📝 Paper Summary
Masked Discrete Diffusion Models (MDMs)
Efficient Inference
Multimodal Generation and Understanding
Sparse-LaViDa accelerates Masked Discrete Diffusion Models by dynamically truncating redundant masked tokens during inference and using specialized register tokens to maintain generation quality.
Core Problem
Existing Masked Diffusion Models (MDMs) are inefficient because they must process the full sequence of tokens (including redundant masks) at every sampling step and cannot use KV-caching due to bidirectional attention requirements.
Why it matters:
- MDMs offer advantages like parallel decoding and bidirectional context but are computationally expensive compared to autoregressive models.
- Processing thousands of redundant masked tokens (e.g., 1024 tokens for an image when only a few are unmasked) wastes significant compute.
- Prior acceleration methods like Block Diffusion enforce left-to-right ordering, sacrificing the bidirectional context needed for image editing and inpainting.
Concrete Example:
If an image is represented by 1024 tokens, a standard MDM processes all 1024 tokens at every diffusion step, even if only a small subset is being unmasked. Sparse-LaViDa processes only the prompt, previously generated tokens, and the specific subset of masked tokens currently being decoded.
Key Novelty
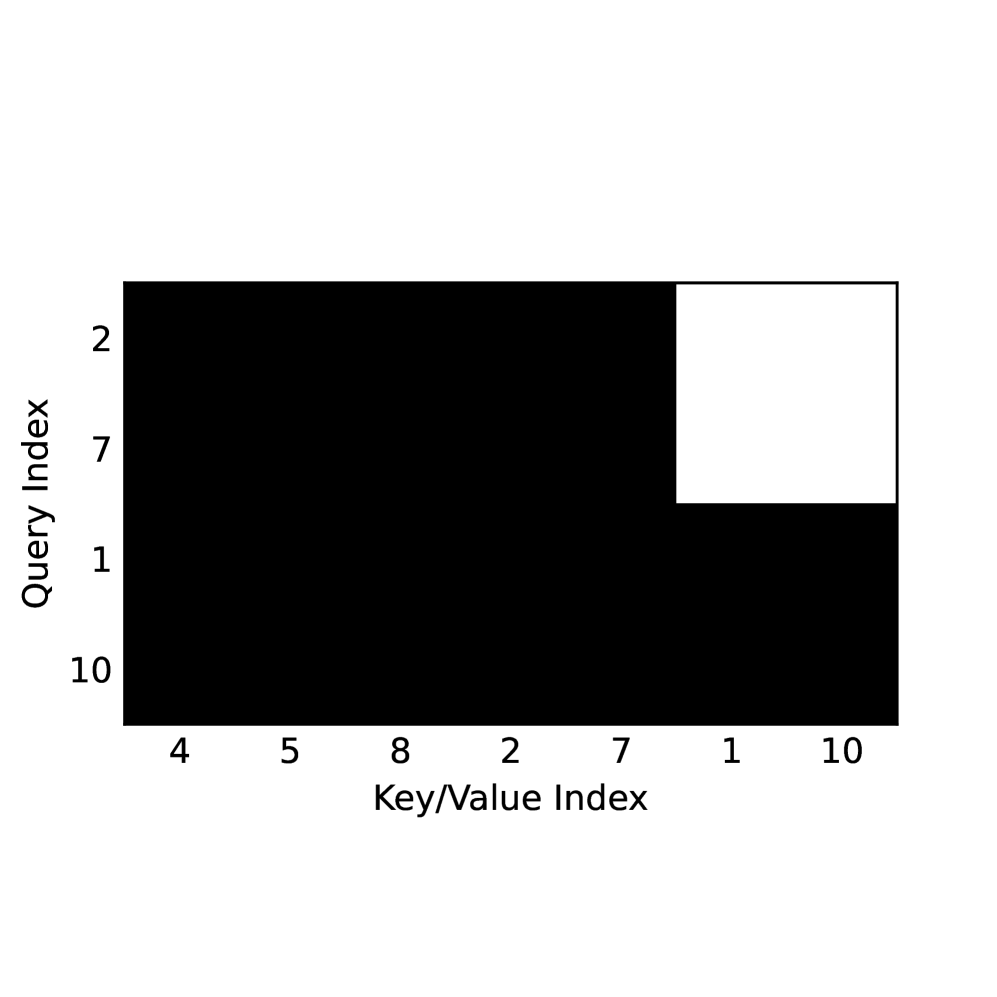
Sparse Parameterization with Step-Causal Masking
- Represents partially masked sequences sparsely: instead of materializing all masked tokens, the model only inputs tokens relevant to the current step (prompt + generated + current target masks).
- Uses 'register tokens' as compact summaries of the truncated masked regions to prevent loss of model capacity.
- Introduces a 'step-causal' attention mask that allows KV-caching (like AR models) while preserving the bidirectional context required for image tasks (unlike Block Diffusion).
Architecture
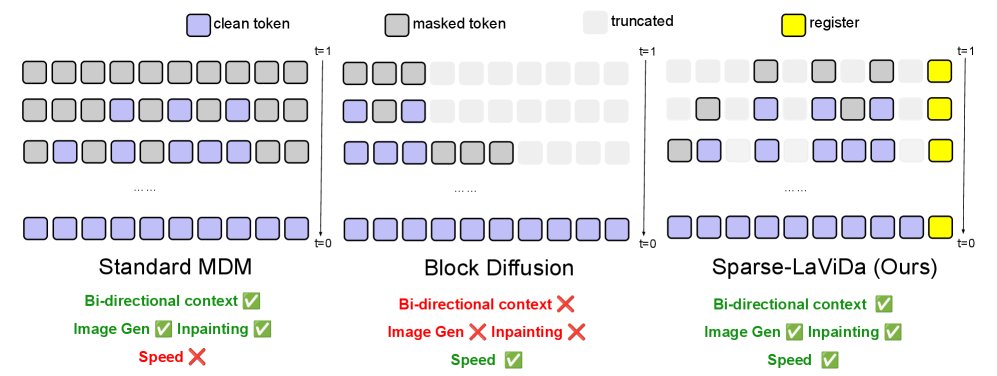
Comparison of inference paradigms: (Left) Standard MDM with full dense attention, (Middle) Block Diffusion with left-to-right causal masking, (Right) Sparse-LaViDa with sparse inputs and step-causal attention.
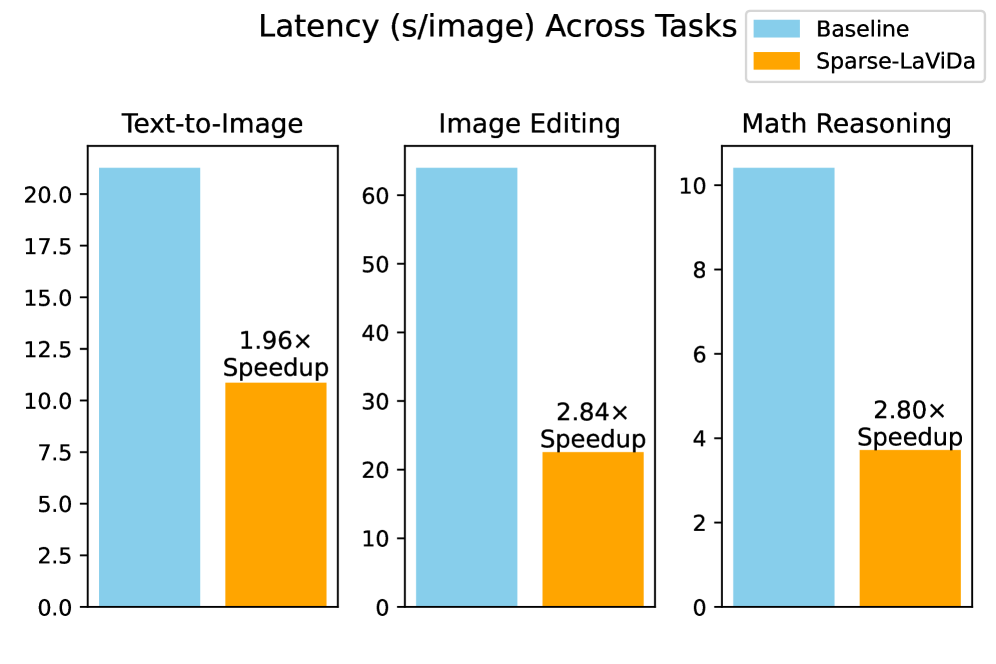
Evaluation Highlights
- Achieves 1.95x speedup on text-to-image generation (21.27s vs 10.86s) while maintaining comparable generation quality to LaViDa-O.
- Achieves 2.83x speedup on image editing tasks while improving accuracy (+0.08 on ImgEdit benchmark).
- Maintains strong performance on visual math reasoning (MathVista) with a 2.80x speedup compared to the dense baseline.
Breakthrough Assessment
8/10
Significant efficiency gains (approx 2-3x) for MDMs without sacrificing quality or bidirectional capabilities. addresses the primary bottleneck preventing MDMs from competing with AR models in speed.