📝 Paper Summary
Self-evolving Agentic reasoning
Linear memory
UMEM improves agent self-evolution by jointly training a memory optimizer to extract and manage insights using a neighborhood-based reward that ensures memories generalize to semantically similar tasks.
Core Problem
Existing self-evolving agents optimize memory management (storage/retrieval) but treat memory extraction as a static process, leading to the accumulation of instance-specific noise that fails to generalize.
Why it matters:
- Accumulation of instance-specific noise causes progressive memory pollution, degrading performance over long interactions
- Management misalignment occurs when extracted memories do not fit the management policy, rendering even optimal retrieval strategies ineffective
- Prior works like MemRL and EvolveR fail to model cross-task generalization, resulting in agents that memorize shortcuts rather than principles
Concrete Example:
In a reasoning task, a static extractor might memorize specific numbers from a math problem (a shortcut). When a similar problem with different numbers appears, the agent retrieves this specific, irrelevant detail, leading to failure, whereas UMEM extracts the underlying formula.
Key Novelty
Unified Memory Extraction and Management (UMEM)
- Jointly optimizes the creation (extraction) and storage (management) of memories using a trainable 'Mem-Optimizer' rather than static prompts
- Introduces Semantic Neighborhood Modeling: evaluates memory quality not just on the current query, but on a cluster of similar queries to enforce generalization
- Uses a Marginal Utility Reward that calculates the net benefit (success gain + efficiency) of a memory update across the semantic neighborhood
Architecture
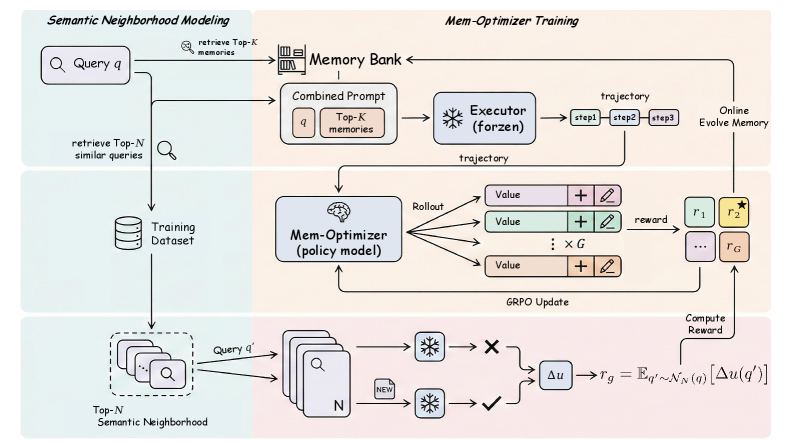
The UMEM framework workflow, illustrating the interaction between the frozen Agent Executor and the trainable Mem-Optimizer.
Evaluation Highlights
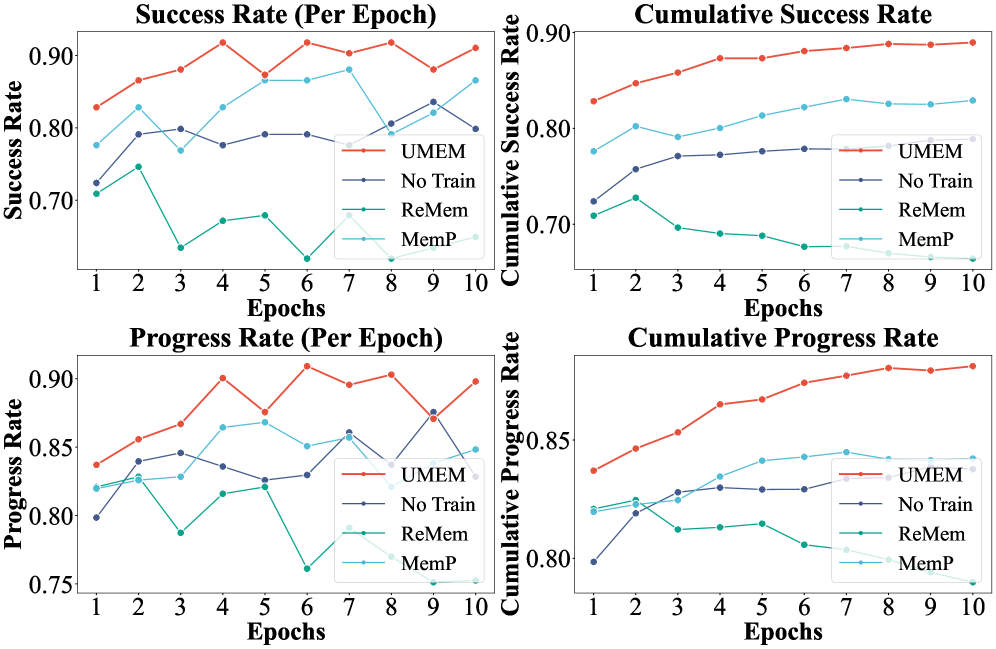
- Achieves 82.84% Success Rate on ALFWorld using UMEM-Qwen3-4B with GPT-5.1 as executor, outperforming baselines
- Demonstrates robust scaling: removing Semantic Neighborhood Modeling degrades AIME performance by 10.0 points (51.67 to 41.67) for GPT-5.1
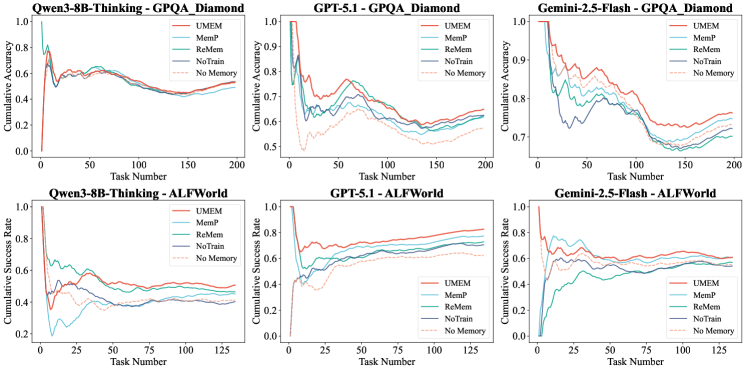
- Maintains monotonic performance growth during continuous evolution, avoiding the degradation seen in baselines like ReMem which optimize management in isolation
Breakthrough Assessment
8/10
Significant methodological shift from static to optimized memory extraction. Strong empirical gains on future-looking benchmarks (ALFWorld, AIME) and validation of the 'joint optimization' hypothesis.