📝 Paper Summary
Multimodal Agents
Tool-augmented Large Language Models
Visual Reasoning
AdaReasoner enables multimodal models to autonomously learn when and how to orchestrate diverse visual tools through a specialized reinforcement learning pipeline that treats tool use as a generalizable reasoning skill.
Core Problem
Current multimodal models struggle with adaptive tool usage, often relying on rigid, pre-defined patterns or single-tool loops, failing to flexibly coordinate multiple tools or generalize to new ones.
Why it matters:
- Rigid tool policies are brittle and fail when encountering unseen tools or novel tasks outside the training distribution.
- Existing methods do not treat tool selection (what, when, how) as a core reasoning component, limiting performance on complex, long-horizon visual tasks.
Concrete Example:
In a visual spatial planning task, a model might need to navigate a map. Without adaptive planning, it might guess a path or use a tool once and fail. AdaReasoner iteratively uses an 'A*' tool for pathfinding, verifies the result, and backtracks if the verification fails, whereas standard models would lack this self-correction loop.
Key Novelty
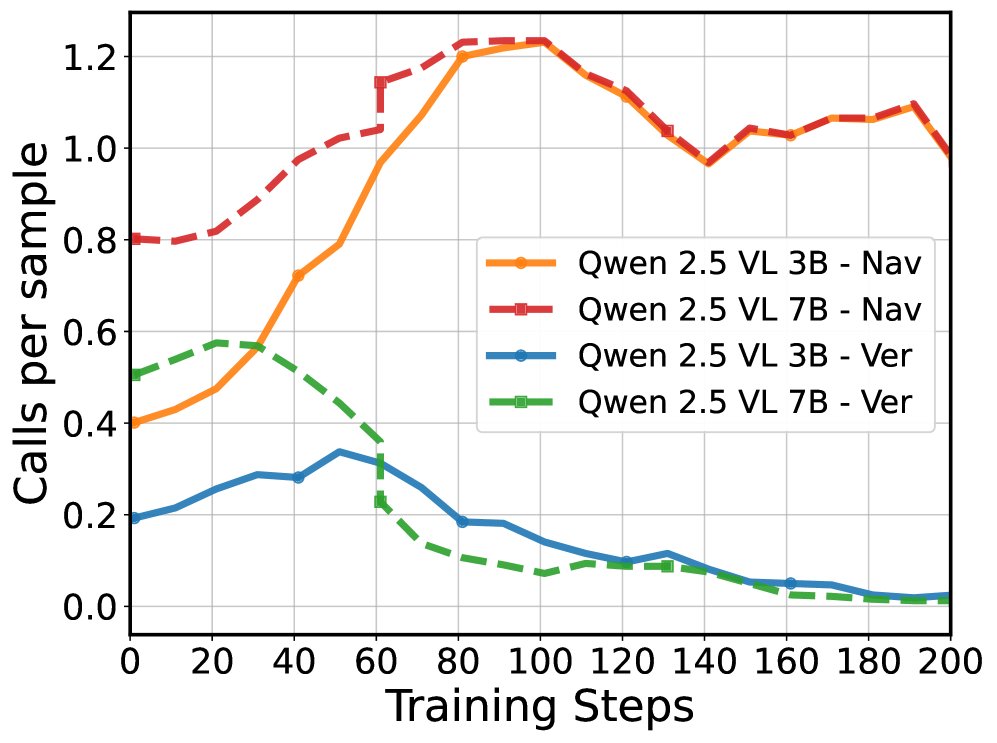
Tool-GRPO with Adaptive Learning
- Treats tool usage as a sequential decision process optimized via reinforcement learning (Tool-GRPO), rewarding correct reasoning formats and final accuracy rather than just imitating human traces.
- Introduces an 'Adaptive Learning' mechanism during training that randomizes tool names and descriptions, forcing the model to learn tool semantics rather than overfitting to specific tool identifiers.
Architecture
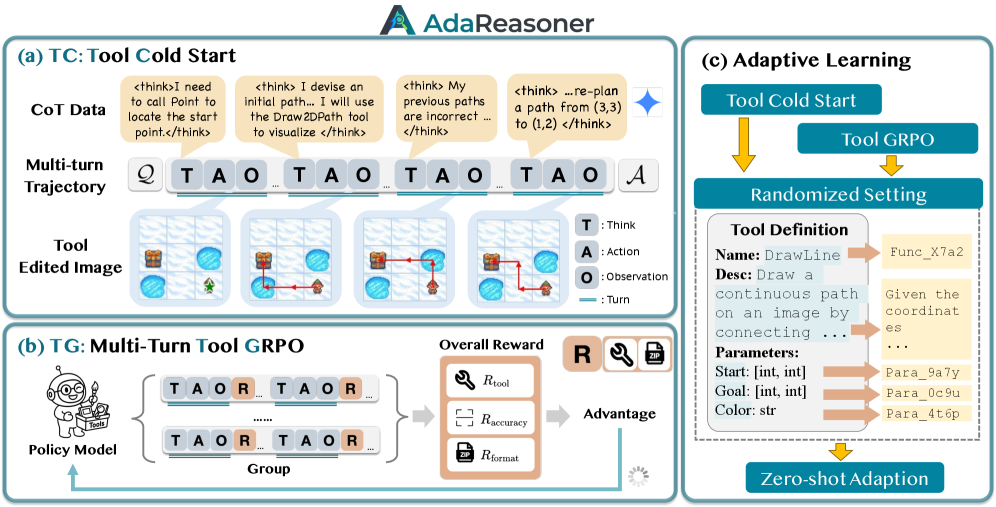
The overall framework of AdaReasoner, illustrating the Data Curation pipeline (left) and the Tool-GRPO training process (right).
Evaluation Highlights
- AdaReasoner-7B improves average performance by +24.9% over the base model across visual reasoning benchmarks.
- Surpasses proprietary GPT-5 on the Visual Spatial Planning (VSP) task (96.60% vs 80.10%) and Jigsaw task.
- Achieves 97.64% on VSP, transforming it from a near-failing task for base models (~31.64%) to a solved one.
Breakthrough Assessment
8/10
Significant performance jumps on hard benchmarks, beating GPT-5 with a 7B model. The approach of randomizing tool definitions to force semantic learning is a clever, high-impact methodological contribution to agent generalization.