📝 Paper Summary
Memory organization
Self-evolving Agentic reasoning
The framework amortizes the high cost of iterative self-correction by distilling transient feedback into persistent, file-based guidelines that agents retrieve to improve future performance zero-shot.
Core Problem
Iterative self-correction ('System 2' reasoning) is computationally expensive and episodic; models 'forget' improvements once the context closes, forcing them to re-derive the same corrections for every new query.
Why it matters:
- Massive redundancy occurs when models frequently re-derive the same insights for similar tasks, wasting compute
- Fine-tuning is too costly and inflexible for adapting rapidly to user-defined rubrics
- Standard context-based reasoning treats interactions in isolation, failing to consolidate 'lessons learned' over time
Concrete Example:
A model fails to use 'synesthetic language' in a creative writing task. Standard methods critique and fix it, but the lesson is lost next time. This framework writes 'Prioritize synesthetic blending' to a file, enabling the model to retrieve and apply this rule zero-shot in future tasks.
Key Novelty
Memory-as-a-Tool
- Treats memory as a file system managed via tools ('ls', 'read_file', 'write_file') rather than a passive vector database
- Requires the LLM to actively 'abstract' raw feedback into generalizable principles before writing them to files
- Amortizes the cost of reasoning: the expensive critique happens once, but the resulting 'lesson' file aids all future generations at low cost
Architecture
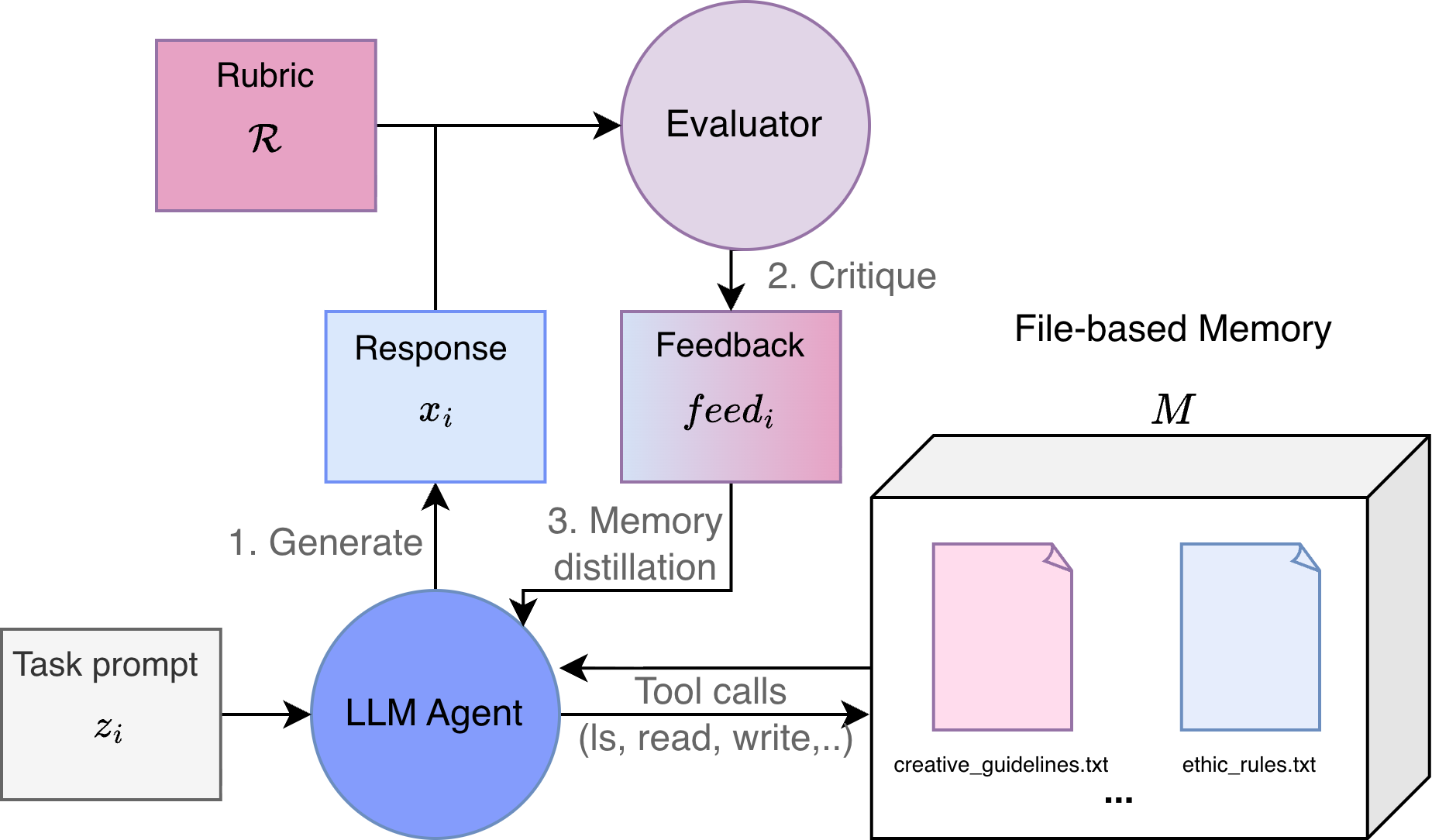
Diagrammatic representation of the complete generation and learning process
Evaluation Highlights
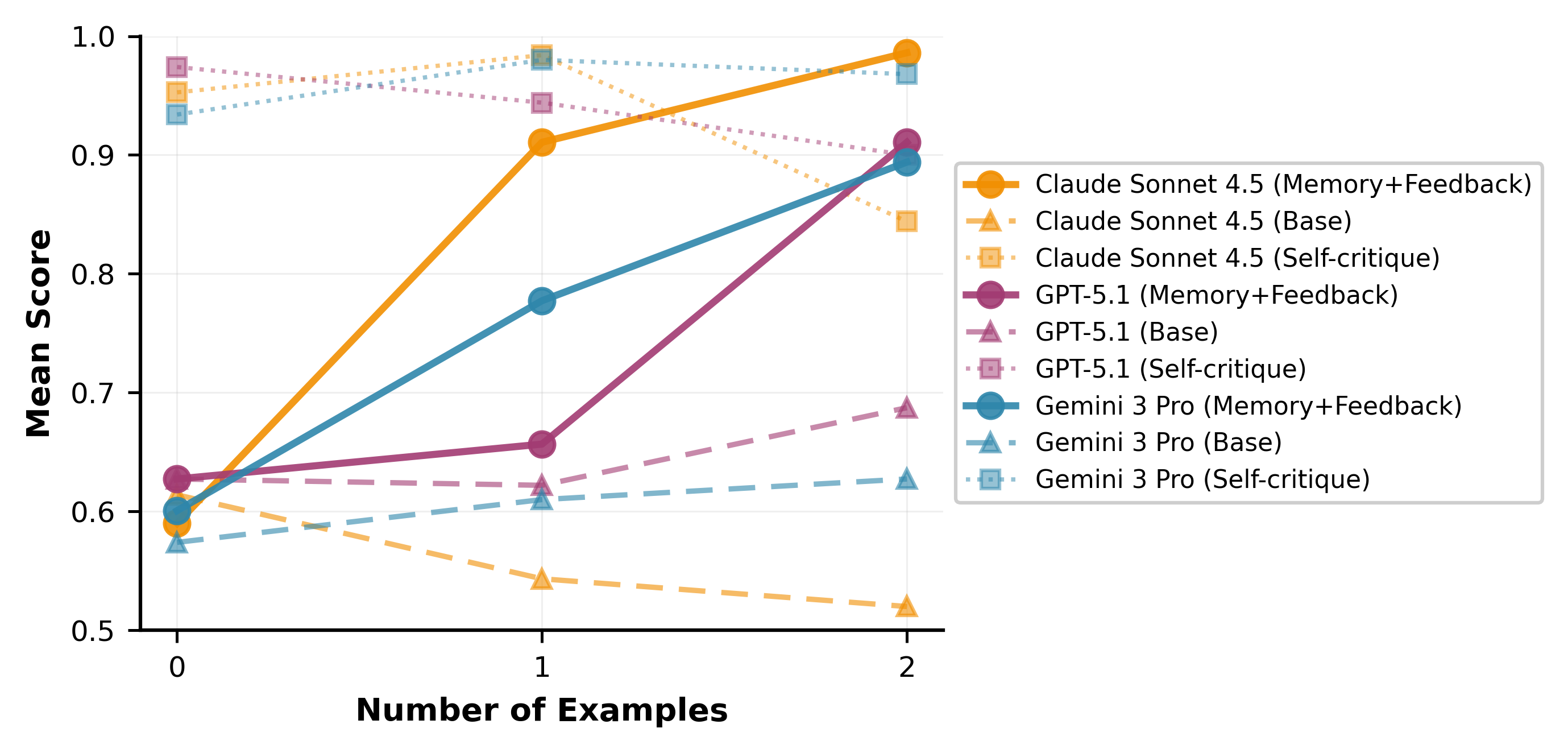
- Matches or exceeds compute-heavy 'Self-Critique' performance after just 2 rounds of feedback on the Rubric Feedback Bench
- Maintains performance on a long horizon of 12 mixed/interleaved tasks, accumulating 8 memory files without forgetting
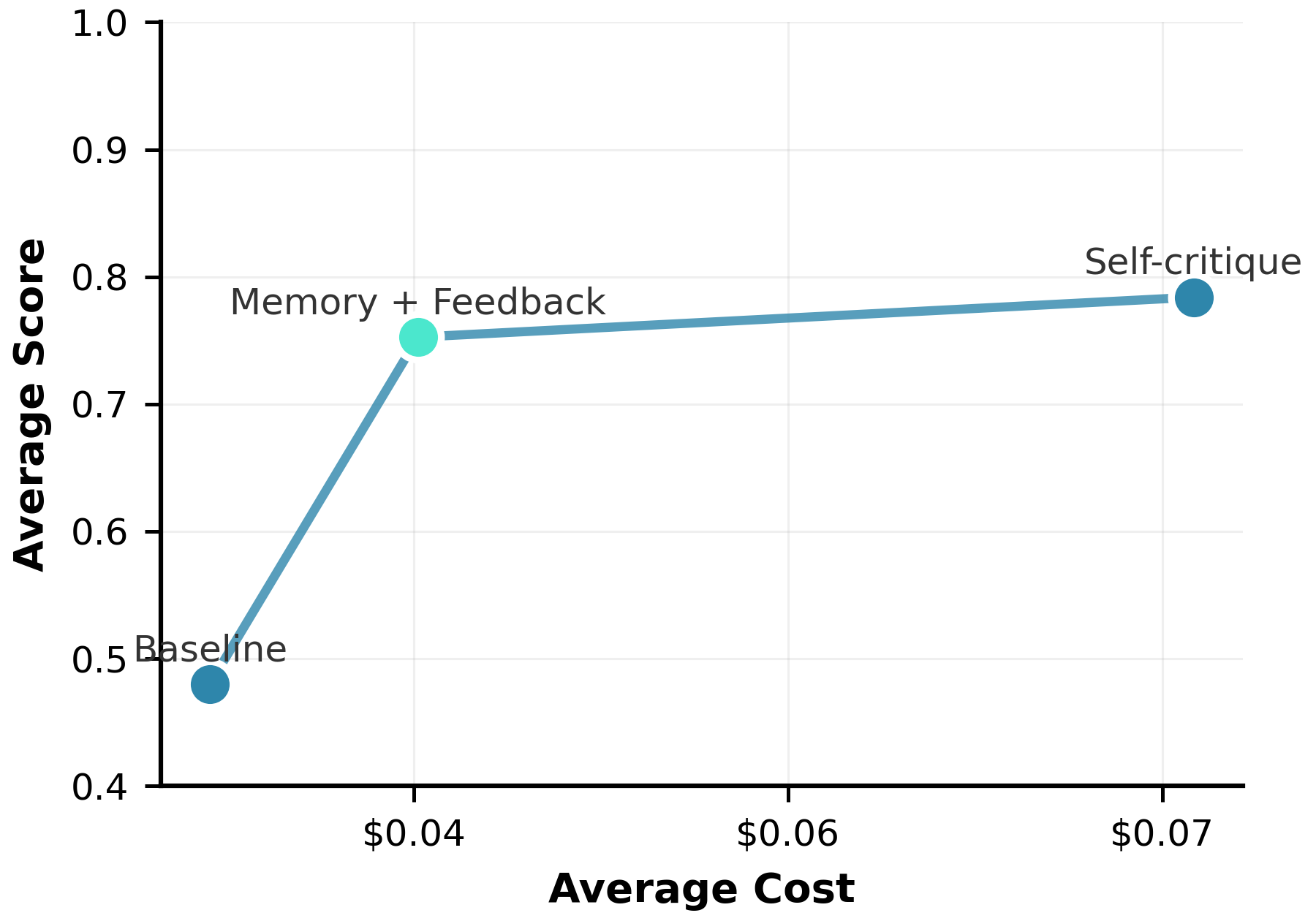
- Achieves a Pareto-optimal trade-off: comparable scores to iterative refinement but with inference costs much closer to the zero-shot baseline
Breakthrough Assessment
8/10
Novel framing of memory as an explicit file-system tool for consolidating abstract principles. Effectively solves the 'forgetting' problem of inference-time compute while drastically reducing costs.