📝 Paper Summary
Memory organization
Memory recall
PerLTQA is a comprehensive dataset and evaluation framework that integrates both semantic (profiles, relationships) and episodic (events, dialogues) memories to benchmark LLM capabilities in personalized long-term memory question answering.
Core Problem
Existing QA and dialogue datasets typically focus on either world knowledge (semantic) or session history (episodic) in isolation, lacking a unified resource that combines personal profiles, social relationships, events, and dialogues for long-term memory evaluation.
Why it matters:
- Personalized assistants require integrated access to both static facts (semantic) and dynamic history (episodic) to generate human-like responses
- Current benchmarks do not adequately test an LLM's ability to distinguish between and synthesize different memory types (e.g., retrieving a friend's name vs. recalling a specific shared event)
- Research gaps exist in explicit annotations for social relationships and event-based episodic memory within a single QA framework
Concrete Example:
A user asks, 'Who did I go hiking with last year?' To answer, the system must retrieve the specific event (episodic) and link it to the person involved (semantic relationship), whereas current systems might only look at recent dialogue history or generic facts.
Key Novelty
Unified Semantic-Episodic Memory Benchmark & Pipeline
- Constructs a semi-synthetic dataset (PerLTQA) comprising 141 characters with detailed profiles, social webs, life events, and historical dialogues using an in-context generation approach
- Proposes a three-stage evaluation framework: Memory Classification (identify memory type needed), Memory Retrieval (re-rank based on type), and Memory Synthesis (generate answer)
- Introduces 'memory anchors'—annotated key text segments in answers—to precisely evaluate whether the model used the correct retrieved memory during synthesis
Architecture
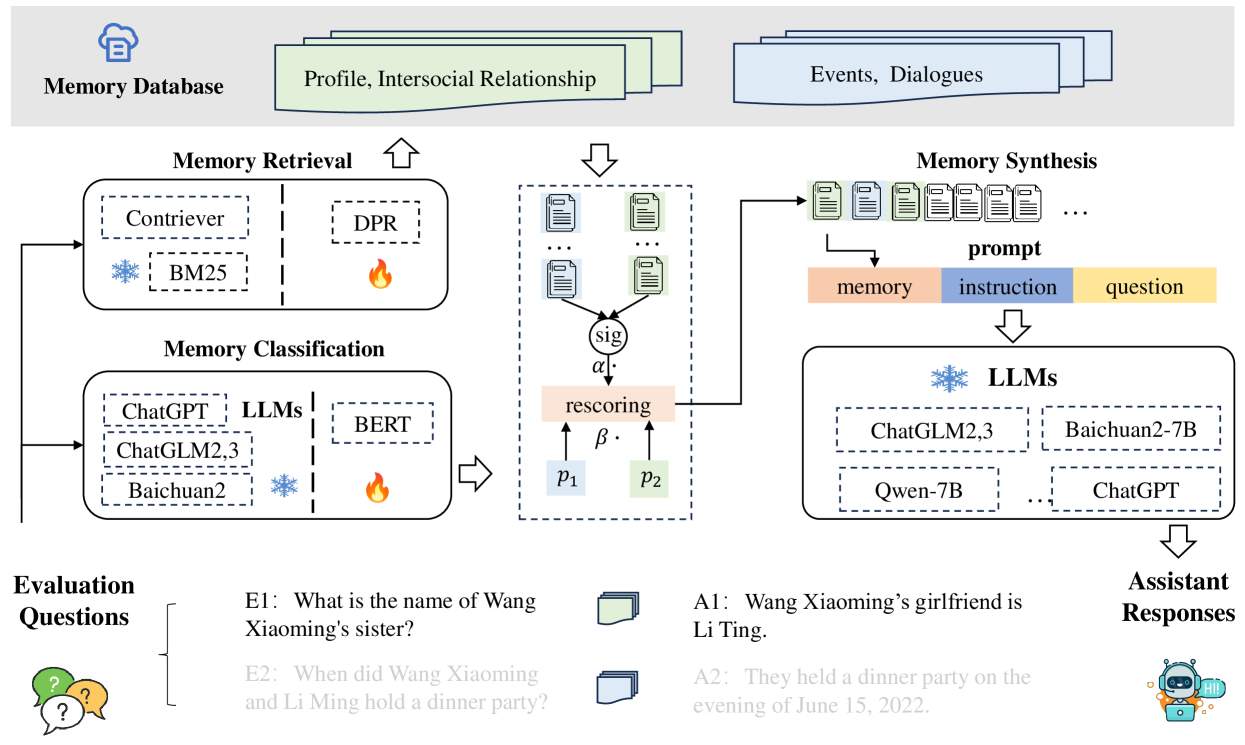
The proposed framework for memory integration in QA, showing the flow from question to answer via classification, retrieval, and synthesis.
Evaluation Highlights
- BERT-based classifiers achieve significantly higher accuracy in memory type classification compared to LLMs, outperforming ChatGLM3 and ChatGPT
- Memory classification assists retrieval: Using classification probabilities to re-rank memories improves retrieval performance
- Retrieval accuracy is critical: LLMs show varied proficiency in synthesis even when provided with perfect memories, highlighting the need for better integration capabilities
Breakthrough Assessment
7/10
Provides a much-needed comprehensive dataset bridging semantic and episodic memory for personalization. While the method (pipeline) is standard, the data resource and granular annotation (memory anchors) are significant contributions.