📝 Paper Summary
Memory organization
Agentic AI
MEM equips robot policies with two distinct memory scales: a dense video encoder for immediate physical context and a compressed text-based semantic memory for tracking long-term task progress.
Core Problem
Robots need both immediate visual history (to handle occlusions/dynamics) and long-term semantic history (to track recipe steps), but encoding full video history for long tasks is computationally intractable.
Why it matters:
- Encoding minutes of video frames individually explodes inference latency, making real-time robot control impossible
- Single-modality memories fail: text lacks spatial precision for grasping, while keyframes lose dynamic information needed for physics estimation
- Without long-term memory, robots repeat completed subtasks (e.g., adding an ingredient twice) or fail to recover from temporary visual occlusions
Concrete Example:
A robot cooking dinner might need to remember it already added salt 10 minutes ago (long-term semantic fact) while simultaneously needing to remember where a bowl is located now that its arm is blocking the camera (short-term visual occlusion). Current models struggle to handle both timescales efficiently.
Key Novelty
Multi-Scale Embodied Memory (MEM)
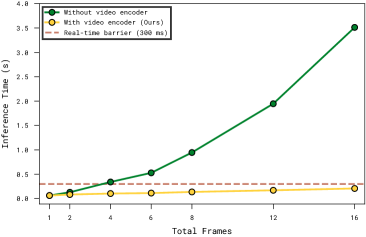
- Uses a specialized video encoder with factorized spatial-temporal attention to compress recent video history into a fixed number of tokens, enabling dense visual memory without high computational cost
- Maintains a running text summary of past events (semantic memory) managed by a high-level policy, which explicitly predicts memory updates rather than storing raw history
Architecture
The MEM architecture showing the Video Encoder and the VLA Backbone interaction.
Evaluation Highlights
- Enables robots to solve tasks spanning up to 15 minutes, such as cleaning a whole kitchen or preparing a grilled cheese sandwich
- Achieves state-of-the-art performance on complex manipulation tasks by integrating with the π0.6 VLA model
- Demonstrates in-context adaptation capabilities, allowing the policy to correct mistakes and handle partial observability using short-term video memory
Breakthrough Assessment
8/10
Strong engineering solution to the context length problem in robotics. Effectively combines the spatial precision of video with the compression of text, enabling significantly longer task horizons than typical frame-stacking approaches.