📝 Paper Summary
Conversational Recommender Systems (CRS)
Agentic RAG pipeline
Music Information Retrieval (MIR)
TalkPlay-Tools unifies diverse music retrieval methods (SQL, BM25, embeddings, Semantic IDs) into a single LLM agent that autonomously plans tool execution sequences to improve zero-shot conversational recommendation.
Core Problem
Relying on a single retrieval method fails to capture complex user needs that require combining metadata constraints, semantic understanding, and acoustic features simultaneously.
Why it matters:
- Production systems must satisfy strict operational constraints (e.g., specific genre or release year) while also understanding abstract user intent
- Existing generative recommenders often underutilize simpler but crucial metadata filtering, leading to recommendations that miss hard constraints
- Without combining retrieval types (e.g., lyrics search vs. audio similarity), systems cannot fully capture multimodal contexts like 'sad songs from the 90s with piano'
Concrete Example:
A user asks for 'upbeat rock songs from 2020'. A purely semantic dense retriever might find upbeat rock songs but miss the '2020' filter. A purely metadata-based system might miss the 'upbeat' nuance. TalkPlay-Tools combines SQL for the date and dense retrieval/BM25 for the mood.
Key Novelty
TalkPlay-Tools: Unified Agentic Retrieval-Reranking
- Orchestrates a comprehensive suite of tools—SQL (metadata), BM25 (text), Dense Retrieval (multimodal), and Semantic IDs (generative)—under a single LLM agent
- Decomposes recommendation into a three-stage 'Plan → Retrieve → Rerank' workflow where the LLM explicitly selects tools and arguments based on user profile and dialogue history
- Leverages Semantic IDs (quantized content codes) as a distinct retrieval tool, allowing the LLM to retrieve items based on learned multimodal representations alongside traditional database queries
Architecture
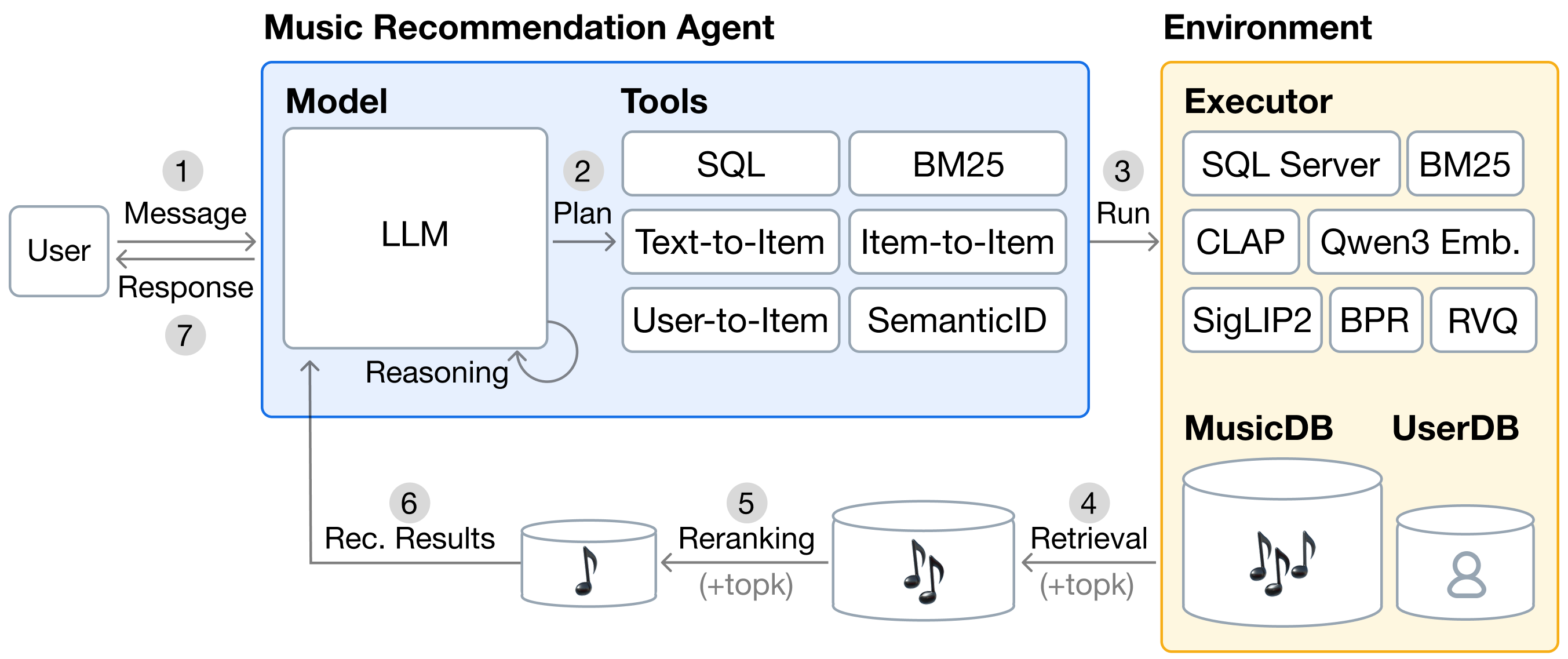
The Music Recommendation Agent workflow interacting with the External Environment
Evaluation Highlights
- Achieves 0.022 Hit@1 in zero-shot conversational recommendation, outperforming the Qwen3-LM + BM25 baseline (0.018)
- Demonstrates high success rates for novel tool types: 98.8% for User-to-Item personalization and 95.8% for Semantic ID retrieval, despite the LLM not being pre-trained on these specific identifiers
- Analysis reveals complementary tool usage: SQL/BM25 are favored for natural language queries, while specialized tools are successfully invoked when conditioned on user history
Breakthrough Assessment
7/10
Strong engineering of a unified agentic framework for music. While the Hit@1 absolute numbers seem low, the effective integration of diverse modalities (SQL to Semantic IDs) in a zero-shot setting is a significant architectural step.