📝 Paper Summary
Memory organization
KV Cache Management
Efficient Transformers
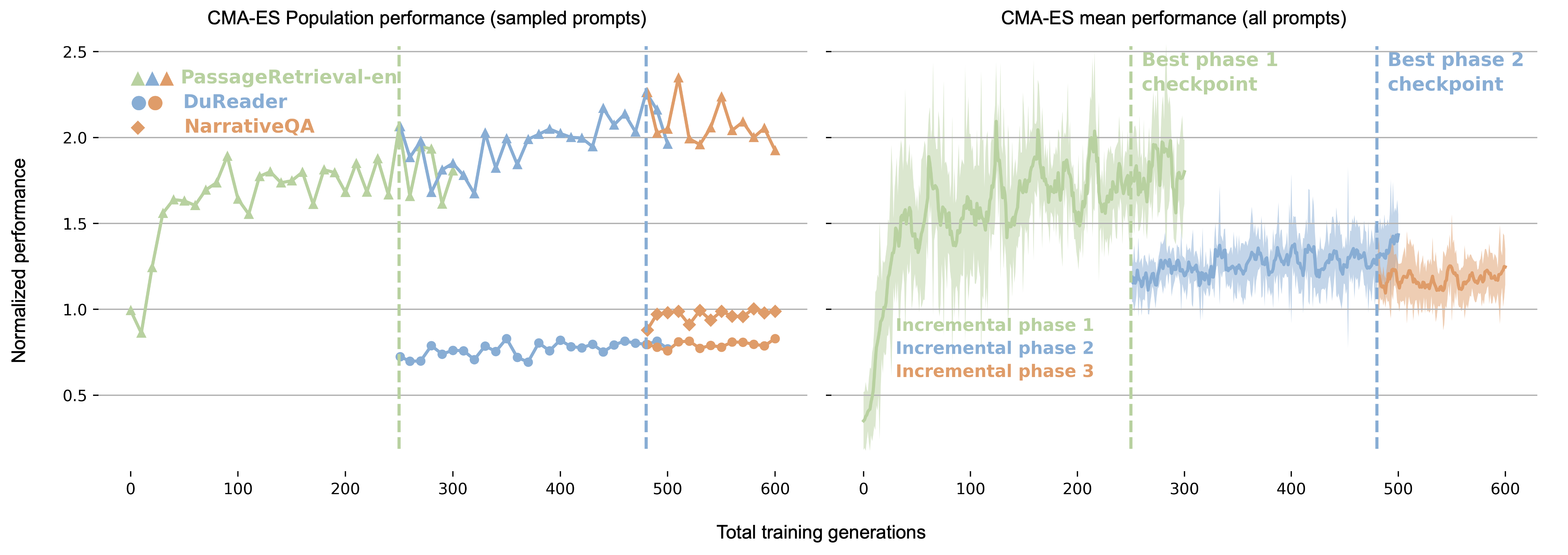
Neural Attention Memory Models (NAMMs) use a small neural network trained via evolution to dynamically select and evict KV cache tokens based on their attention history, improving both efficiency and performance.
Core Problem
Transformers struggle with long contexts due to quadratic attention costs, and existing heuristics for pruning the KV cache (like H2O) are hand-designed, lossy, and often degrade performance.
Why it matters:
- Long-context tasks are resource-hungry, making foundation models expensive to train and serve
- Hand-designed rules for token eviction inevitably trade off performance for efficiency, failing to distinguish truly useful information from noise
- Current methods cannot adaptively shape memory based on task needs or transfer learned memory strategies across different architectures
Concrete Example:
In tasks like PassageRetrieval where specific details matter, heuristic methods like H2O evict tokens based on simple accumulation of attention scores. This often discards critical information that appears rarely but is vital for the answer, leading to lower retrieval accuracy compared to the full context.
Key Novelty
Neural Attention Memory Models (NAMMs) optimized via Evolution
- Replaces hand-crafted eviction heuristics with a learned neural network that scores tokens for retention based on the frequency patterns of how they were attended to (captured via spectrograms)
- Uses evolutionary strategies (CMA-ES) instead of gradients, bypassing the non-differentiable nature of binary keep/drop decisions
- Features are constructed purely from attention matrices (not token embeddings), allowing the memory model to transfer zero-shot to completely different transformer architectures and modalities (e.g., vision, RL)
Architecture
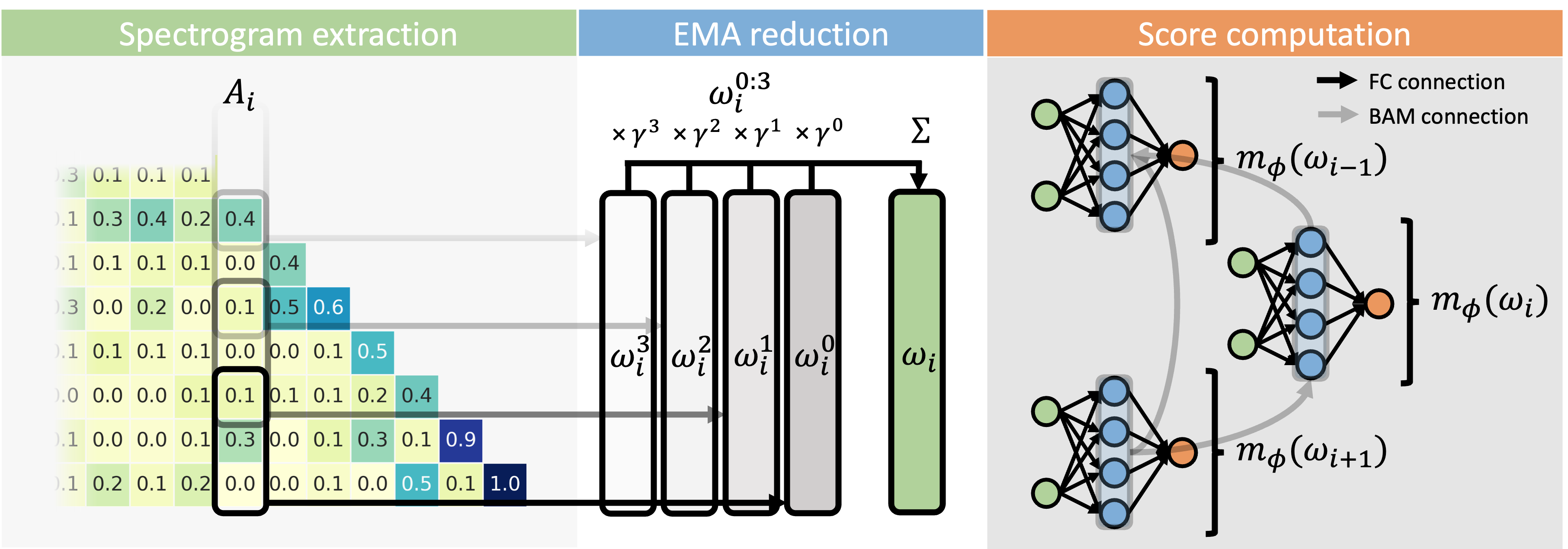
The complete pipeline: Attention Matrix extraction, STFT processing, and the BAM network structure.
Evaluation Highlights
- Outperforms full-context Llama-3-8B by +11% on LongBench tasks while reducing cache size, showing it removes noise rather than just tolerating loss
- Achieves higher performance than hand-designed baselines (H2O, L2) while maintaining smaller average cache sizes across 36 tasks
- Demonstrates zero-shot transfer from Llama-3-8B (language) to Stable Diffusion (vision) and Decision Transformer (RL), improving efficiency without retraining the memory model
Breakthrough Assessment
8/10
Strong conceptual novelty in using evolution for differentiable memory management and achieving zero-shot transfer across modalities. effectively turns memory management into a learned, transferable skill.