📝 Paper Summary
Modularized RAG pipeline
This paper proposes a lightweight, LLM-independent adaptive retrieval mechanism that uses external features like entity popularity and question type to predict when retrieval is necessary, avoiding costly LLM-based uncertainty estimation.
Core Problem
Existing adaptive retrieval methods rely on heavy LLM-based uncertainty estimation (analyzing internal states or outputs) to decide when to retrieve, which creates significant computational overhead that negates efficiency gains.
Why it matters:
- LLM-based uncertainty checks are computationally expensive, often requiring multiple generations or access to internal states, which limits scalability
- Current methods struggle with complex reasoning questions where simple uncertainty heuristics fail
- Real-world applications need efficient RAG systems that don't double the inference cost just to decide whether to search
Concrete Example:
For a simple question about a very popular entity (e.g., 'Who is the president of the USA?'), an LLM-based adaptive RAG might still run expensive self-consistency checks to decide not to retrieve. The proposed method would instantly flag the entity as 'popular' via pre-computed stats and skip retrieval without querying the LLM.
Key Novelty
LLM-Independent External Features for Adaptive Retrieval
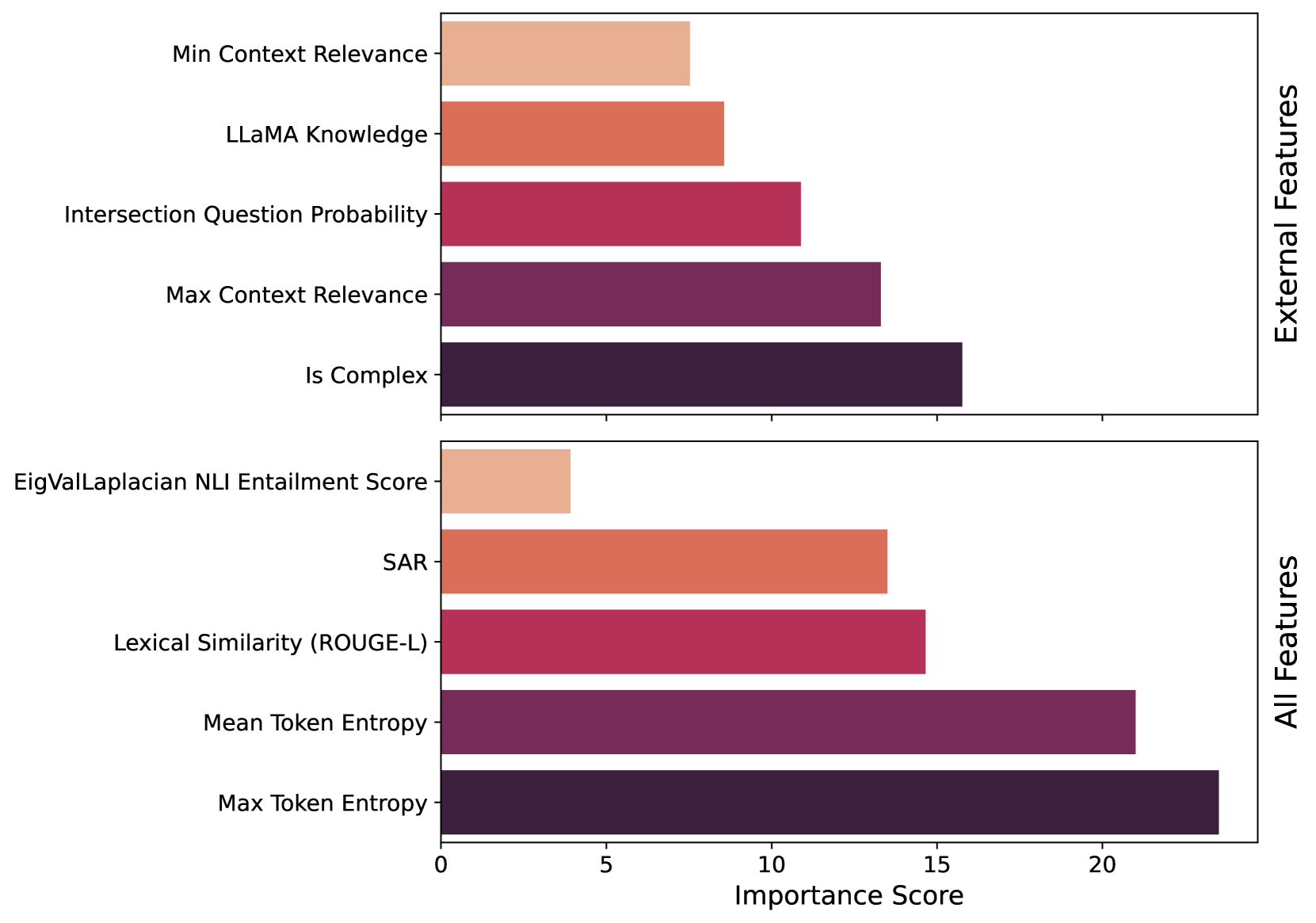
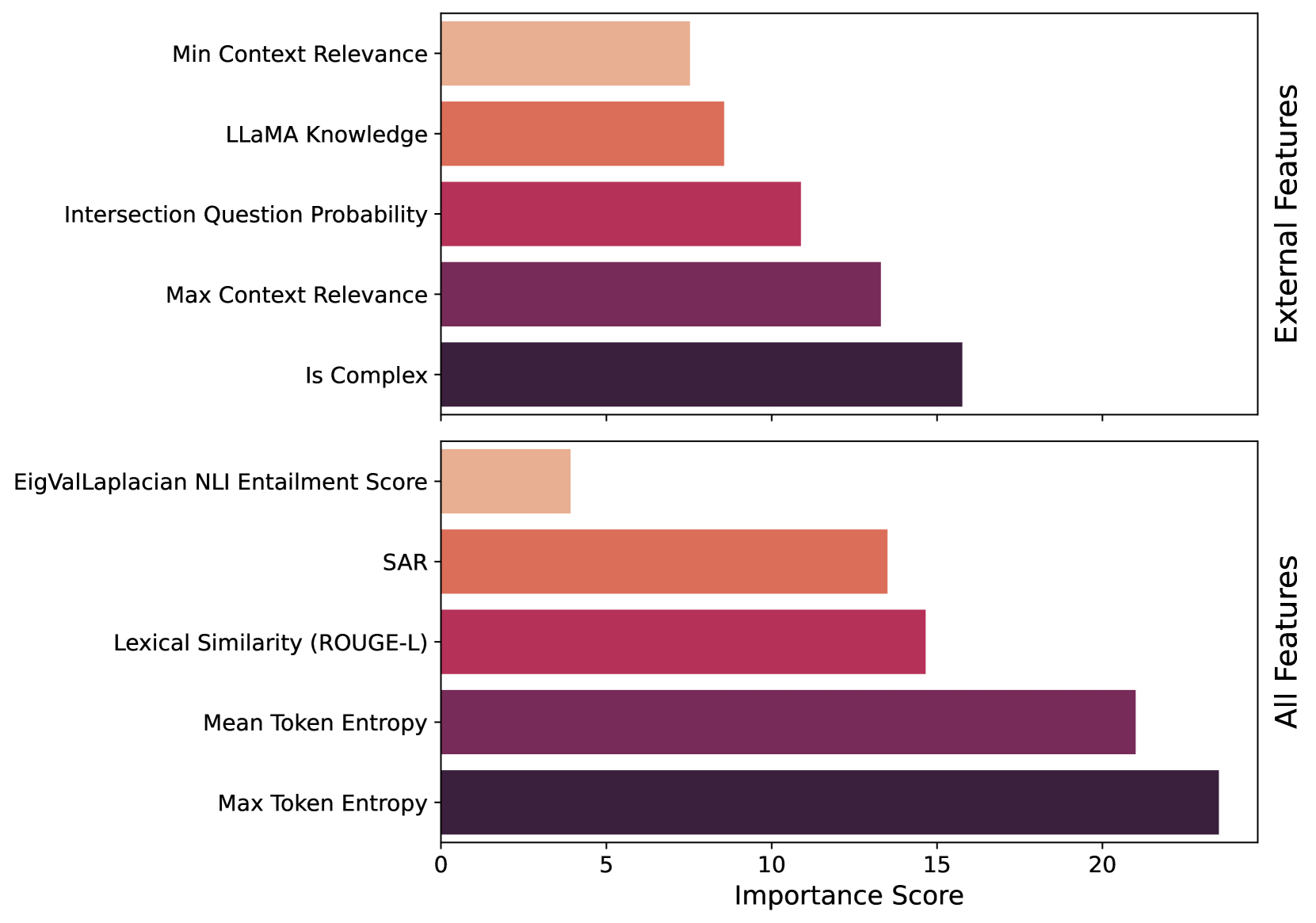
- Replace expensive LLM-based uncertainty checks with lightweight classifiers trained on 27 external features organized into 7 groups (e.g., entity popularity, graph connectivity, question type)
- Leverage pre-computed knowledge (like Wikipedia page views or KG triple counts) to approximate 'known' vs. 'unknown' information without needing the LLM to self-reflect during inference
Architecture
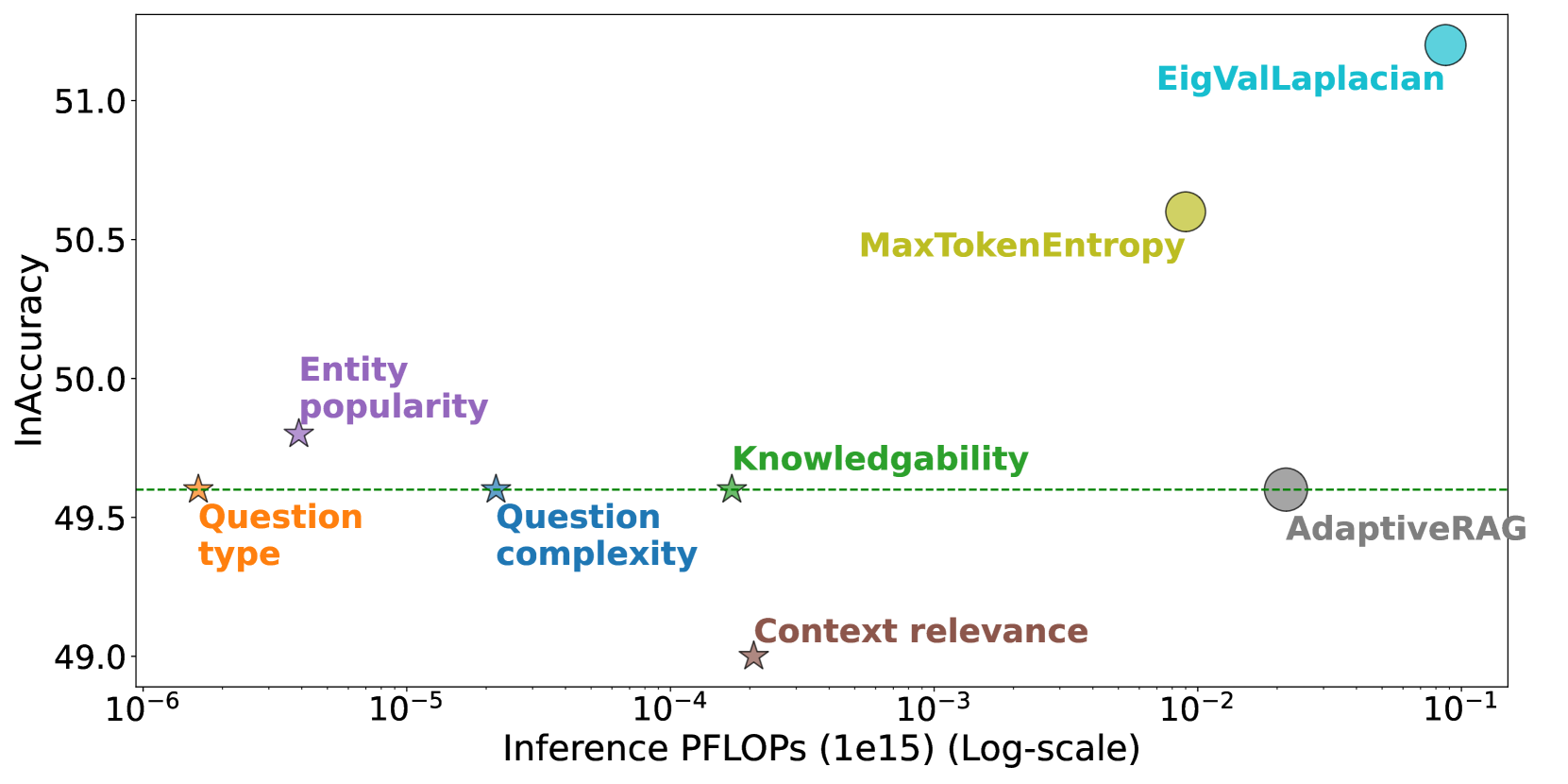
Efficiency (PFLOPs) vs. Performance (In-Accuracy) trade-off for various adaptive retrieval methods. The x-axis is PFLOPs (log scale) and y-axis is In-Accuracy.
Evaluation Highlights
- External feature classifiers match the QA performance of complex LLM-based uncertainty methods across 6 datasets while using significantly fewer FLOPs
- Combining external features improves In-Accuracy on the complex MuSiQue dataset compared to uncertainty baselines
- Drastically reduces computational cost by eliminating LLM calls for the retrieval decision step (0 LLM calls for decision vs. 1+ for baselines)
Breakthrough Assessment
7/10
Strong practical contribution. While not a new model architecture, it demonstrates that simple external signals can replace expensive LLM introspection for adaptive RAG, offering a clear efficiency breakthrough.