📝 Paper Summary
Multi-call tool use with flexible plan
Multi-task planning
DTA-Llama transforms sequential tool invocation into parallelizable 'Process/Threads' execution by restructuring training data into Directed Acyclic Graphs, significantly reducing inference latency and token costs.
Core Problem
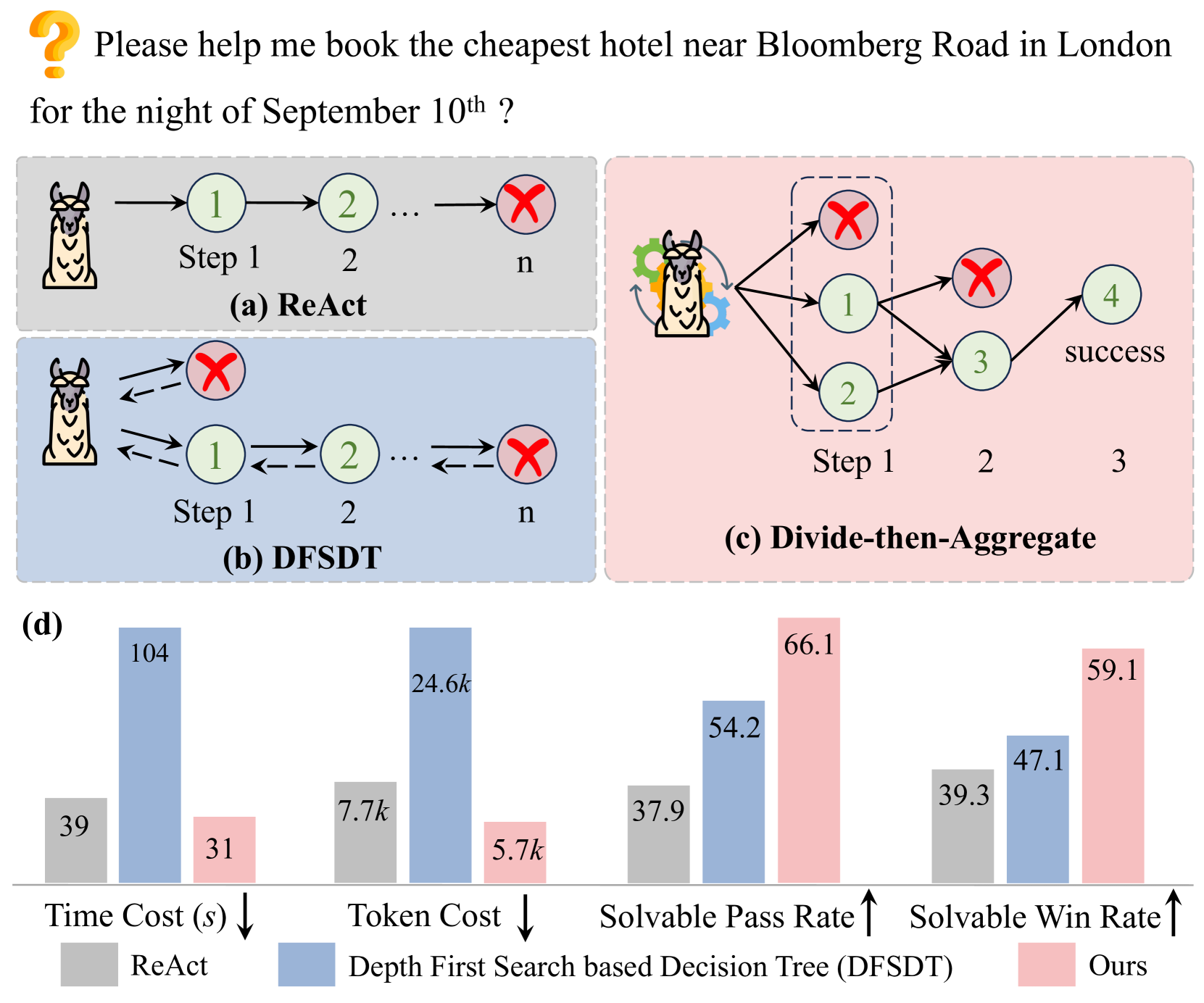
Existing tool learning methods (CoT, ReAct, DFSDT) execute tools sequentially or use backtracking search trees, leading to limited perceptual scope, high token consumption, and slow inference speeds.
Why it matters:
- Sequential invocation forces LLMs to wait for each tool result before planning the next step, preventing efficiency gains from parallelizable sub-tasks.
- Tree-based methods like ToolLLM improve success rates via backtracking but incur massive computational overhead and latency, making them impractical for real-time applications.
- Real-world complex tasks often contain independent components (e.g., booking two different flights) that current serial agents handle inefficiently.
Concrete Example:
In a task requiring weather checks for both 'Beijing' and 'Shanghai', a ReAct agent queries Beijing, waits for the result, then queries Shanghai. DTA-Llama identifies these as independent sub-tasks and queries both API endpoints simultaneously.
Key Novelty
Divide-Then-Aggregate (DTA) Parallel Tool Invocation
- Replaces the 'Thought-Action-Observation' loop with a 'Process-Threads-Aggregate' mechanism where the LLM (Process) generates a batch of parallelizable tool calls.
- Executes these calls concurrently in separate Threads and uses an intermediate state lock to wait for all results before aggregating them back to the LLM.
- Constructs training data by converting serial successful paths from tree-search methods into Directed Acyclic Graphs (DAGs) using GPT-4, identifying parallelizable nodes.
Architecture
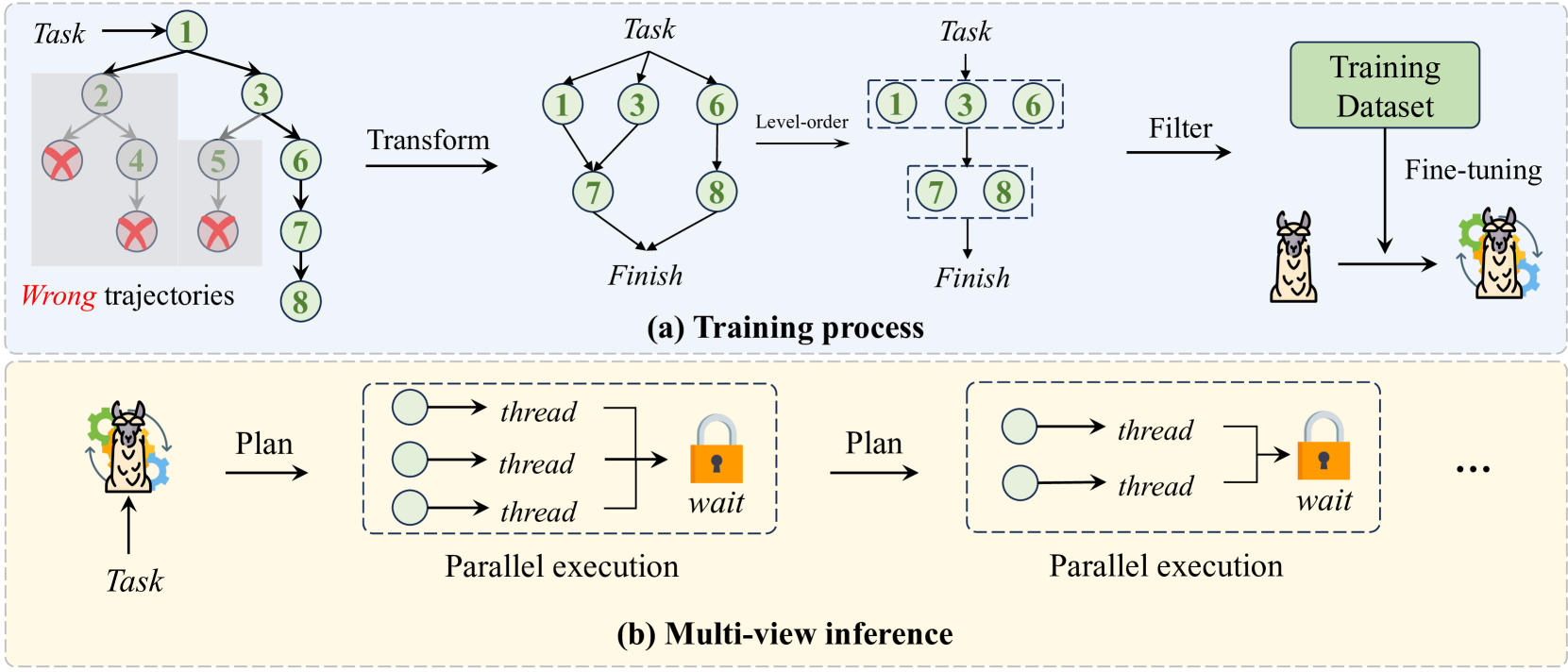
The overall framework of DTA-Llama, contrasting the data construction phase (DAG transformation) and the inference phase (Process/Threads mechanism).
Evaluation Highlights
- Achieves 83.35% Solvable Pass Rate (SoPR) on StableToolBench, surpassing ToolLLM (DFSDT) while using significantly fewer tokens.
- Reduces average inference time by ~2.5x compared to ToolLLM (DFSDT) and ~1.5x compared to standard CoT methods.
- Llama-2-7B fine-tuned with DTA matches the performance of GPT-3.5-Turbo's official parallel function calling capability.
Breakthrough Assessment
8/10
Offers a highly practical solution to the efficiency bottleneck in tool-using agents. The shift from serial/tree search to DAG-based parallel execution is a logical and effective step forward.