📝 Paper Summary
Tool profiling
Tool-use post-training
EASYTOOL transforms lengthy, inconsistent tool documentation into concise instructions with synthesized usage scenarios, improving LLM agent performance while reducing token costs.
Core Problem
Existing tool documentations are diverse, redundant, and often incomplete (missing usage scenarios), causing LLMs to struggle with context limits and incorrect parameter prediction.
Why it matters:
- Massive redundant information in API docs (e.g., URLs, pricing) consumes valuable context window tokens
- Inconsistent formats across different tool providers (e.g., RapidAPI vs. Hugging Face) make it hard for agents to parse functionality reliably
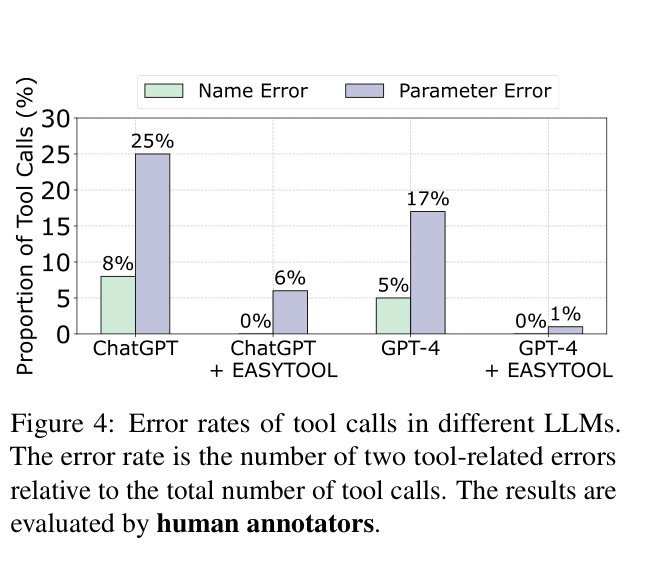
- Lack of concrete examples leads to high parameter error rates when LLMs attempt to invoke tools
Concrete Example:
A RapidAPI documentation might contain 2,530 tokens of metadata like 'pricing: FREEMIUM' and server URLs, obscuring the core 'List Movies' function. Without an example, an LLM fails to predict the required boolean parameter 'with_rt_ratings', causing execution failure.
Key Novelty
Two-stage Tool Instruction Generation
- Stage 1 (Description Generation): Uses an LLM to distill raw documentation into a standardized 'Tool Description' that strips irrelevant metadata (like IDs/URLs) and retains only functional purposes.
- Stage 2 (Guideline Construction): Synthesizes 'Tool Functionality Guidelines' by generating concrete usage scenarios and example parameter payloads (e.g., JSON inputs) to ground the model's understanding.
Architecture

Comparison between raw tool documentation (messy, redundant) and EASYTOOL's unified tool instruction (concise, structured with examples).
Evaluation Highlights
- Reduces token consumption by 70.43% on ToolBench and 97.35% on RestBench compared to original documentation
- Achieves 72.8% Success Rate with GPT-4 + DFSDT on ToolBench, outperforming the baseline GPT-4 + DFSDT (64.3%)
- Boosts ChatGPT's Correct Path Rate on RestBench-TMDB from ~45% (ReAct) to ~65% (EASYTOOL), significantly improving tool sequencing
Breakthrough Assessment
7/10
Simple yet highly effective preprocessing method that solves a major practical bottleneck (token cost and documentation quality) for agentic systems. Strong empirical results across multiple benchmarks.