📝 Paper Summary
Memory internalization
Sparse memory QA
Retrieval
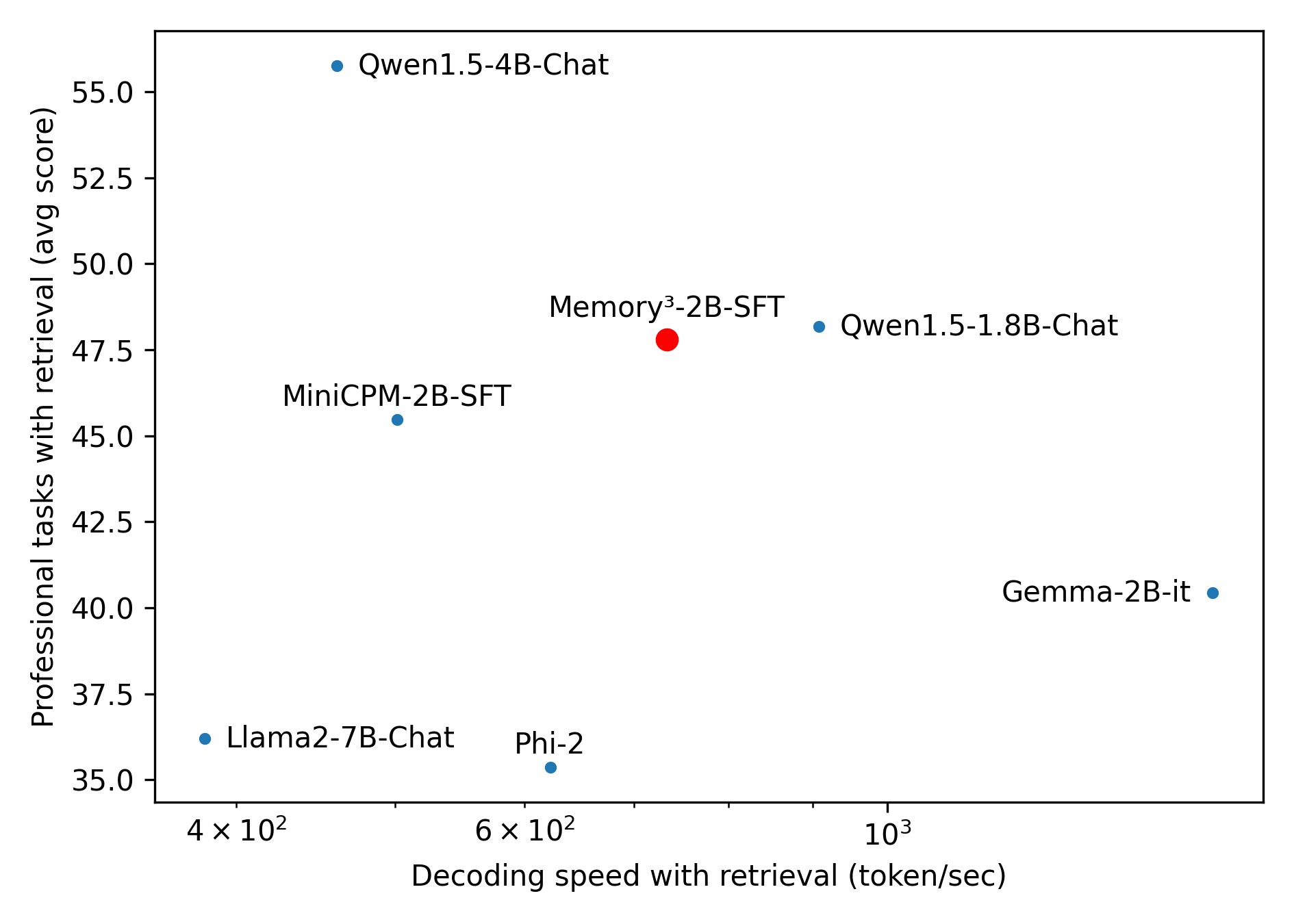
Memory3 introduces explicit memory—sparse attention key-values retrieved during inference—to externalize knowledge from model parameters, enabling smaller models to outperform larger ones with higher speed and lower cost.
Core Problem
LLMs suffer from high training/inference costs due to scaling laws and 'knowledge traversal', where the entire massive parameter set is activated to access small pieces of specific knowledge.
Why it matters:
- Current LLMs have extremely low knowledge efficiency (estimated around 10^-5), wastefully invoking all parameters for every token generation
- Storing all knowledge in implicit memory (parameters) forces models to be massive, increasing training data requirements and energy consumption
- Standard RAG approaches rely on heavy backbones and don't solve the knowledge traversal issue of the underlying model
Concrete Example:
When a human writes a word, they don't recall every book they've ever read; however, an LLM activates all its parameters (its full 'brain') for every token. This is like forcing knowledge into muscle memory (implicit) rather than just recalling a book (explicit).
Key Novelty
Externalizing knowledge into 'Explicit Memory' (sparse attention key-values)
- Treats knowledge storage as a hierarchy: RAG (text) → Explicit Memory (sparse KV pairs) → Implicit Memory (parameters), optimizing for read/write costs
- Converts text data into sparse key-value pairs off-line, which are then retrieved and injected directly into the model's self-attention layers during inference
- Uses a two-stage pretraining scheme: first training the model to use memory (Auto-Encoding), then training it to generate text (Auto-Regressive)
Architecture
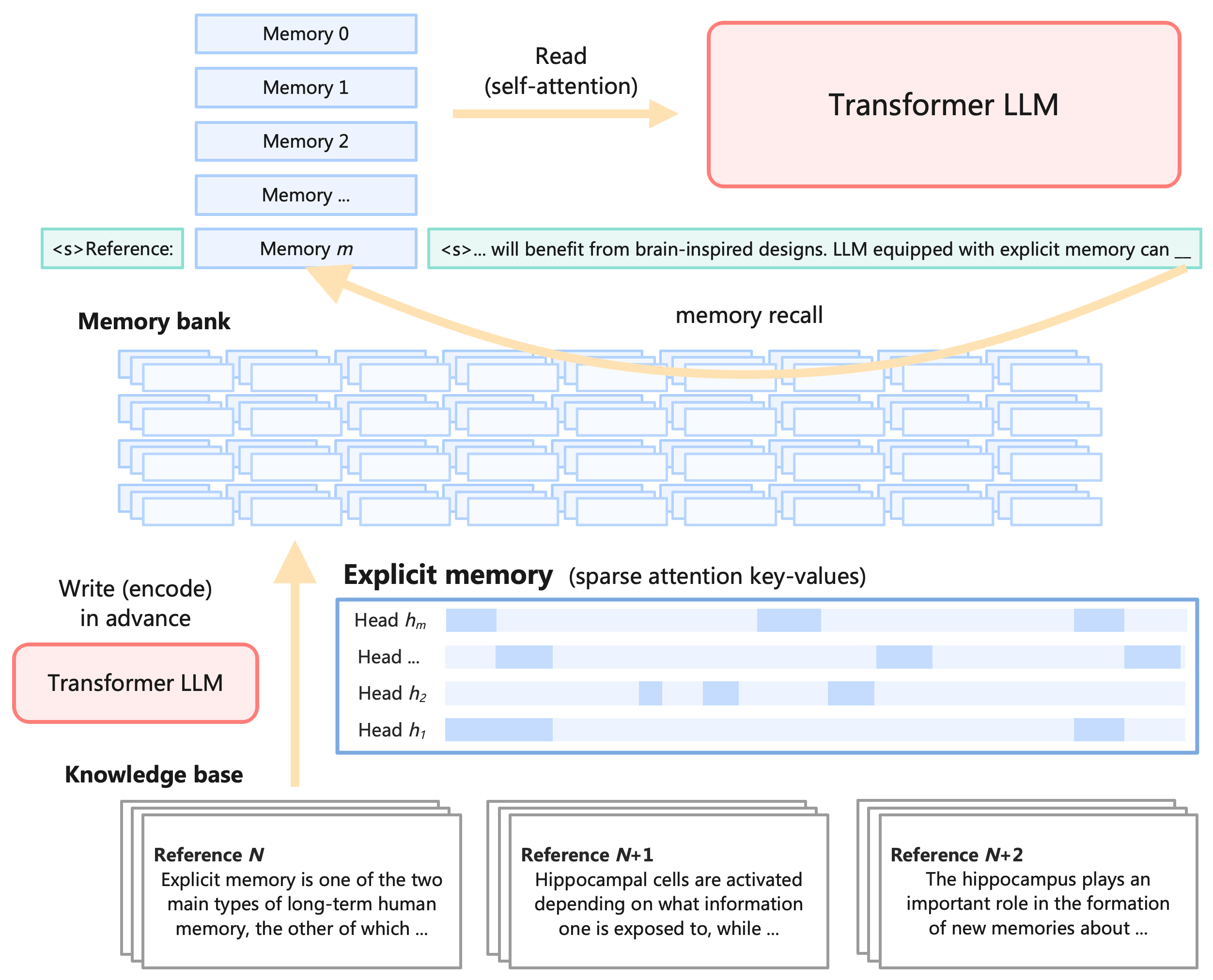
The workflow of Memory3, contrasting it with RAG and Parametric models. It shows the offline conversion of text to Explicit Memory and the online retrieval process.
Evaluation Highlights
- Memory3-2.4B outperforms the larger Baichuan2-7B-Base on the C-Eval benchmark (56.0 vs 54.0) despite having ~3x fewer parameters
- Achieves 1.66x higher decoding speed compared to a RAG baseline (Baichuan2-7B + Faiss retrieval)
- Reduces hallucination rate significantly in professional domains (e.g., medical), achieving 70.8% accuracy on unrecalled medical questions vs. 32.0% for the baseline
Breakthrough Assessment
8/10
Proposes a fundamental architectural shift by externalizing parameters into retrievable KV memory. The 2.4B model beating 7B baselines validates the efficiency of this 'third form' of memory.