retrieval distributions, which can then be interpolated with any base LLM for instant, efficient domain adaptation without fine-tuning the base model.
Core Problem
Adapting LLMs to specialized domains currently requires a trade-off: either expensive full-parameter retraining (DAPT) that risks forgetting, or high-latency retrieval (RAG) that searches massive external datastores at inference time.
Why it matters:
- Full retraining (DAPT) is computationally prohibitive for large models and must be repeated for every new model architecture, wasting resources.
- Retrieval-Augmented Generation (RAG) adds significant inference latency due to nearest-neighbor searches and long context processing.
- Existing methods lack portability; domain knowledge learned by one model cannot be easily transferred to another without retraining.
Concrete Example:
When adapting a general LLM to the biomedical domain, DAPT requires retraining billions of parameters, while RAG must search a massive clinical database for every token generation. Memory Decoder avoids both by carrying the database 'internalized' in a small plugin model.
Key Novelty
Distilling Non-Parametric Retrieval into a Parametric Decoder
- Trains a small decoder-only model to predict the output probability distribution of a k-nearest neighbor (kNN) retriever, effectively compressing a large external datastore into model weights.
- Enables 'plug-and-play' adaptation: the trained Memory Decoder runs in parallel with *any* frozen LLM (sharing the same tokenizer) and their outputs are linearly interpolated, instantly adapting the LLM to the domain.
Architecture
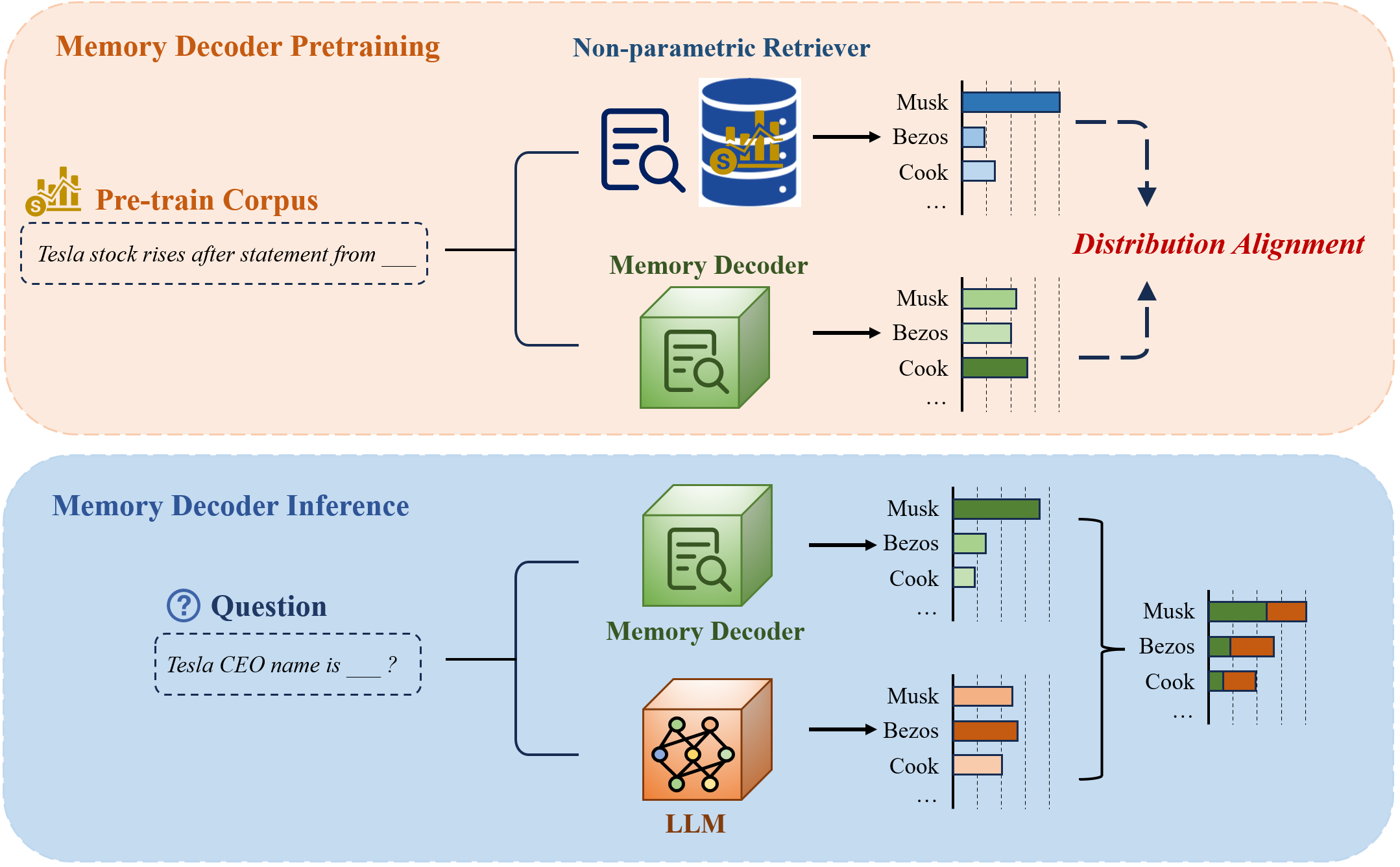
The dual-stage process of Memory Decoder: (1) Pre-training phase where the decoder learns to mimic kNN distributions from a datastore, and (2) Inference phase where the trained decoder runs in parallel with a frozen PLM.
Evaluation Highlights
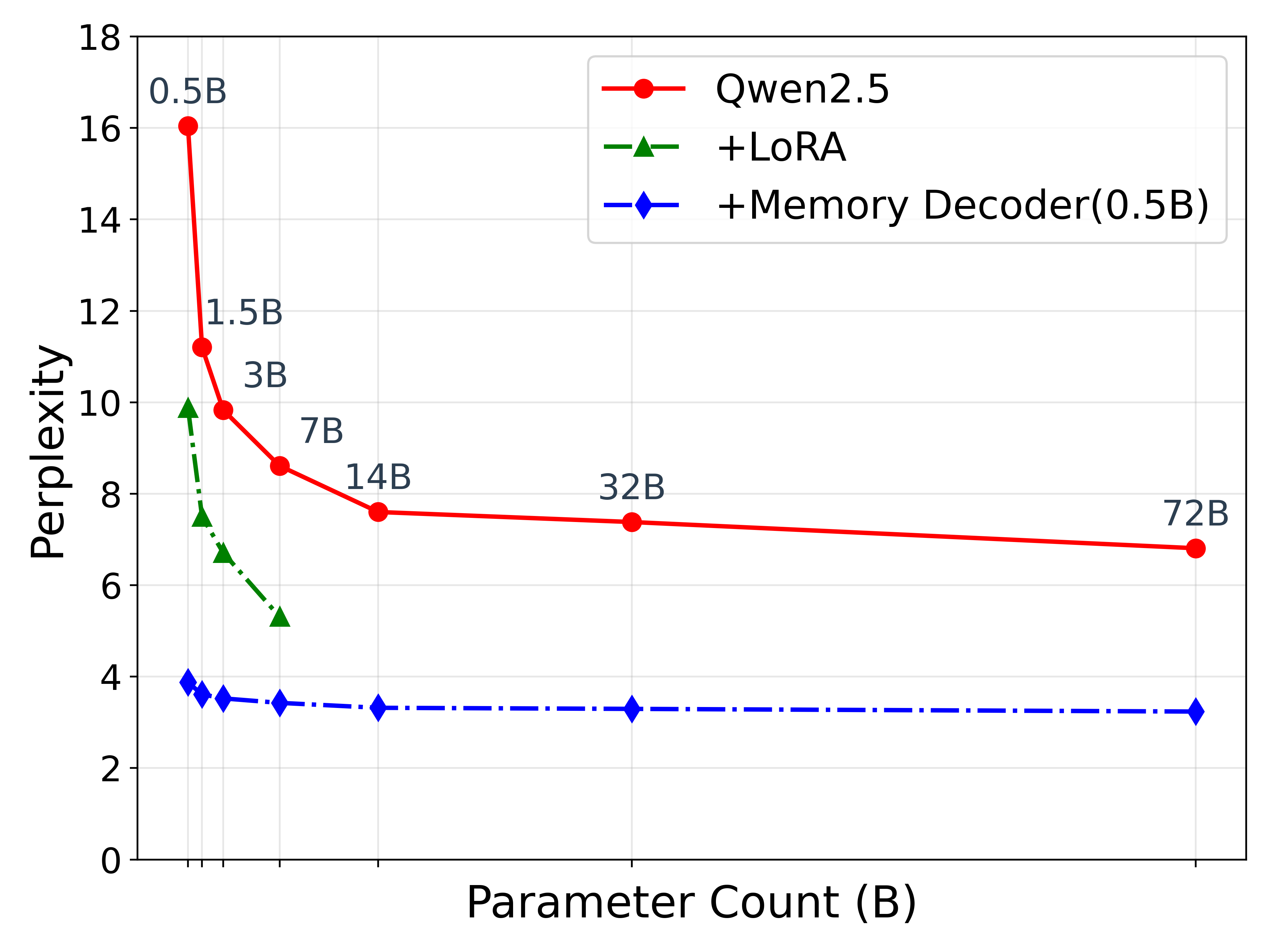
- Reduces perplexity by an average of 6.17 points across biomedical, financial, and legal domains compared to base models.
- A single 0.5B parameter Memory Decoder successfully adapts the entire Qwen2.5 family (ranging from 0.5B to 72B parameters) to the finance domain.
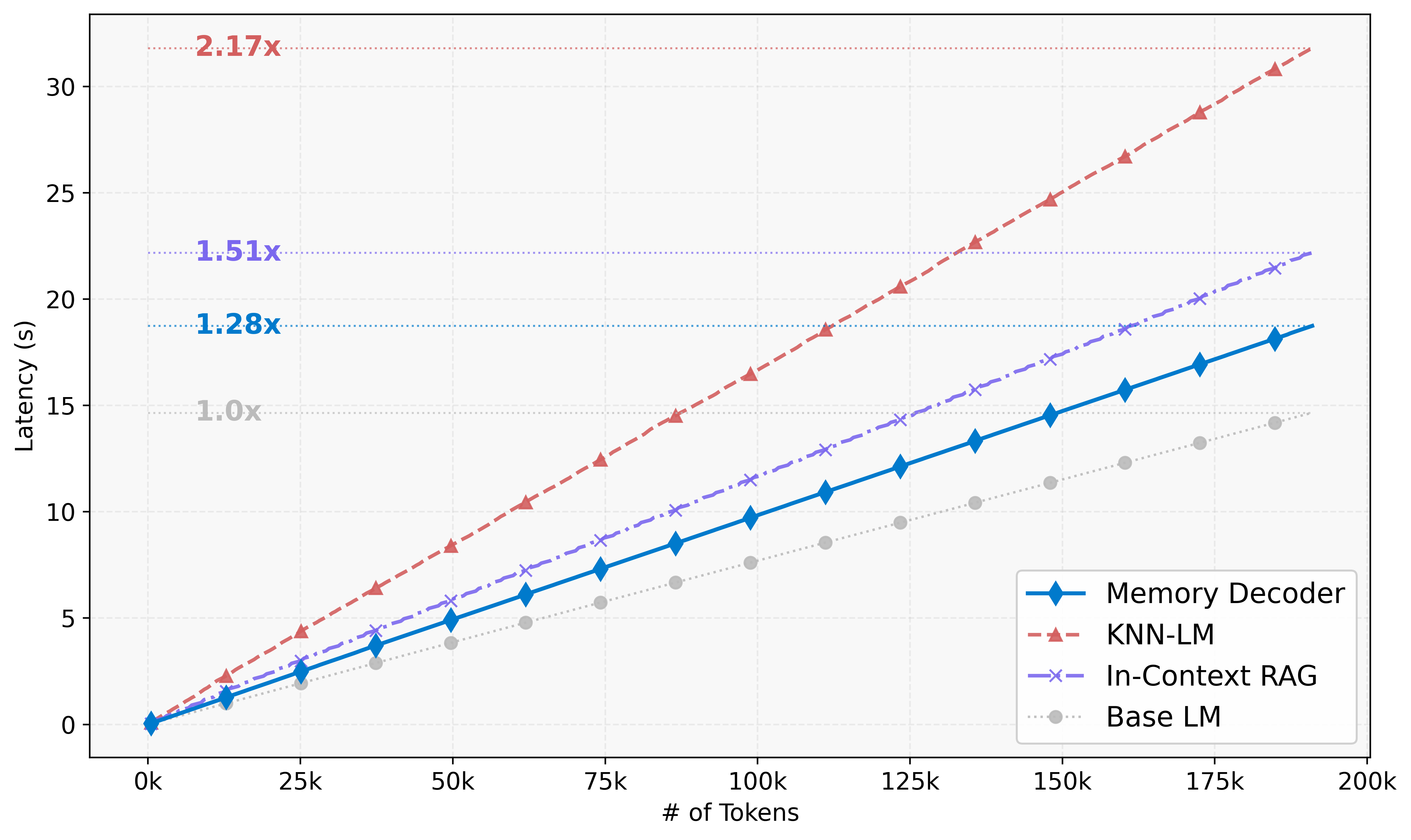
- Achieves 1.28x inference latency overhead, significantly faster than kNN-LM (2.17x) and In-Context RAG (1.51x).
Breakthrough Assessment
8/10
Offers a genuinely new paradigm for domain adaptation—portability. The ability to train a memory module once and plug it into models ranging from 0.5B to 72B without retraining the base model is a significant efficiency breakthrough.