📝 Paper Summary
LLM Memory Systems
Evaluation Frameworks
The paper establishes a unified taxonomy and operational framework for LLM memory, decoupling model capability from information availability to enable rigorous evaluation of parametric, contextual, external, and procedural memory.
Core Problem
Current LLM memory research suffers from blurred conceptual boundaries (conflating RAG documents with contextual memory), fragmented evaluations that mix retrieval quality with generation faithfulness, and biased automated judges.
Why it matters:
- Deficiencies in memory mechanisms lead to high-stakes errors, such as citing non-existent statutes or phased-out drugs in legal and medical domains
- Lack of consensus on definitions prevents reproducible experimental designs and comparable results across different studies
- Existing benchmarks often fail to distinguish between the model's ability to recall facts and its ability to utilize provided evidence
Concrete Example:
When a physician asks for treatment options, an AI might recommend a drug phased out three years ago because it cannot reliably update its parametric memory, or an attorney might receive confident citations of non-existent statutes due to hallucinations in parametric recall.
Key Novelty
Unified Memory Quadruple and Layered Evaluation Framework
- Proposes a 'memory quadruple' (storage location, persistence, write/access path, controllability) to rigorously define four memory types: Parametric, Contextual, External, and Procedural
- Introduces a three-setting parallel protocol (Parameter-Only, Offline Retrieval, Online Retrieval) to decouple internal model capability from external information availability during evaluation
Architecture
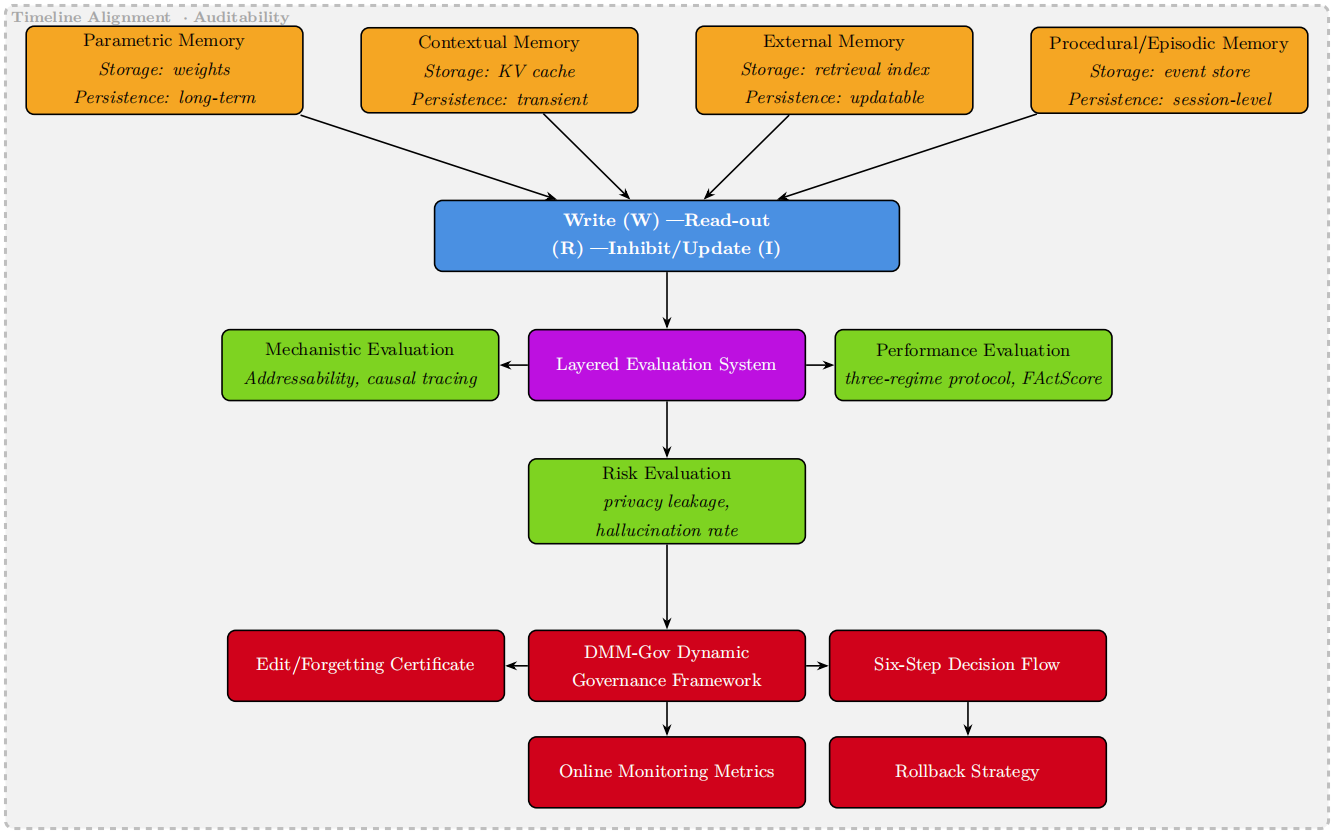
The unified analytical framework for LLM memory governance, mapping the four memory types (Parametric, Contextual, External, Procedural) to their mechanisms and evaluation layers.
Evaluation Highlights
- Identifies that automated judges suffer from position, order, and self-preference biases, causing 'spurious significance' in memory evaluations
- Establishes a causal chain of 'write—read—inhibit/update' to connect memory mechanisms with governance and evaluation
- Proposes DMM-Gov dynamic governance for coordinating model editing, RAG, and fine-tuning to form an auditable closed loop for memory updates
Breakthrough Assessment
9/10
Comprehensive foundational work that cleans up a fragmented field. It provides the definitions, taxonomy, and evaluation protocols necessary for future rigorous research, acting as a meta-framework rather than just a single method.