📝 Paper Summary
Tool Retrieval
Agentic AI
MFTR improves tool retrieval by standardizing heterogeneous documentation into four functional fields and rewriting user queries to strictly align with this schema, enabling fine-grained multi-aspect relevance scoring.
Core Problem
Traditional retrieval treats tools as flat text, failing to address the structural inconsistency of documentation, the semantic mismatch between high-level user queries and atomic tools, and the strict constraints of parameter validity.
Why it matters:
- LLM context windows cannot fit all available tools, making retrieval the bottleneck for general-purpose agents
- Existing ad-hoc retrieval methods rely on semantic similarity, which ignores whether a tool is actually executable (e.g., missing required parameters)
- Documentation from different sources (e.g., Gorilla vs. MetaTool) is highly heterogeneous, confusing standard retrievers
Concrete Example:
A user asks to 'analyze sales trends', which implies multiple tools (retrieval, analysis, plotting). A standard retriever might miss the specific 'plot_chart' tool because its documentation is purely technical (parameter names) without high-level descriptions, or retrieve a tool for which the user lacks the required input ID.
Key Novelty
Multi-Field Tool Retrieval (MFTR) Framework
- Standardize all tool docs into a 4-field schema (Description, Parameters, Response, Examples) using an LLM to normalize heterogeneous sources
- Rewrite user queries into 'Tool Needs' that map directly to these 4 fields, using Pseudo-Relevance Feedback to inject repository-specific terminology
- Calculate relevance independently for each field (including a specific penalty mechanism for missing required parameters) and aggregate them with learnable weights
Architecture
The MFTR framework pipeline showing the two parallel paths: tool documentation standardization and query rewriting, meeting at the multi-field relevance computation.
Evaluation Highlights
- Achieves SOTA performance on five datasets and a mixed benchmark (specific numbers not reported in the provided text)
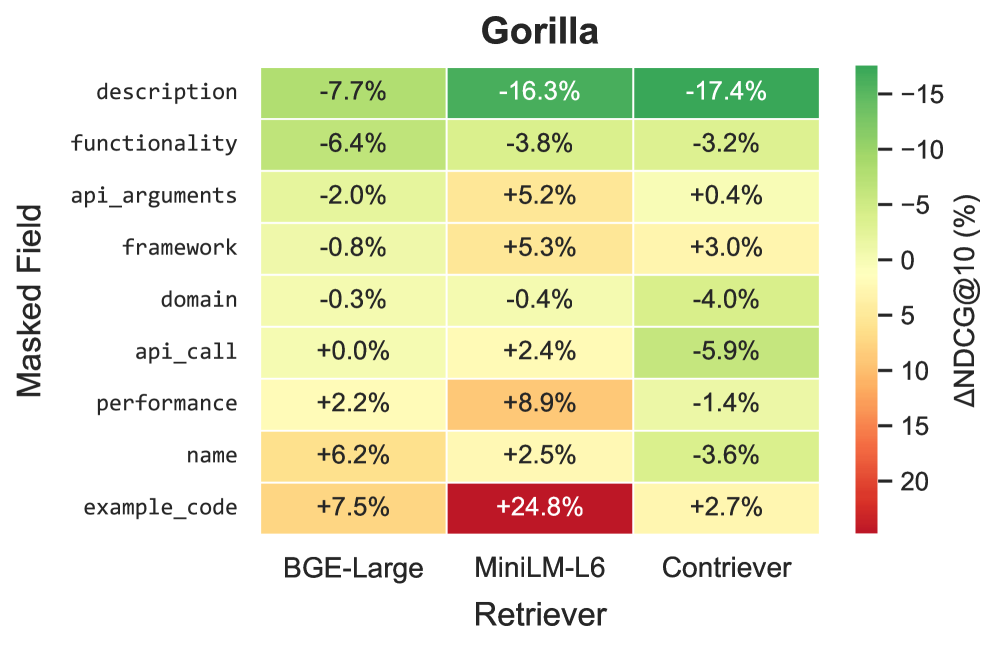
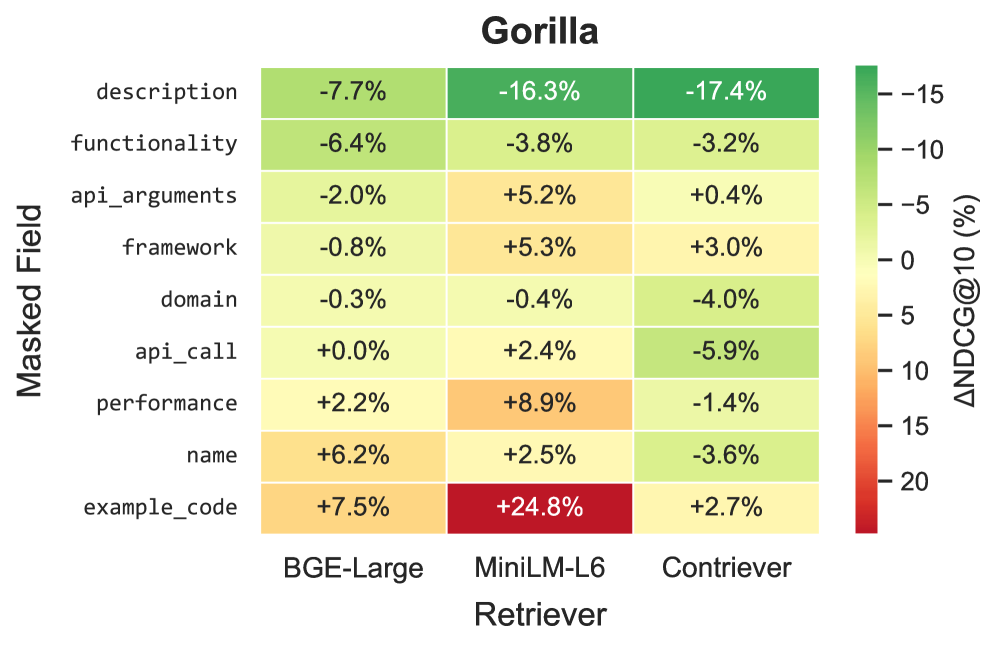
- Demonstrates that masking different documentation fields has varying impacts on retrieval, validating the need for multi-field modeling (Figure 1)
- Successfully generalizes across different retriever backbones by decoupling structural alignment from the underlying scoring model
Breakthrough Assessment
7/10
Strong methodological contribution in recognizing tools != documents. The standardization and field-specific scoring address real pain points. Score limited only by lack of numeric results in the provided text to verify the magnitude of improvement.