📝 Paper Summary
Tool learning
Tool retrieval
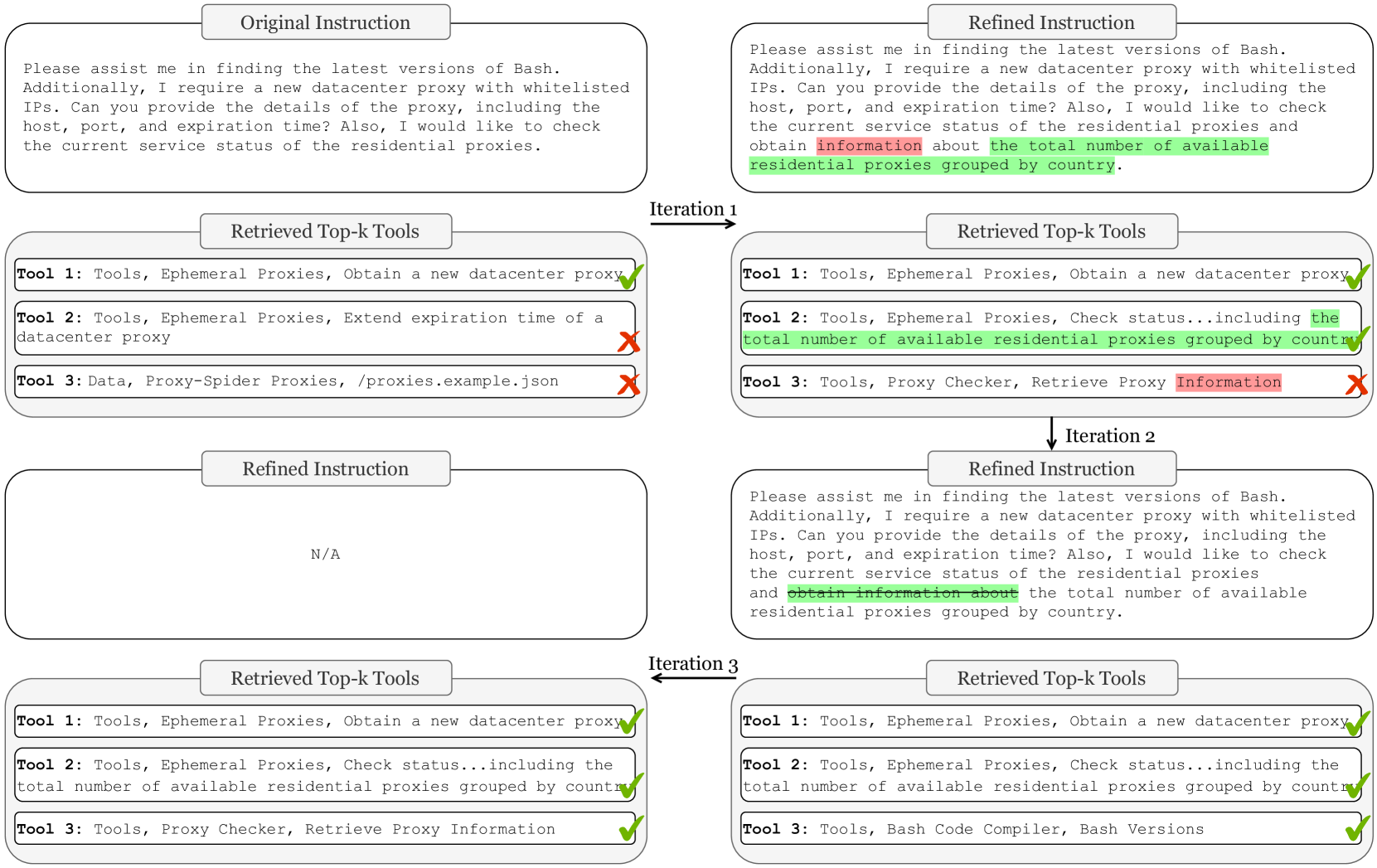
This paper enhances tool retrieval by using an LLM to iteratively critique retrieved tools and refine the user query, bridging the gap between retriever selection and actual tool utility.
Core Problem
Standard dense retrievers struggle with the complexity of tool descriptions and are misaligned with downstream tool-usage models, often retrieving tools that look semantically similar but are functionally irrelevant.
Why it matters:
- Real-world tool libraries are vast and constantly updating, making fine-tuning or full-context learning impossible
- Existing retrievers treat tools like documents, failing to grasp the specific functional nuances required for execution
- Misalignment hinders the LLM from accessing truly useful tools, degrading overall system performance
Concrete Example:
A user asks for 'stock prices'. A standard retriever might fetch a generic 'calculator' or 'currency converter' because of keyword overlap, while the LLM actually needs a specific 'stock_market_api'. The proposed method allows the LLM to critique the 'calculator' as irrelevant and refine the query to 'fetch real-time stock market data'.
Key Novelty
Iterative Feedback-based Tool Retrieval
- Leverages the tool-using LLM as a 'critic' to evaluate retrieved tools before execution
- The LLM provides structured feedback (Comprehension, Assessment, Refinement) to rewrite the search query
- Uses iteration-aware training to teach the dense retriever to handle progressively refined queries and hard negatives
Architecture
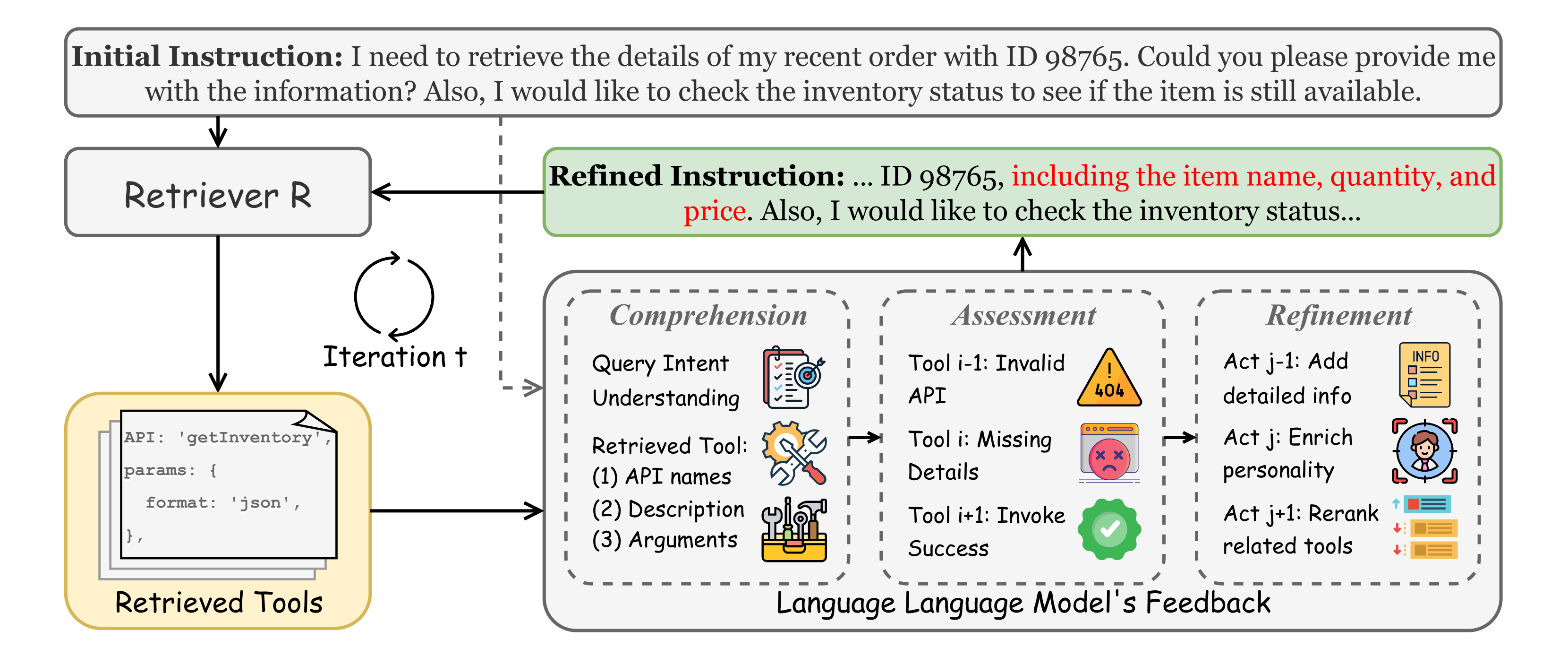
The iterative feedback framework. It shows the cycle of Retrieval -> LLM Feedback (Comprehension, Assessment, Refinement) -> Refined Instruction -> Re-Retrieval.
Evaluation Highlights
- Achieves best performance on TR-Bench (In-Domain), surpassing dense retrieval baselines by significant margins (e.g., +6.3% Recall@5 vs ToolBench)
- Outperforms baselines on Out-of-Domain evaluation, demonstrating robustness to unseen tools
- Iterative refinement consistently improves retrieval quality over multiple rounds (e.g., Recall@5 improves from 0.73 to 0.81 over 3 iterations)
Breakthrough Assessment
7/10
Offers a logical and effective solution to the retriever-LLM misalignment problem in tool use. While the core concept of 'LLM feedback' is known, applying it iteratively to the *pre-execution* retrieval phase is a valuable specific contribution.