📝 Paper Summary
Multi-call tool use with flexible plan
RL-based tool use
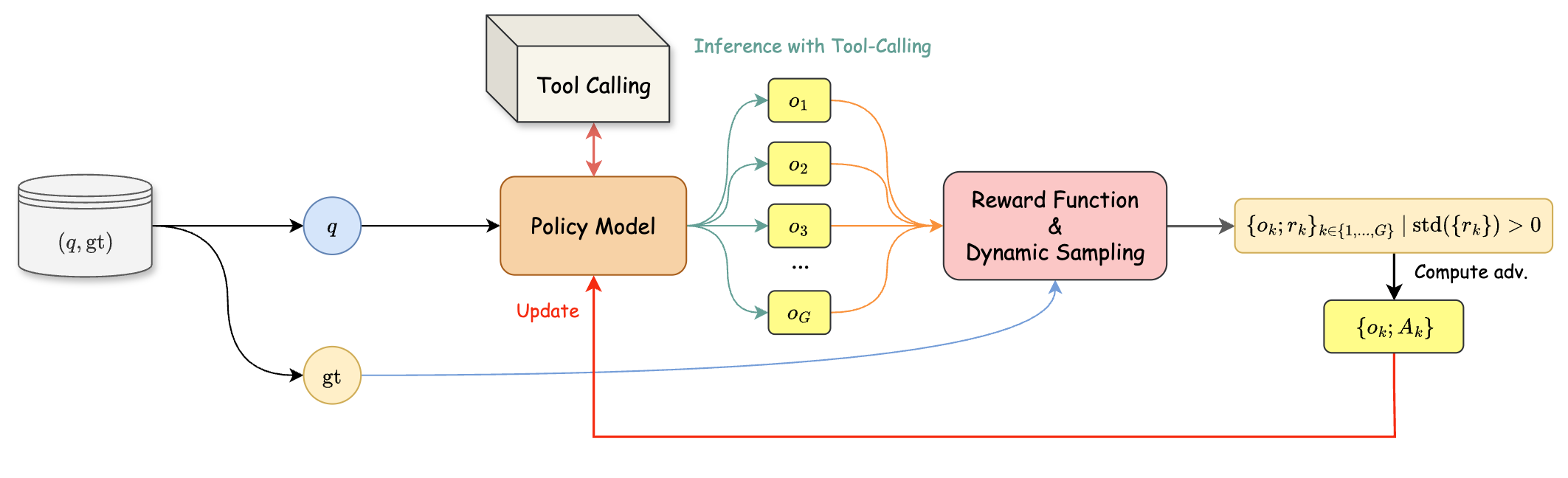
TAPO is a reinforcement learning framework that trains language models to dynamically interleave reasoning thoughts with search and code execution tools, preventing reward hacking through dynamic sampling and response masking.
Core Problem
Existing tool-augmented models either lack explicit reasoning steps or struggle with multi-hop tool invocation, often suffering from generalization gaps or reward hacking (excessive tool calls) when trained via RL.
Why it matters:
- Models relying solely on internal knowledge fail at tasks requiring up-to-date information or precise calculation
- Current RL methods for tools often degrade general reasoning performance or encourage the model to spam tool calls to 'hack' the reward metric
- Rigid tool-use frameworks (like ReAct without RL optimization) struggle to adaptively decide *when* to reason vs. *when* to act
Concrete Example:
A search-augmented model might perform well on search queries but lose its ability to solve math problems, or it might learn to call a calculator for every trivial step (reward hacking) instead of reasoning directly.
Key Novelty
Tool-Augmented Policy Optimization (TAPO)
- Integrates 'thinking' tokens (reasoning traces) directly into the RL policy alongside tool actions, allowing the model to deliberate before calling Search or Python
- Uses a binary mask during training to zero-out loss from tool-generated tokens, ensuring the policy update focuses only on the LLM's own decisions
- Adapts Dynamic Sampling Policy Optimization (DAPO) to tool use, mixing high/low quality samples to stabilize training and prevent entropy collapse
Architecture
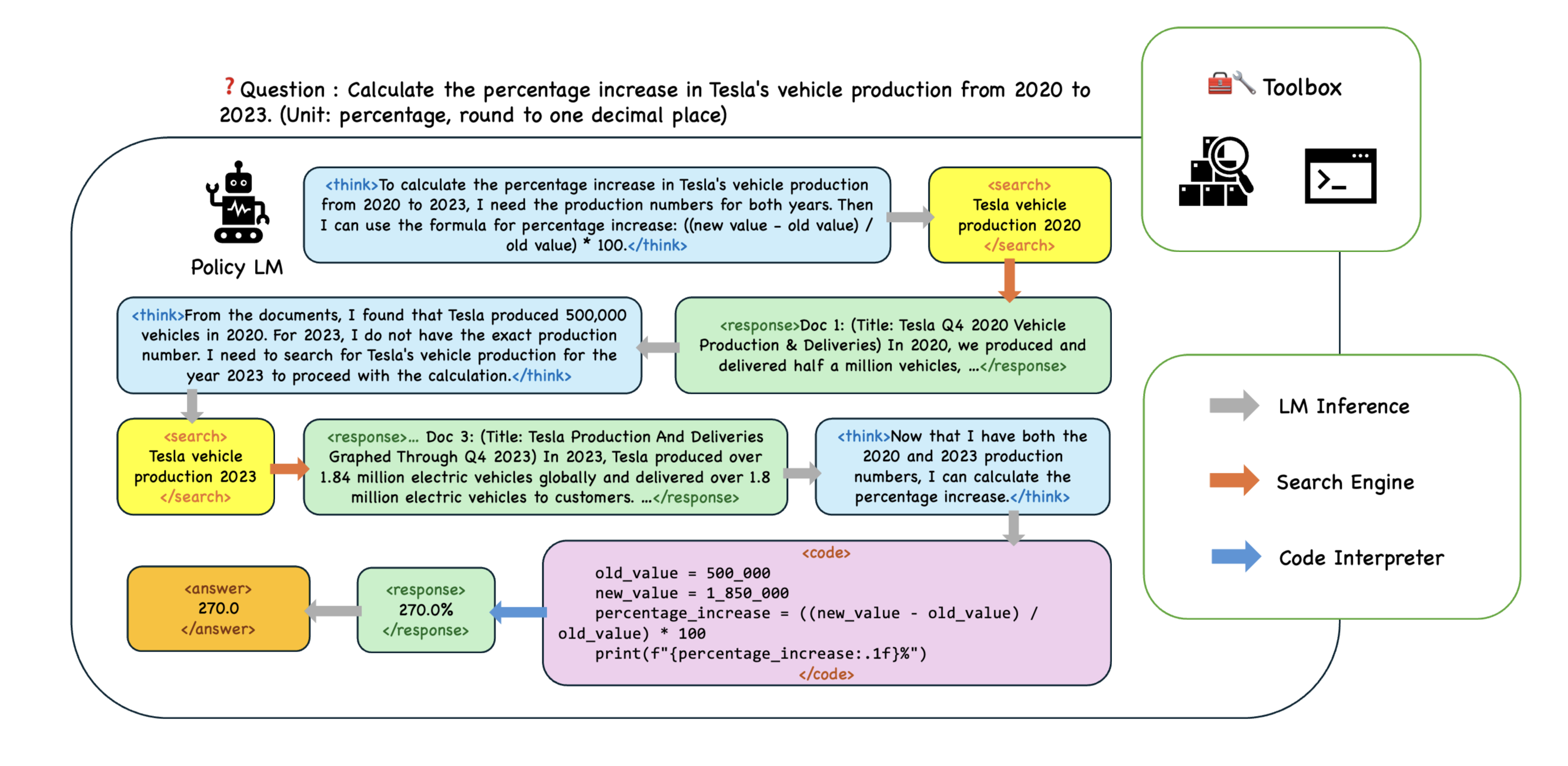
The inference trajectory and interaction flow of TAPO.
Evaluation Highlights
- Achieves state-of-the-art performance on MATH and GPQA Diamond benchmarks among models with comparable parameters (Qwen2.5-7B base)
- TAPO-7B surpasses the specialized Search-R1-7B baseline by a significant margin on the TAPO-easy evaluation set
- Reduces average tool calls while maintaining or improving accuracy, mitigating the 'reward hacking' behavior seen in baselines like ReAct-RL
Breakthrough Assessment
8/10
Strong methodological contribution in stabilizing RL for tool use. Successfully unifies reasoning traces (like o1/R1) with external tools, addressing a critical gap in current agentic RL.