📝 Paper Summary
Interpretability of Attention Mechanisms
Transformer Alternatives
Associative Memory Networks
Memory Mosaics replace opaque self-attention with transparent associative memory layers that naturally decompose prediction tasks into independent sub-tasks through a process called predictive disentanglement.
Core Problem
Standard Transformers possess powerful compositional capabilities, but their internal mechanisms are notoriously opaque and hard to decipher, making it difficult to understand how they decompose tasks.
Why it matters:
- The lack of interpretability in Transformers hinders safety analysis and debugging of large language models
- Understanding how models decompose complex tasks is crucial for improving generalization and robustness
- Current attempts to interpret attention (e.g., induction heads) often require complex post-hoc analysis rather than being inherent to the architecture
Concrete Example:
In a toy problem predicting the positions of three orbiting moons, a standard model might try to memorize the global state of the entire system (requiring a context length equal to the least common multiple of all periods). In contrast, Memory Mosaics naturally split the task, with different heads tracking each moon independently, requiring much shorter context lengths.
Key Novelty
Predictive Disentanglement via Associative Memories
- Replaces self-attention with associative memory units where keys are computed from past context but values are explicitly trained to predict the *near future* (e.g., next token)
- Interprets training as a meta-learning process that assigns distinct prediction sub-tasks to different memory heads, forcing them to specialize
- Demonstrates that this architecture naturally disentangles complex signals (like superimposed moon orbits) into independent components without explicit supervision
Architecture
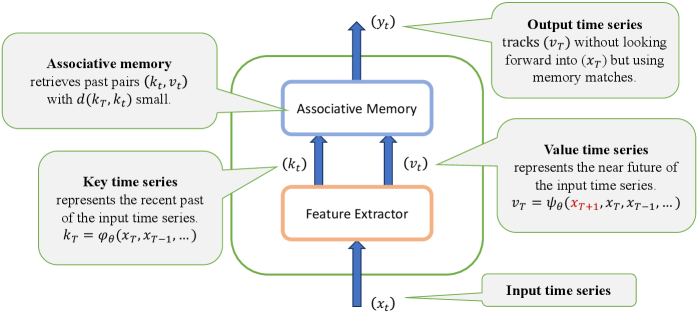
Diagram of a single Memory Unit acting as a predictor. It shows the timeline of inputs x_t.
Evaluation Highlights
- Matches the perplexity of a standard decoding Transformer (20.5 vs 20.5) on the WikiText-103 language modeling benchmark
- Outperforms standard Transformers on out-of-distribution (O.O.D.) in-context learning tasks, showing better adaptation to new patterns
- Successfully disentangles a 3-body orbit prediction task using a tiny network (54 parameters), requiring significantly shorter context history than a monolithic predictor
Breakthrough Assessment
7/10
Offers a compelling theoretical and architectural alternative to standard attention that enhances interpretability without sacrificing performance on medium-scale tasks. The concept of 'predictive disentanglement' is a significant conceptual contribution.