📝 Paper Summary
Memory internalization
Memory recall
Causal language models fail to retain sufficient input information for accurate memory formation, necessitating autoencoder-based memory models trained with combined causal and reconstruction objectives.
Core Problem
Language models trained solely on next-token prediction do not store sufficient input information in their embeddings to allow for accurate input reconstruction or arbitrary information access.
Why it matters:
- Current memory models underperform full-context transformers because they cannot access arbitrary information from compressed embeddings
- Substituting memory embeddings for token sequences offers massive efficiency gains (lower latency, smaller KV cache), but only if the memories are accurate
- Next-token prediction is a non-invertible objective, making it theoretically ill-suited for high-fidelity memory formation
Concrete Example:
Retrieving a specific item from a list stored in a single embedding requires near-lossless compression. A standard causal model embedding often fails this, leading to poor performance in single-embedding retrieval compared to multi-embedding search.
Key Novelty
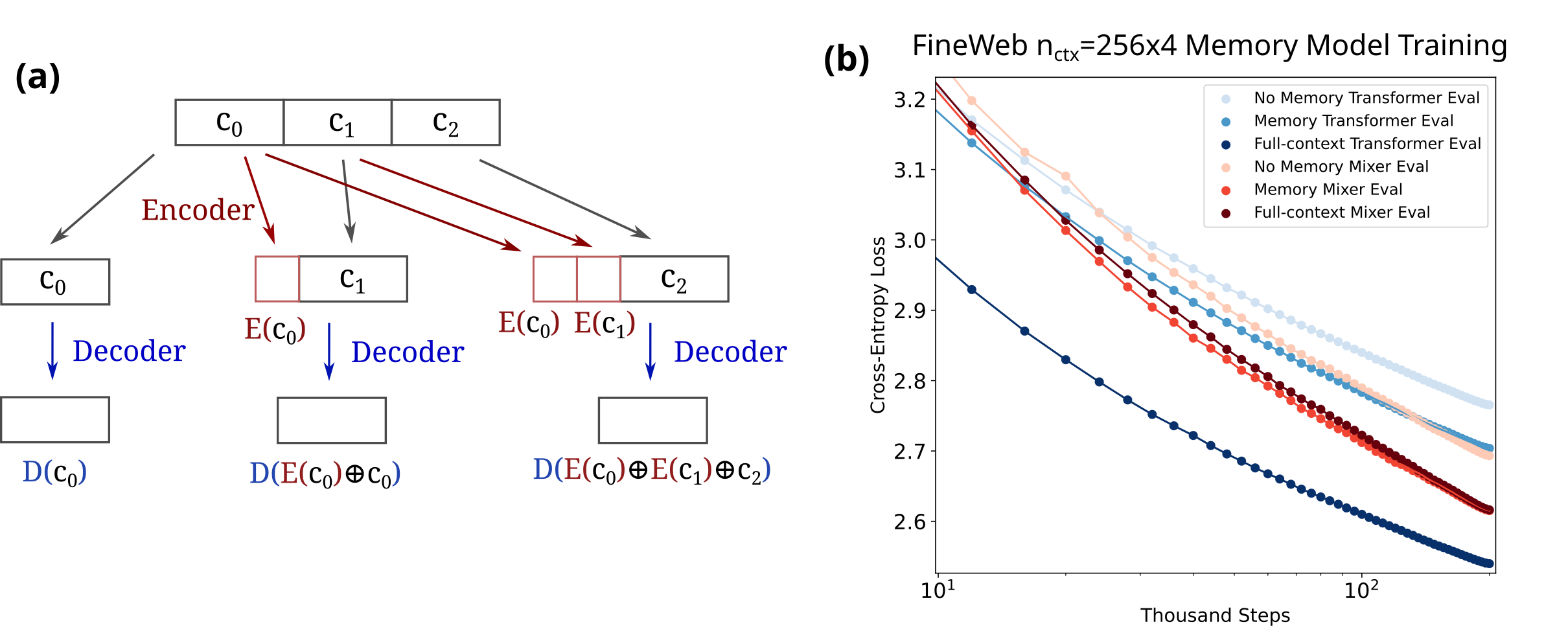
Autoencoder-based Parallelizable Memory Models
- Replaces causal model embeddings with autoencoder embeddings trained specifically for input regeneration, ensuring near-perfect memory formation
- Uses a parallelizable encoder-decoder architecture where the encoder is frozen after learning to compress inputs, and the decoder learns to use these 'memories' for prediction
- Combines causal language modeling objectives with information retention (reconstruction) objectives to enable arbitrary information access
Architecture
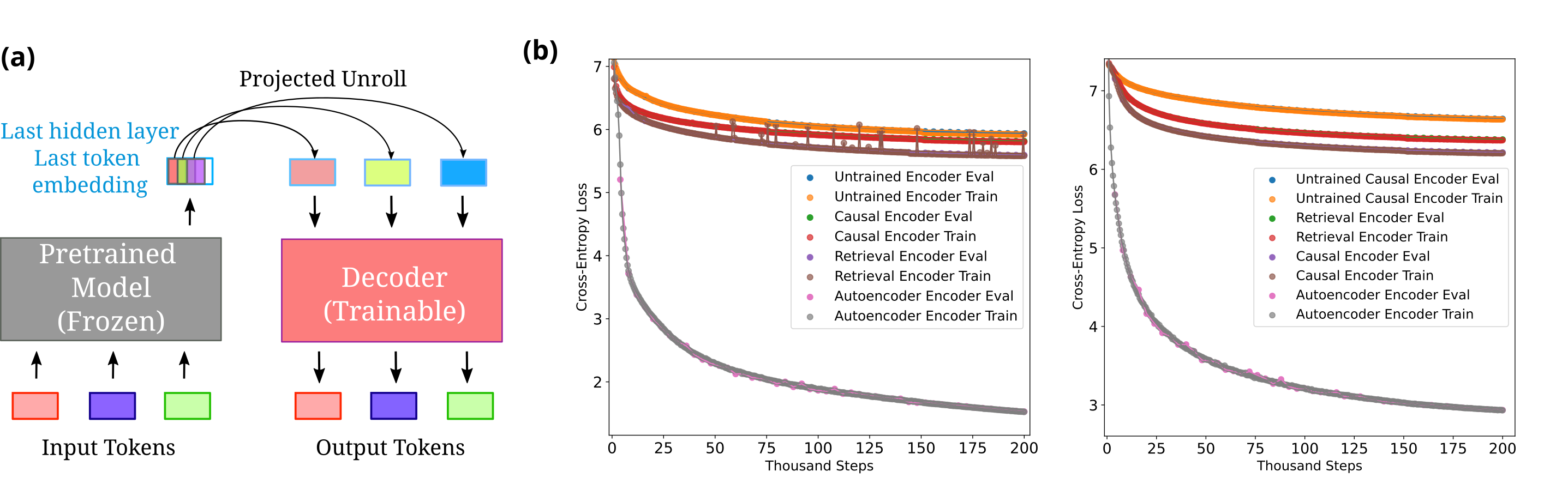
The Encoder-Decoder Information Retention Model architecture used for measuring memory fidelity.
Evaluation Highlights
- Autoencoders achieve >99% token accuracy in memory reconstruction, whereas causal models (like GPT-2) achieve ~20-60% depending on size and training
- Frozen-memory architectures maintain high reconstruction fidelity while learning language tasks, unlike causal models where memory degrades
- Input regeneration from output embeddings is significantly lower for larger context windows and diverse corpora compared to short prompts
Breakthrough Assessment
7/10
Provides a strong theoretical and empirical basis for why current memory models fail (non-invertibility of causal training) and proposes a viable architectural alternative, though large-scale scaling results are limited.