📝 Paper Summary
Multi-call tool use with flexible plan
Benchmark datasets
ToolMATH is a benchmark that converts math solution steps into reusable tools to evaluate how well language models handle long sequences of dependent tool calls amidst large, distracting tool catalogs.
Core Problem
Current tool-use benchmarks often assume small, clean tool sets with intended capabilities present, failing to test model reliability under realistic conditions like large overlapping catalogs, missing tools, and long-horizon dependencies.
Why it matters:
- Real-world deployments involve retrieval from large API libraries where many tools look similar but only some are relevant
- Models must safely handle scenarios where the required tool is missing rather than hallucinating actions
- Sequential tool use is brittle; early errors in multi-step plans propagate, causing irreversible drift in long-horizon tasks
Concrete Example:
A math problem requiring sequential calculation might fail because a model selects a 'distractor' tool (e.g., a similar but incorrect linear solver) early in the chain, causing all subsequent steps to process invalid intermediate results.
Key Novelty
Math-Grounded Multi-Step Tool Benchmark (ToolMATH)
- Converts stepwise MATH dataset solutions into 12k+ reusable Python tools, creating a correctness-checkable environment for long-horizon planning
- Introduces 'Distractors-only' regime to explicitly test model behavior when necessary tools are absent (tool insufficiency)
- Controls difficulty via 'logical hop' count and distractor similarity levels (random vs. retrieval-based overlap) to isolate planning failures from retrieval failures
Architecture
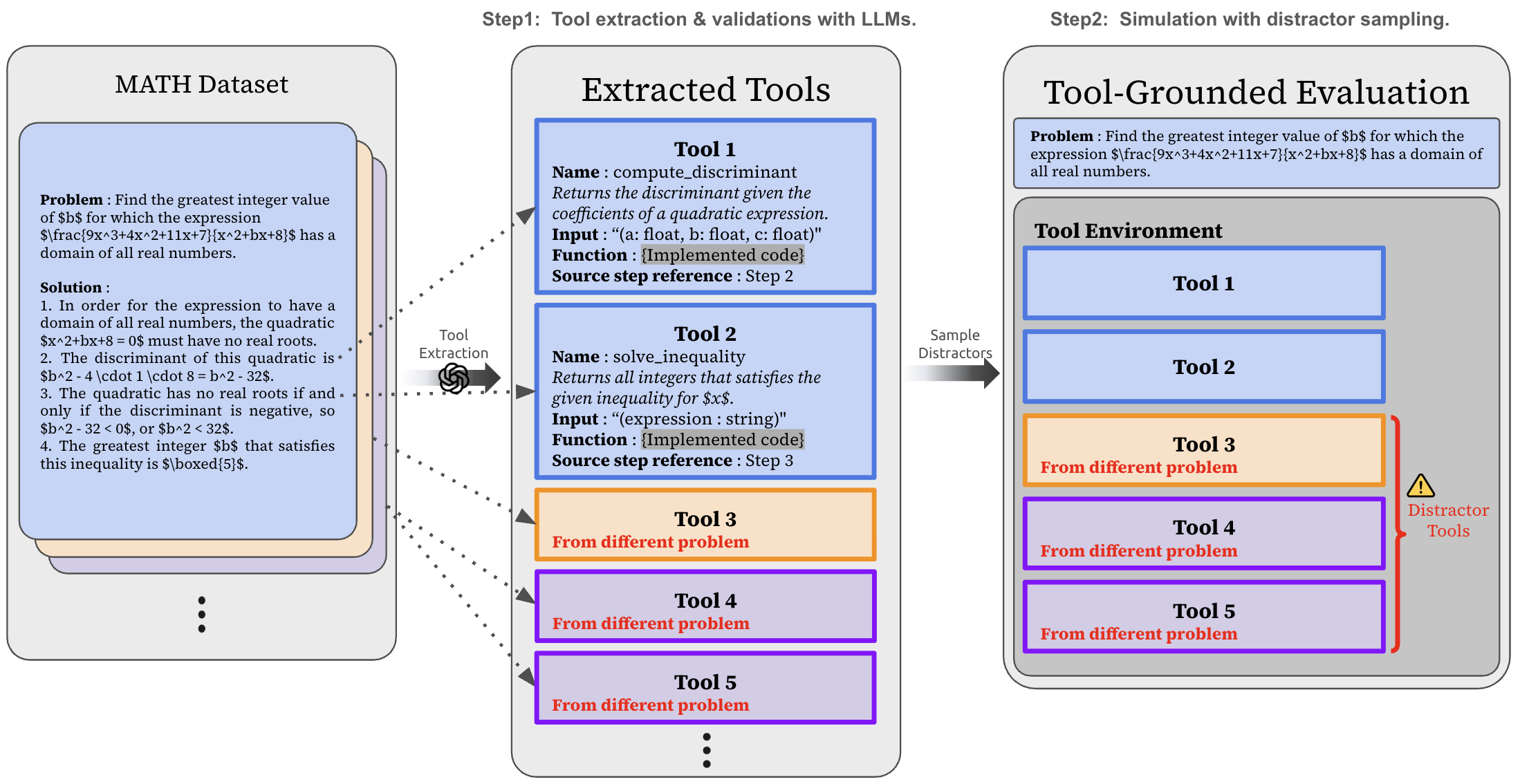
The pipeline for converting MATH solution steps into the ToolMATH benchmark environment.
Evaluation Highlights
- Analysis reveals that tool-list redundancy amplifies small early deviations into irreversible execution drift rather than just adding noise
- In 'Distractors-only' settings (gold tools removed), models often fail to recognize missing capabilities, leading to ungrounded tool trajectories
- Improvements in performance come less from local action selection and more from long-range plan coherence and disciplined observation use
Breakthrough Assessment
8/10
Significantly advances tool-use evaluation by rigorously isolating long-horizon dependency failures and missing-tool behavior, areas often neglected in favor of simple function-calling accuracy.