📝 Paper Summary
Multi-call tool use with flexible plan
Benchmark
SynthTools is a scalable framework that generates, simulates, and audits thousands of diverse synthetic tools to create reliable environments for training and evaluating tool-use agents.
Core Problem
Training tool-use agents requires large-scale, diverse environments, but real-world APIs suffer from access limits, rate quotas, and instability, while existing hand-crafted benchmarks are too small.
Why it matters:
- Real APIs (e.g., RapidAPI) are impractical for large-scale training due to cost, authentication requirements, and frequent deprecation
- Current benchmarks like ACEbench and τ-bench cover very few domains (e.g., 2-8), limiting the generalization capability of agents trained on them
- Without a scalable source of reliable tools, researchers cannot rigorously test agents on long-horizon planning or complex compositional reasoning
Concrete Example:
Directly prompting ChatGPT to generate tools yields trivial outputs like 'robotics.create_task'. In contrast, a real flight booking scenario needs complex state management (checking seat availability before booking), which static generation fails to simulate reliably.
Key Novelty
Hierarchical Domain Evolution for Synthetic Tools
- Uses a structured top-down generation pipeline: Field → Subdomain → Task → Tool, ensuring tools are grounded in realistic workflows rather than being random functions
- Decouples simulation into 'Parameter Validation' (gateway emulation) and 'Response Generation' (state-dependent logic) to ensure high reliability without real backend code
Architecture
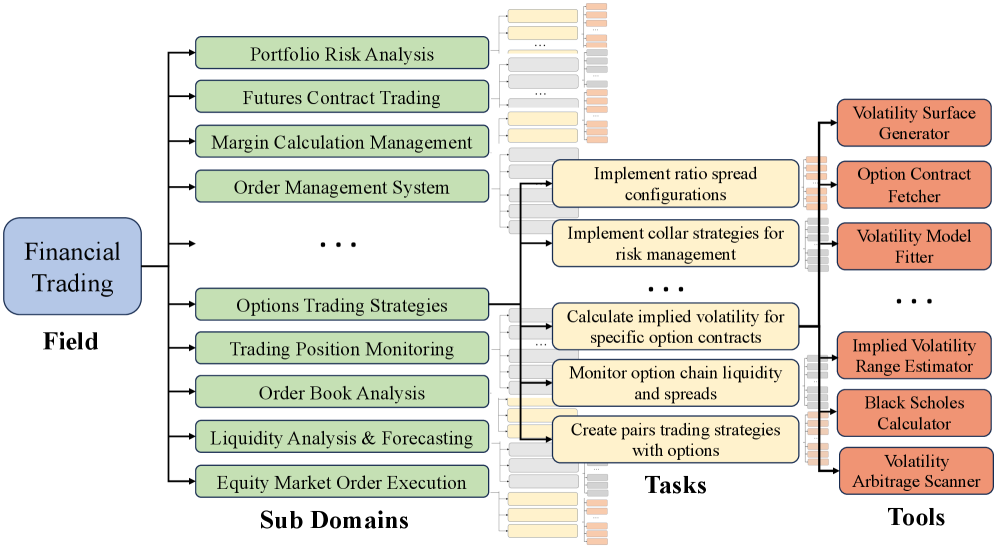
The hierarchical domain evolution procedure for generating tools
Evaluation Highlights
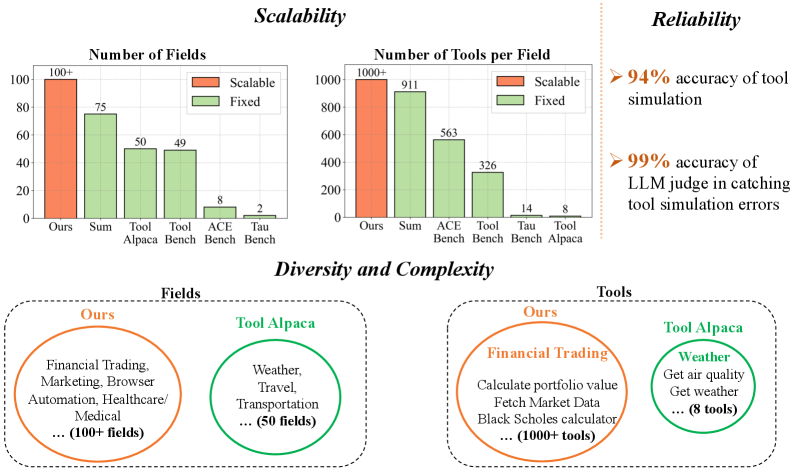
- Generated ~6,000 synthetic tools spanning 100 distinct domains, exceeding prior work by >2× in both domains and tools per domain
- Tool Simulation module achieves 94% accuracy in faithfully emulating tool responses across varied test cases (verified by human and LLM judges)
- Tool Audit module achieves 99% accuracy in identifying incorrect simulator behaviors, ensuring the final toolset is highly reliable
Breakthrough Assessment
8/10
Significantly scales up the availability of diverse, reliable tools for agent training, solving a major bottleneck (API scarcity/instability). The high reliability of simulation makes it a viable substitute for real APIs.