📝 Paper Summary
Memory organization
Memory recall
Agentic RAG pipeline
Panini replaces verbatim document chunks with a structured memory of atomic question-answer pairs, using a chain-following retrieval algorithm to improve reasoning accuracy and reduce token usage.
Core Problem
Retrieval-Augmented Generation (RAG) inefficiently stores and retrieves verbatim text chunks, forcing models to repeatedly re-read the same tokens and often injecting irrelevant context that leads to hallucinations.
Why it matters:
- Standard RAG scales poorly: as memory grows, retrieving and processing raw text chunks becomes computationally expensive due to fixed context windows.
- Chunk-based retrieval often includes irrelevant information surrounding the key fact, which increases the likelihood of 'unsupported generation' (hallucination).
- Current methods struggle to reliably abstain from answering when the necessary information is not present in the stored memory.
Concrete Example:
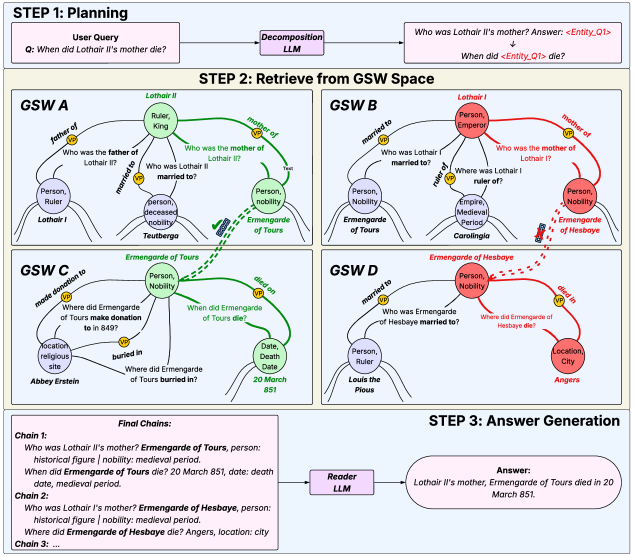
When answering 'When did Lothair II's mother die?', a standard RAG system might retrieve a long biography chunk about Lothair II containing many dates. Panini instead retrieves a precise QA pair 'Who was the mother of Lothair II? -> Ermengarde' and links it to 'When did Ermengarde die? -> 851', avoiding the noise of the full biography.
Key Novelty
Generative Semantic Workspaces (GSW) with Reasoning Inference Chain Retrieval (RICR)
- Transforms raw documents into a 'Generative Semantic Workspace' (GSW)—a network of atomic Question-Answer (QA) pairs linked to entities and events, rather than storing text chunks.
- Replaces similarity-based chunk retrieval with 'Reasoning Inference Chain Retrieval' (RICR), a beam-search process that follows entity links through the QA network to construct precise reasoning paths.
Architecture
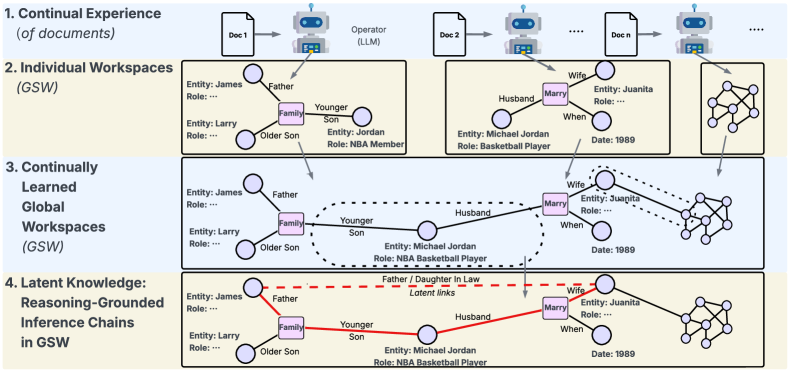
Overview of the Panini framework, comparing traditional RAG to the proposed GSW + RICR approach.
Evaluation Highlights
- Achieves 5% - 7% higher average performance across six QA benchmarks compared to competitive baselines (including GraphRAG and HippoRAG).
- Reduces answer-context token usage by 2–30x compared to chunk-based retrieval methods, significantly lowering inference costs.
- Demonstrates superior reliability on 'Platinum' benchmarks, accurately abstaining from unanswerable queries where baselines often hallucinate.
Breakthrough Assessment
8/10
Strong conceptual advance moving from 'chunk-based' to 'fact-based' (QA pair) memory for RAG. Significant efficiency gains (up to 30x fewer tokens) make this highly practical for scaling.