📝 Paper Summary
Memory organization
Linear memory
Agentic reasoning
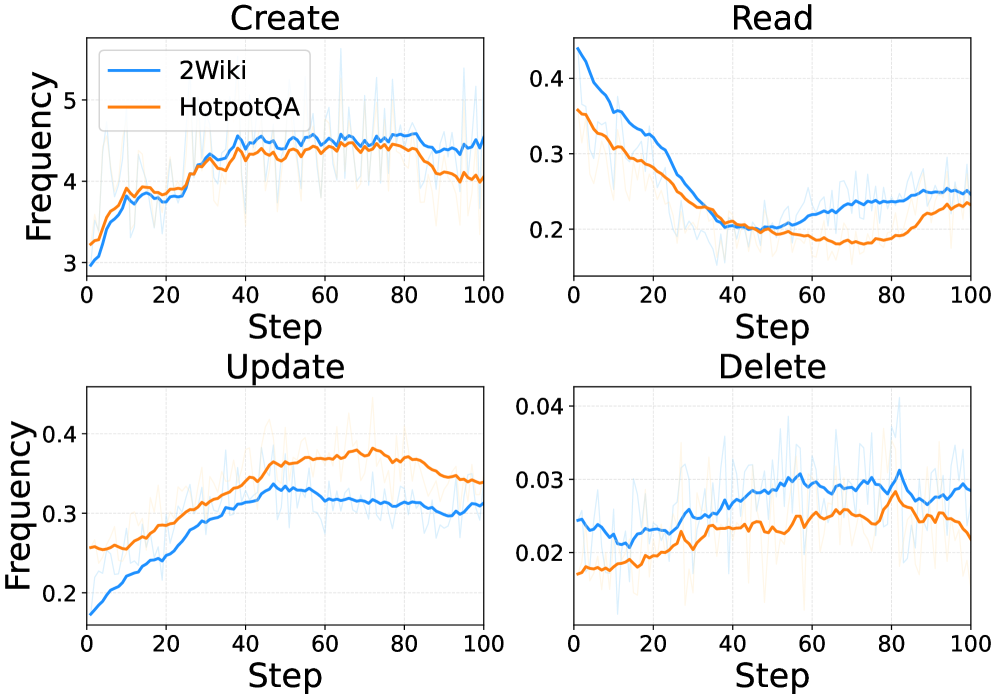
AtomMem replaces static memory workflows with a learnable policy that dynamically executes atomic Create, Read, Update, and Delete operations via reinforcement learning to adapt to task-specific information density.
Core Problem
Most agent memory systems rely on static, hand-crafted workflows (like mandatory updates or fixed forgetting schedules) that cannot adapt to the fluctuating information density of complex, long-horizon tasks.
Why it matters:
- Rigid 'one-size-fits-all' rules lead to redundant operations when information is sparse or premature forgetting when early cues are critical for later reasoning
- Continuous memory fusion strategies risk obscuring fine-grained details needed for precision-sensitive tasks
- Existing methods like MemAgent allow content optimization but still enforce constrained workflows (e.g., mandatory updates), wasting cognitive resources
Concrete Example:
In a long-context QA task where critical information appears early but is followed by noise, a static memory system with a fixed forgetting schedule might discard the early clue. Conversely, a system enforcing updates at every step will waste resources processing the noise, diluting the memory store.
Key Novelty
Deconstructed Atomic Memory Operations optimized via RL
- Reframes memory management as a sequential decision-making problem rather than a fixed pipeline, utilizing atomic CRUD (Create, Read, Update, Delete) actions
- Uses Group Relative Policy Optimization (GRPO) to train the agent to autonomously decide when to modify memory based on task context, rather than following heuristic rules
Architecture
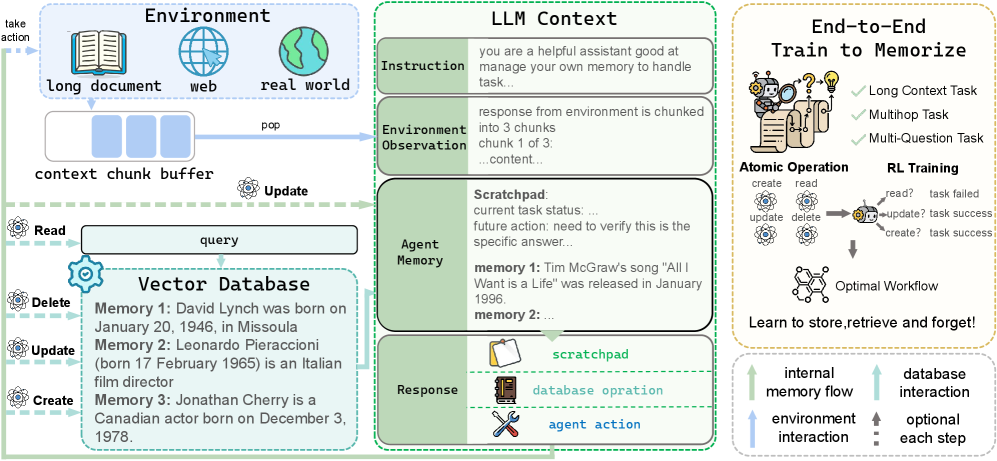
The overall AtomMem framework showing the interaction between the agent, environment, and memory storage via atomic operations.
Evaluation Highlights
- Outperforms prior static-workflow memory methods by approximately 2-5 percentage points across HotpotQA, 2WikiMultihopQA, and MuSiQue benchmarks
- Demonstrates robust scalability in Needle-in-a-Haystack tasks, maintaining a significant performance lead even when context is extended to 800 documents (4x training size)
- RL training improves performance by nearly 10 percentage points on average compared to the SFT initialization, verifying the benefit of dynamic memory policies
Breakthrough Assessment
8/10
Strong conceptual shift from static workflows to fully learnable atomic operations. The consistent performance gains and successful application of RL to memory management suggest a promising new direction for agentic memory.