📝 Paper Summary
Processing-In-Memory (PIM) Benchmarking
Distributed Optimization Algorithms
PIM-Opt evaluates distributed optimization algorithms on real-world UPMEM PIM hardware, demonstrating that communication-efficient algorithms like ADMM are essential to overcome the host-to-memory bandwidth bottleneck.
Core Problem
Training large-scale ML models on processor-centric architectures (CPUs/GPUs) is bottlenecked by data movement, yet existing Processing-In-Memory (PIM) research lacks evaluation of popular distributed SGD algorithms on real-world PIM hardware.
Why it matters:
- Data movement between memory and processors is the primary energy and performance bottleneck for large-scale ML training
- Prior PIM works often evaluate Gradient Descent (not the widely used SGD) or rely on simulation rather than real hardware
- The UPMEM PIM system resembles a distributed system but lacks direct inter-node communication, creating unique algorithmic constraints
Concrete Example:
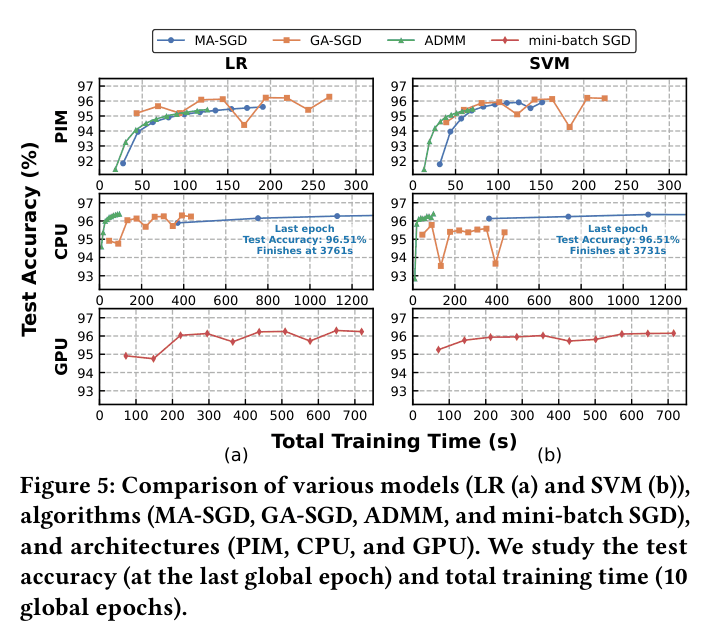
When training Logistic Regression on the Criteo dataset, standard MA-SGD (Model Averaging SGD) generates 64x more data movement between PIM and the host than ADMM (Alternating Direction Method of Multipliers), causing the host CPU to become a communication bottleneck.
Key Novelty
Communication-Aware Algorithm Selection for PIM
- Identifies that UPMEM PIM acts as a distributed system with a strict star topology (host as central node), making communication with the host the primary bottleneck
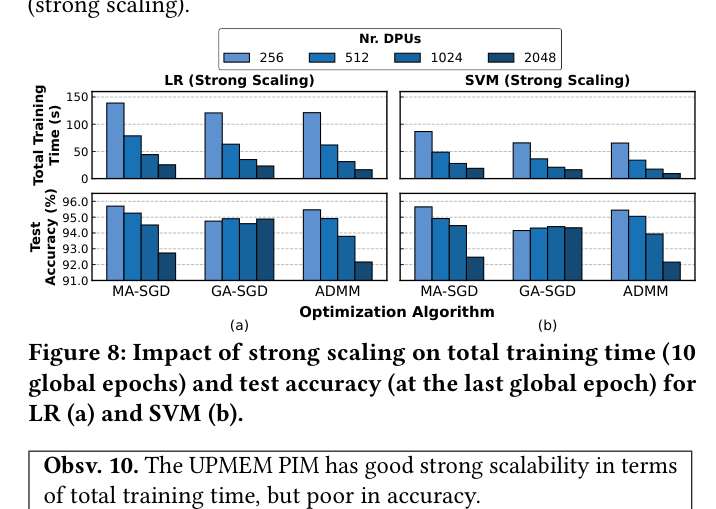
- Demonstrates that algorithms like ADMM (which synchronize less frequently) vastly outperform standard SGD variants (MA-SGD, GA-SGD) on PIM hardware by minimizing host-device data transfer
- Implements quantized training pipelines specifically optimized for the integer-only arithmetic units available in UPMEM DPUs
Architecture
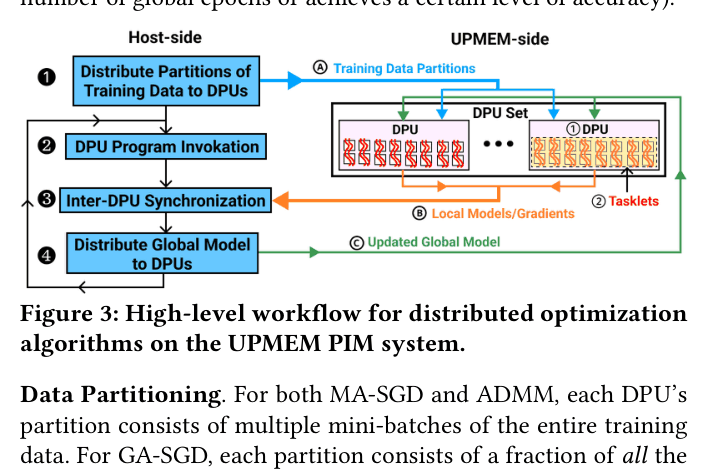
High-level workflow for distributed optimization algorithms on the UPMEM PIM system
Evaluation Highlights
- Training SVM with GA-SGD on PIM is 1.94x faster than a dual AMD EPYC 7742 CPU baseline on the YFCC100M dataset
- PIM achieves 3.19x speedup over an NVIDIA A100 GPU running mini-batch SGD for SVM training on YFCC100M
- ADMM reduces communication overhead significantly, achieving 39.79x speedup over MA-SGD for Logistic Regression on the CPU baseline
Breakthrough Assessment
7/10
First comprehensive evaluation of distributed SGD on real PIM hardware. Provides critical insights into algorithmic suitability and scalability limits, though limited to linear models and specific PIM hardware.