📝 Paper Summary
Multi-call tool use with fixed plan
Tool profiling
Play2Prompt automatically generates tool-use examples and refines documentation by letting an LLM agent 'play' with tools through trial-and-error, enabling zero-shot tool use without human labeling.
Core Problem
Task LLMs struggle to use new tools zero-shot when documentation is noisy or incomplete, and existing optimization methods require labeled examples which are unavailable in true zero-shot settings.
Why it matters:
- Real-world users often provide minimal or poor documentation for custom tools, leading to hallucinations or syntax errors
- Creating labeled tool-use demonstrations manually is unscalable for non-expert users
- Current automatic prompt optimization techniques rely on seed examples, failing when no prior data exists
Concrete Example:
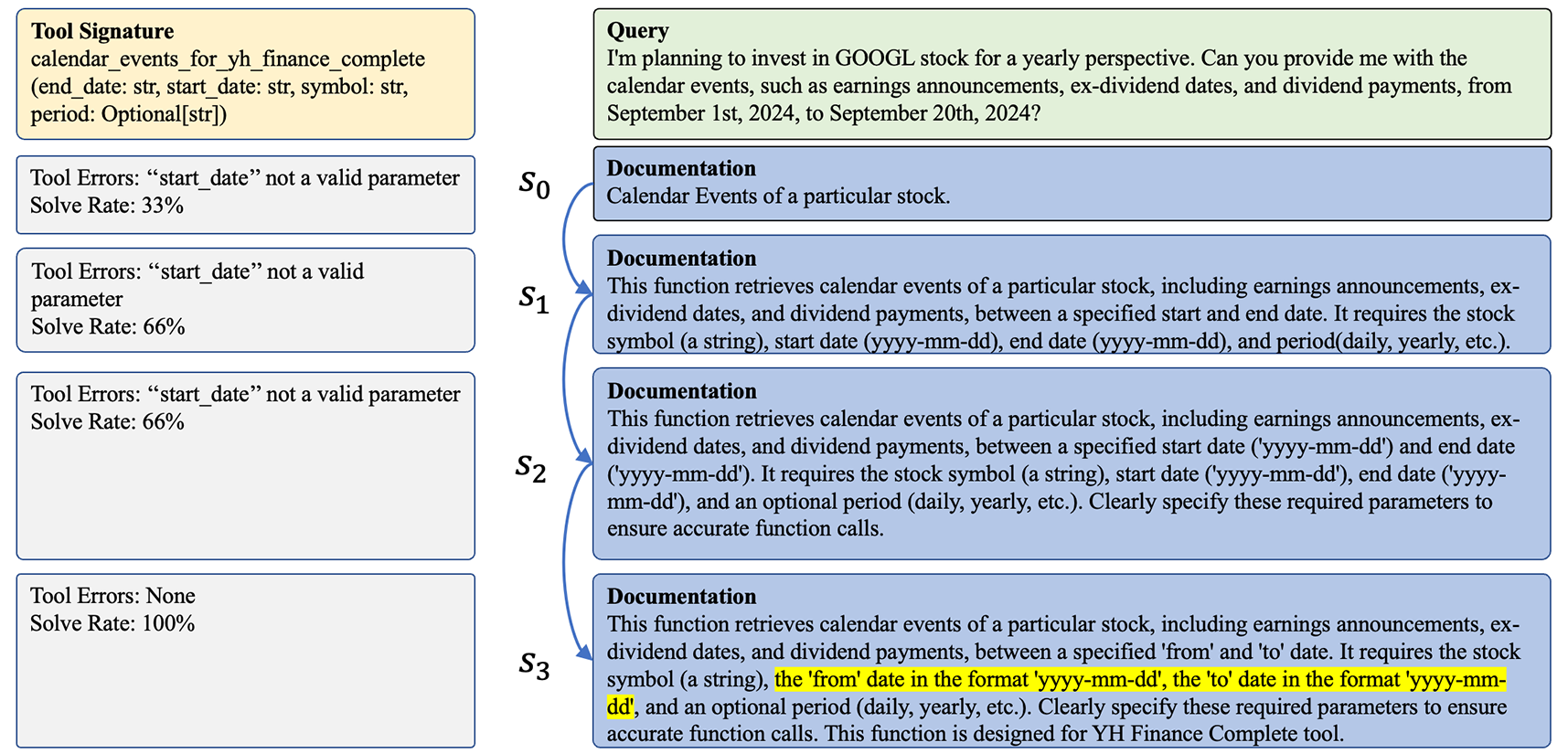
If a user provides a tool `get_stock_price` with vague docs lacking required parameter formats, a standard zero-shot LLM might hallucinate parameters or fail. Play2Prompt trial-runs the tool until it works, then reverse-engineers a query like 'What is the price of AAPL?' to create a valid example.
Key Novelty
Play2Prompt (Zero-shot Tool Play Framework)
- Systematically 'plays' with tools using trial-and-error to discover valid input parameters and observe outputs without any initial labeled data
- Generates synthetic tool-use examples in reverse: first find a valid tool call, then generate a corresponding user query that would trigger it
- Uses these synthetic examples as a validation set to refine the tool documentation itself via a beam search optimization process
Architecture
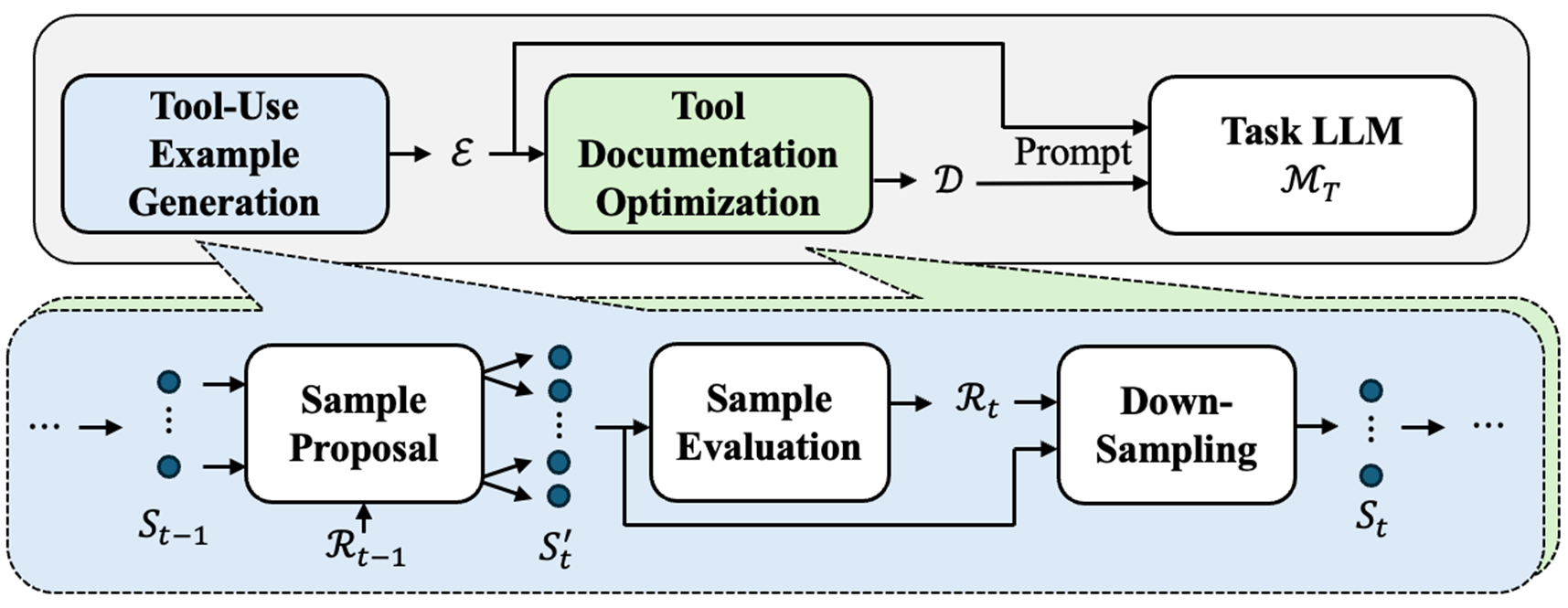
The Play2Prompt framework workflow, divided into Step 1 (Tool-Use Example Generation) and Step 2 (Tool Documentation Optimization).
Evaluation Highlights
- +13.3% accuracy improvement on Berkeley Function-Calling Leaderboard (BFCL) using Llama-3.1-8B-Instruct compared to zero-shot baseline
- Outperforms standard zero-shot prompting on StableToolBench across varying documentation quality levels (80%, 60%, 40% retained info)
- Surpasses concurrent baseline Tool-Be-Honest by 8.4% on BFCL with Llama-3.1-8B-Instruct
Breakthrough Assessment
7/10
Clever application of 'tool play' (exploration) to solve the cold-start problem in tool use. Robust gains across open/closed models, but relies on the assumption that tools are safe to execute during exploration.