📝 Paper Summary
Layered memory
Agentic AI
Long Video Understanding
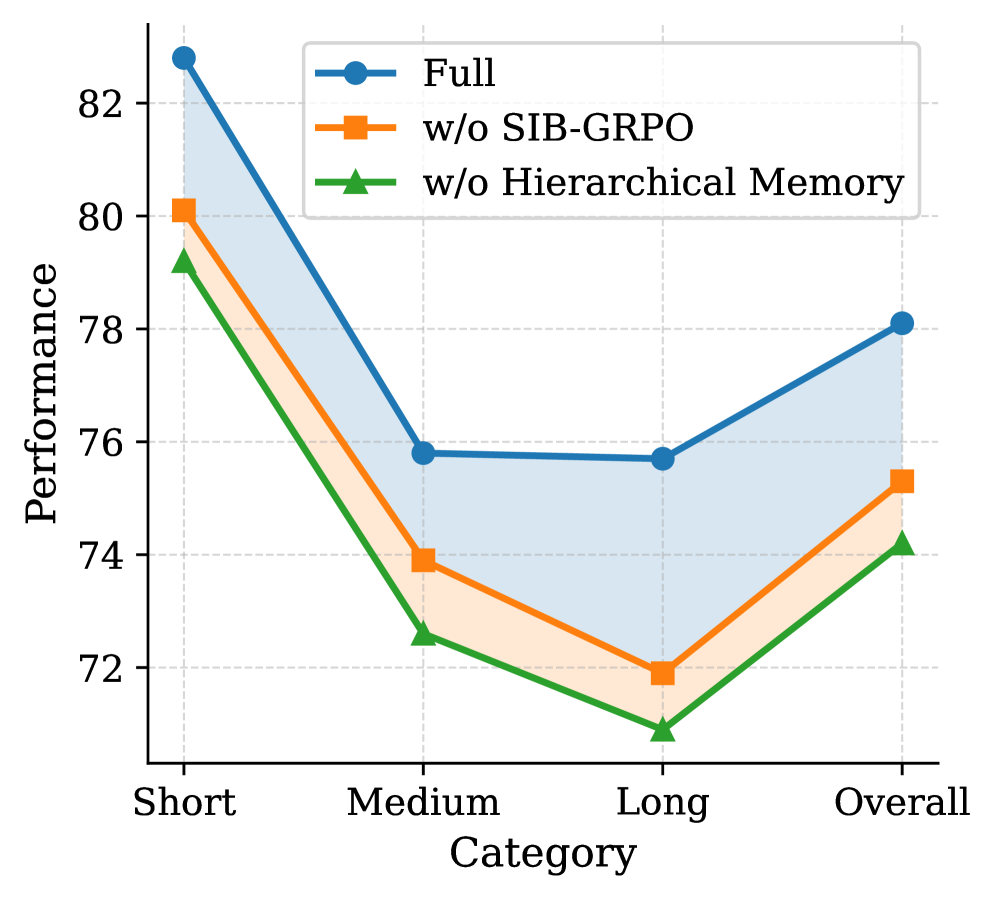
MM-Mem is a hierarchical memory system for video agents that compresses fine-grained sensory data into abstract schemas using an Information Bottleneck objective, enabling efficient retrieval from gist to verbatim details.
Core Problem
Existing video agents either accumulate dense visual data causing high latency and redundancy (vision-centric) or compress everything into text causing detail loss and hallucination (text-centric).
Why it matters:
- Current multimodal LLMs lack the dynamic memory management needed for long-horizon tasks, leading to context window overflow or forgetting
- Vision-centric methods suffer from cognitive overload when processing hours of video, while text-centric methods lose the visual evidence needed for precise verification
- Static memory mechanisms fail to mirror human cognitive efficiency, which balances abstract semantic understanding with specific perceptual recall
Concrete Example:
In a long video, a text-centric agent might summarize a scene as 'a person walks a dog,' discarding the specific leash color. If later asked 'Was the leash red?', the agent hallucinates. A vision-centric agent stores every frame, overwhelming its context window.
Key Novelty
Fuzzy-Trace Theory-inspired Pyramidal Memory (MM-Mem)
- Structures memory into three layers: Sensory Buffer (raw visual details), Episodic Stream (event summaries), and Symbolic Schema (abstract knowledge graph), mirroring human verbatim vs. gist traces
- Uses SIB-GRPO (Semantic-Information Bottleneck) to train a memory manager that compresses sensory data into episodic traces, maximizing semantic retention while minimizing redundancy
- Implements entropy-driven retrieval that starts with high-level schemas and only 'drills down' to low-level visual frames when the agent is uncertain
Architecture
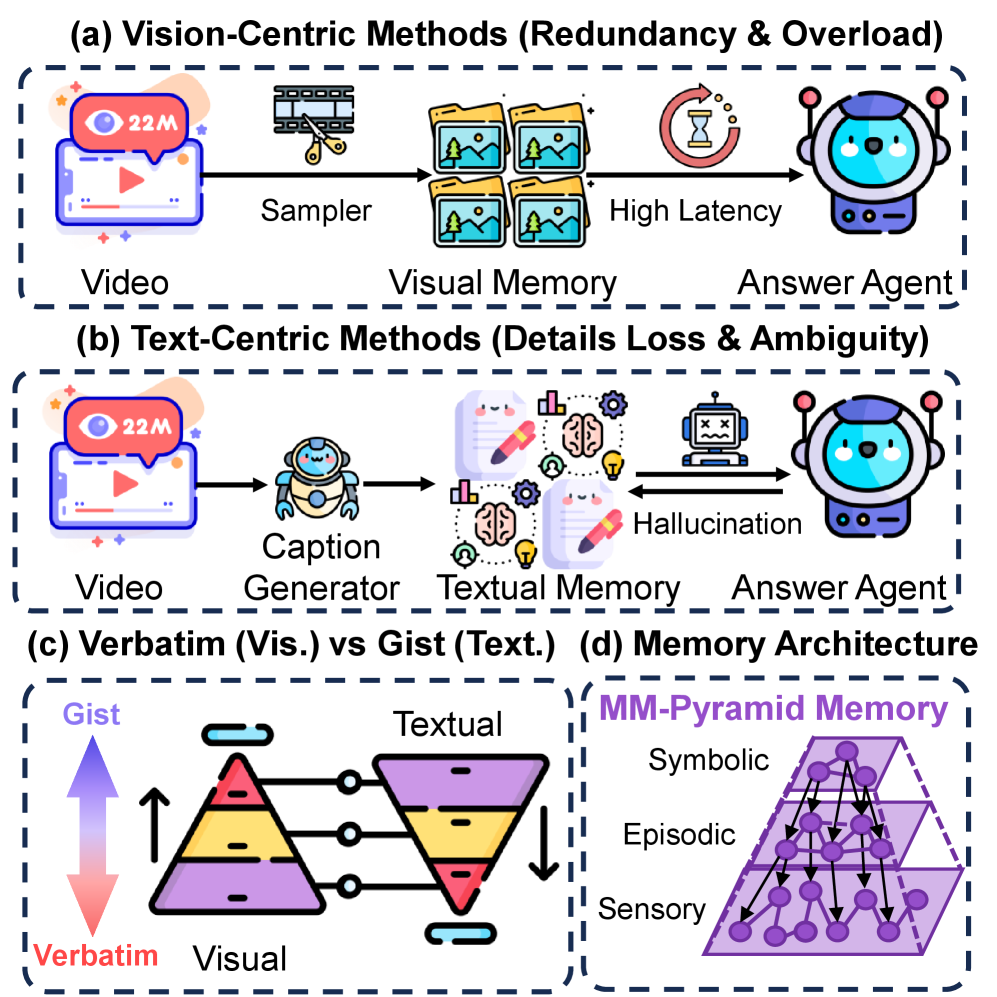
Comparison of MM-Mem's pyramidal architecture against Vision-centric and Text-centric paradigms, showing the three memory layers.
Evaluation Highlights
- Achieves state-of-the-art 63.8% accuracy on EgoSchema, outperforming proprietary Gemini 1.5 Pro (63.2%) and GPT-4o (61.9%)
- +13.1% improvement on LVBench compared to the strong open-source baseline LongVA
- Maintains 4-5% higher accuracy than leading baselines (VideoAgent, LongVA) as video duration increases from 600 to 3000 frames on LongVideoBench
Breakthrough Assessment
9/10
Proposes a cognitively grounded, mathematically rigorous (Information Bottleneck) architecture that solves the critical context-fidelity trade-off in long-video understanding, achieving superior performance over proprietary models.