📝 Paper Summary
Explainable AI (XAI)
Neuro-symbolic AI
Computational Argumentation
ArgLLMs augment Large Language Models with formal argumentation frameworks to produce decisions that are deterministically computed, faithfully explainable, and formally contestable.
Core Problem
LLMs often act as black boxes, providing outputs without faithful explanations of their reasoning or mechanisms for users to reliably contest and correct mistakes.
Why it matters:
- LLMs suffer from hallucinations and logical inconsistencies, making unverified outputs risky for high-stakes decision-making
- Current contestation methods (like re-prompting) are stochastic and provide no guarantee that user feedback will correct the reasoning
- Existing 'Chain-of-Thought' explanations are not necessarily faithful to the model's actual computation or the final output
Concrete Example:
A user might challenge an LLM's claim verification. With standard LLMs, prompting 'you are wrong because X' might randomly change the output or result in hallucinations. With ArgLLMs, a user can specifically attack a supporting argument (e.g., 'Evidence Y is unreliable'), and the system deterministically recalculates the claim's strength based on formal semantics.
Key Novelty
Argumentative LLMs (ArgLLMs)
- Uses the LLM to generate discrete pro/con arguments and their relationships (attacks/supports) rather than just a final answer
- Constructs a Quantitative Bipolar Argumentation Framework (QBAF) from these outputs, which is a symbolic graph of reasoning steps
- Computes the final decision deterministically using a gradual semantics algorithm (DF-QuAD) over the graph, ensuring the output mathematically follows from the generated arguments
Architecture
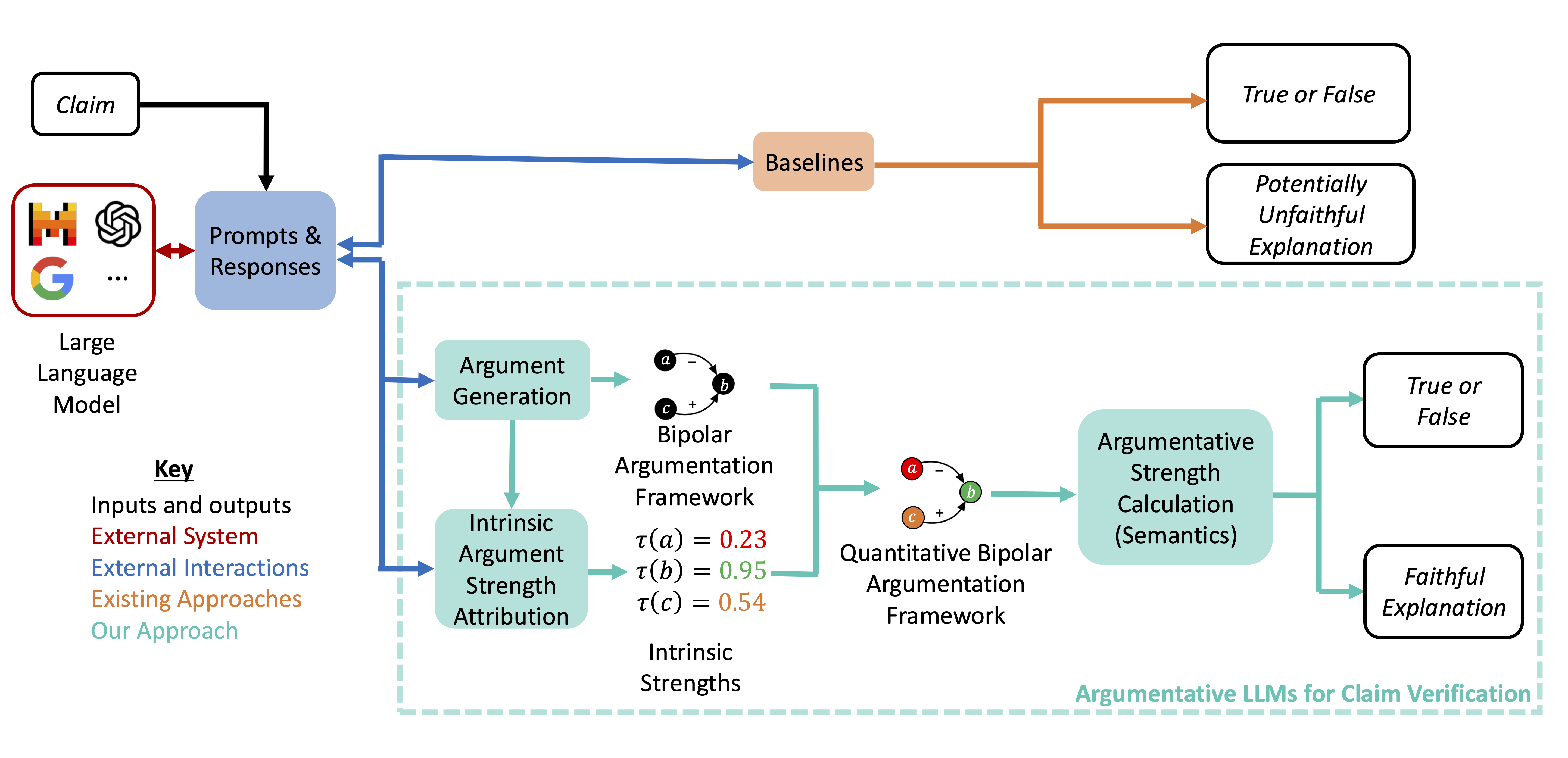
The complete ArgLLM pipeline from input to decision.
Evaluation Highlights
- Achieves comparable accuracy to Chain-of-Thought (CoT) prompting across three claim verification datasets (TruthfulQA, StrategyQA, MedQA), with differences often <1%
- Provides formal guarantees of contestability, proving that changing argument strengths or relations in the graph necessarily impacts the final evaluation
- Demonstrates high faithfulness because the final classification is a direct mathematical result of the visible argument graph, unlike black-box generation
Breakthrough Assessment
7/10
Provides a strong neuro-symbolic bridge for explainability and contestability without sacrificing significant performance compared to standard prompting. A solid step toward reliable AI decision-making.
