📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
Re-Invoke improves zero-shot tool retrieval by using LLMs to enrich tool documents with synthetic queries and decompose complex user requests into specific intents before matching.
Core Problem
Accurately retrieving relevant tools from large, evolving toolsets is difficult because user queries are often ambiguous or verbose, and tool documentation is frequently vague or incomplete.
Why it matters:
- LLMs have token limits that prevent including all available tools in the prompt context
- Maintaining labeled datasets for constantly changing tool pools is impractical, making supervised training difficult
- Ambiguous user contexts often lead standard retrievers to select irrelevant tools based on superficial similarities
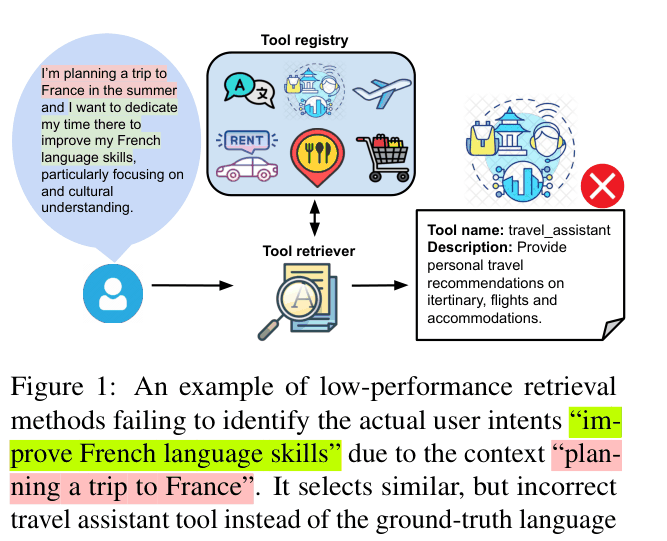
Concrete Example:
A user asks about 'improving French skills' while 'planning a trip to France'. A standard retriever selects a 'travel_assistant' tool because of the 'France' keyword, missing the actual intent which requires a language learning tool.
Key Novelty
Unsupervised Multi-View Tool Retrieval
- Enhances tool documents offline by generating diverse synthetic user queries that the tool could answer, bridging the gap between technical descriptions and user language
- Extracts clean, tool-specific intents from verbose user queries at inference time to remove irrelevant context
- Ranks tools by aggregating similarity scores across multiple views (intents) rather than a single vector match
Architecture
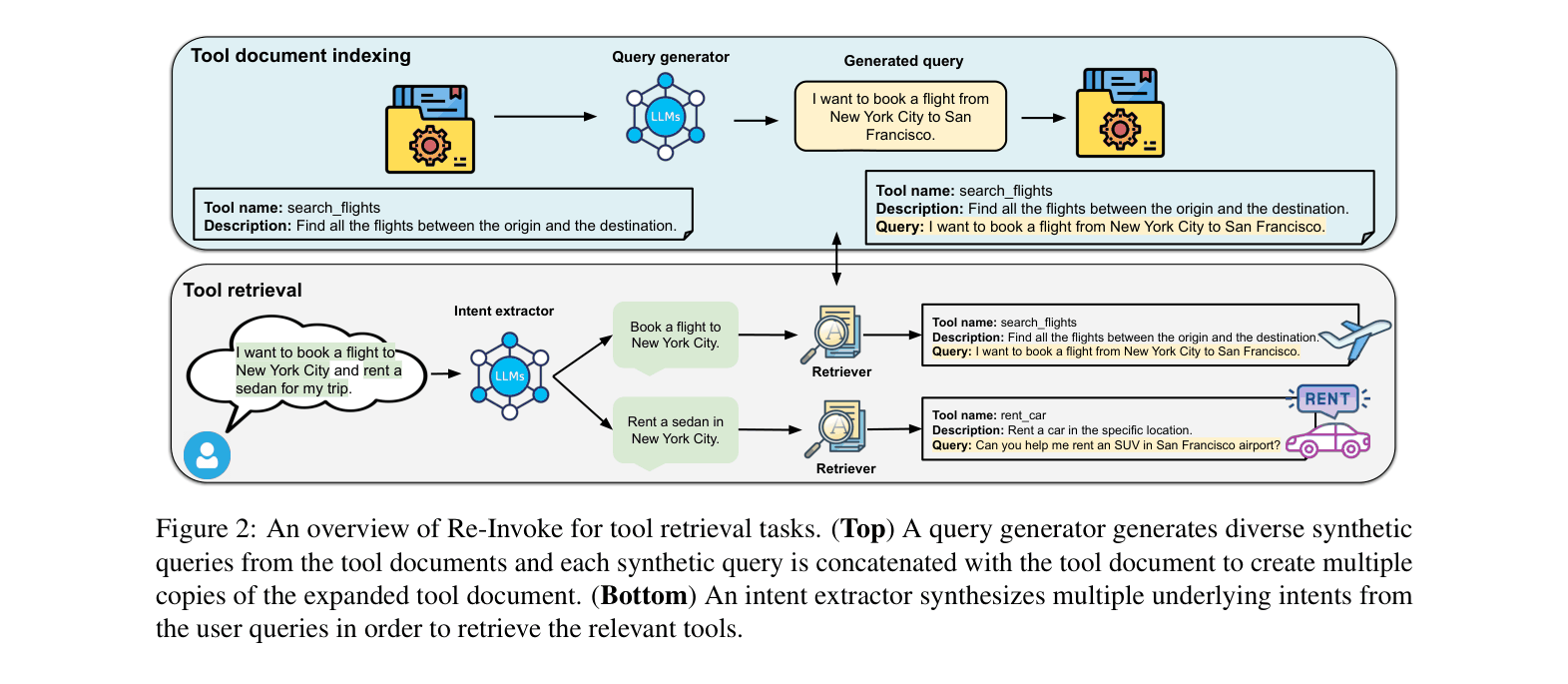
Overview of the Re-Invoke pipeline showing the offline indexing phase and online retrieval phase.
Evaluation Highlights
- Achieves 20% relative improvement in nDCG@5 for single-tool retrieval on ToolE datasets compared to state-of-the-art baselines
- Achieves 39% relative improvement in nDCG@5 for multi-tool retrieval on ToolE datasets
- Outperforms supervised retrievers (ToolLLM) in end-to-end agent pass rates on ToolBench without requiring any training data
Breakthrough Assessment
7/10
Strong practical contribution for zero-shot scenarios. Effectively solves the 'vague documentation' problem without training, though the core techniques (query expansion/rewriting) are known in general IR.