📝 Paper Summary
Memory organization
Memory recall
The paper introduces two diagnostic benchmarks to demonstrate that standard RL memory architectures (like Transformers) excel at retention but fail at selective rewriting, whereas simple recurrent models with explicit forgetting gates perform better.
Core Problem
Existing memory-augmented RL agents and benchmarks focus primarily on information retention (keeping data), neglecting the critical ability of rewriting (selectively discarding outdated data and integrating new evidence).
Why it matters:
- Real-world environments are dynamic; acting on obsolete information (e.g., old navigation cues) leads to failure.
- Current benchmarks typically reward holding a single cue until the end of an episode, failing to penalize agents that cannot discard irrelevant history.
- Transformer-based agents often lack explicit forgetting mechanisms, causing them to fail in tasks requiring continual updates despite their popularity.
Concrete Example:
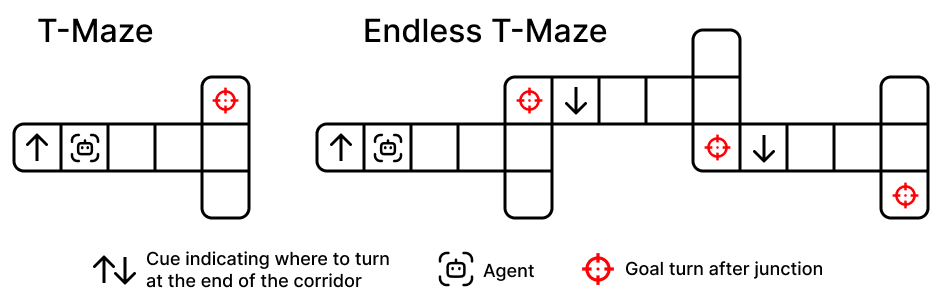
In the 'Endless T-Maze', an agent receives a cue (e.g., 'turn left') at the start of a corridor. After the turn, a new cue appears (e.g., 'turn right'). A retention-focused agent keeps the old 'left' cue and fails the next junction, whereas a rewriting-capable agent discards 'left' and stores 'right'.
Key Novelty
Diagnostic Benchmarks for Memory Rewriting
- Introduces 'Endless T-Maze' and 'Color-Cubes': environments specifically designed to force agents to overwrite old memory states with new observations to succeed.
- Endless T-Maze requires overwriting navigation instructions at every corridor junction, preventing success via static retention.
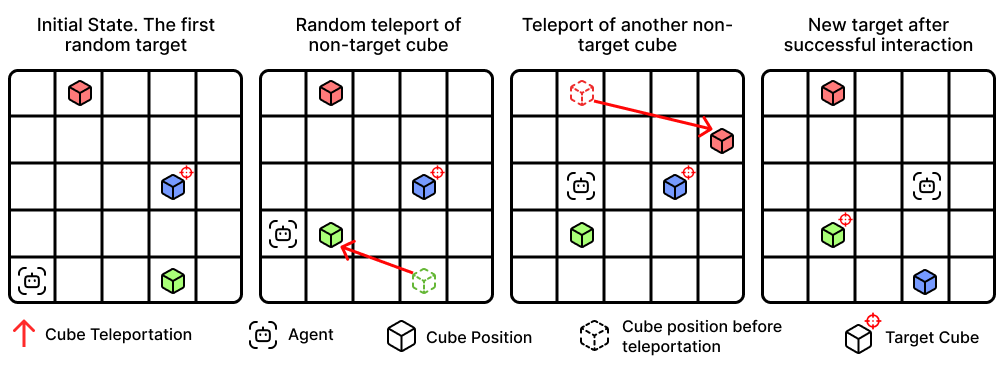
- Color-Cubes requires tracking object locations that stochastically teleport, forcing agents to detect inconsistencies between memory and observation and update their internal map.
Architecture
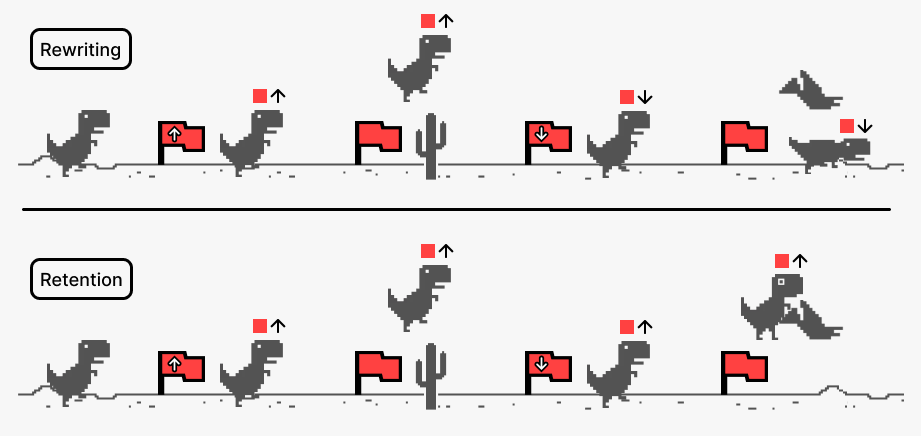
A conceptual comparison between Memory Rewriting and Retention-Only strategies.
Evaluation Highlights
- Recurrent models (PPO-LSTM) outperform Transformer-based agents (GTrXL) on the Endless T-Maze, with LSTM maintaining high rewards while GTrXL performance collapses as corridor length increases.
- In Color-Cubes, LSTM agents achieve significantly higher success rates than GTrXL, which struggles to update memory after object teleportation.
- Structured memory (SHM) fails to generalize in rewriting tasks, performing worse than standard LSTM baselines.
Breakthrough Assessment
7/10
Identifies a fundamental blind spot in current RL memory research (rewriting vs. retention) and provides targeted benchmarks, though it primarily evaluates existing architectures rather than proposing a novel model.