📝 Paper Summary
Multi-Agent Systems
Tool Retrieval
Agentic RAG pipeline
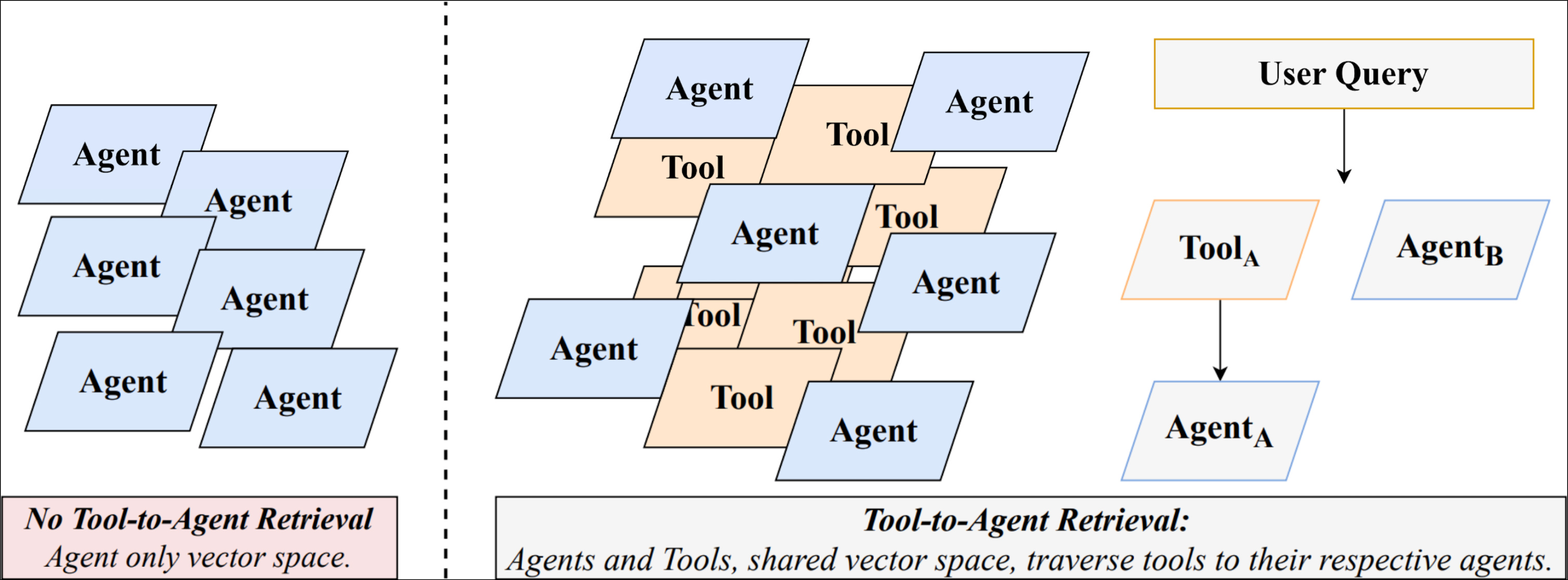
Tool-to-Agent Retrieval embeds tools and their parent agents in a shared vector space, allowing a single retrieval step to identify the best agent bundle even when the query matches only specific tool functionality.
Core Problem
Existing retrieval methods for multi-agent systems either match queries against coarse agent descriptions (missing fine-grained capabilities) or against individual tools (losing necessary agent context and coordination).
Why it matters:
- Agent-first pipelines hide relevant tools if the parent agent description is too generic or brief.
- Tool-only retrieval ignores the benefits of equipping a cohesive 'bundle' of tools (an agent) necessary for multi-step workflows.
- Sending all tool definitions to an LLM is cost-prohibitive (e.g., one server with 26 tools consumes >4,600 tokens).
Concrete Example:
A user asks for 'code analysis'. An 'agent-first' retriever might miss a 'Python Utility Agent' if its description is vague, while a 'tool-only' retriever might find a 'syntax checker' tool but fail to load the necessary authentication or companion debugging tools provided by the parent agent.
Key Novelty
Unified Tool-to-Agent Indexing & Traversal
- Embeds both individual tools and parent agents in the same vector database, rather than keeping them in separate hierarchical indices.
- Uses metadata links to map retrieved tools back to their parent agents, allowing the system to surface the correct agent bundle even if the match was found at the fine-grained tool level.
Architecture
Conceptual diagram of Tool-to-Agent Retrieval. It shows how the User Query is matched against a Unified Index containing both Tools and Agents. Matches are then resolved via Metadata Links to identify the Top-K Agents.
Evaluation Highlights
- +19.4% improvement in Recall@5 compared to MCPZero (state-of-the-art agent retriever) on LiveMCPBench.
- +17.7% improvement in nDCG@5 compared to MCPZero on LiveMCPBench.
- Consistently outperforms baselines across 8 different embedding models (e.g., +28% Recall@5 gain with Amazon Titan v2).
Breakthrough Assessment
7/10
Strong practical improvement for the specific problem of routing in large multi-agent ecosystems (MCP). While the architectural change is straightforward (unified index + aggregation), the consistent empirical gains across many models validate its effectiveness.