📊 Experiments & Results
Evaluation Setup
Evaluation of visual token reduction on multimodal tasks.
Benchmarks:
- Benchmarks implicitly referenced via results (Visual Question Answering / Multimodal Understanding)
Metrics:
- Performance drop (%)
- Visual token reduction ratio (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance retention at high reduction ratios compared to state-of-the-art. | ||||
| LLaVA-OneVision-7B Evaluation | Performance Drop | 4.4 | 1.4 | -3.0 |
| LLaVA-OneVision-7B Evaluation | Performance Loss | 0 | ~0 | 0 |
Experiment Figures
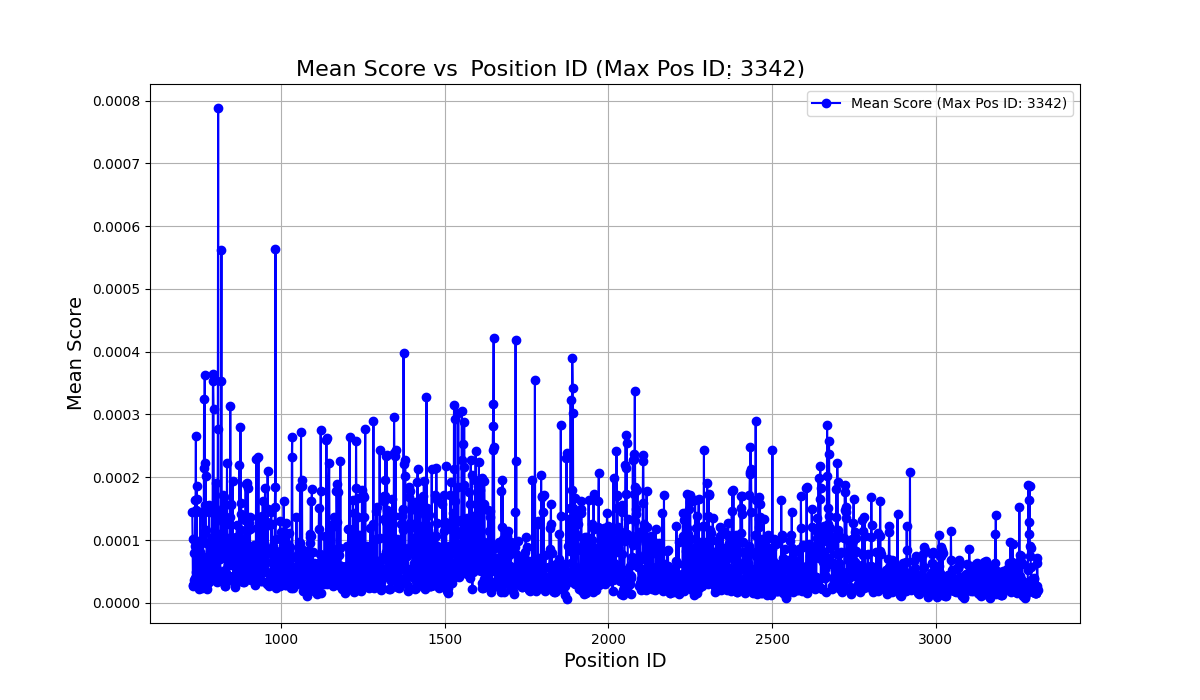
Comparison of pruning biases: Attention-based pruning vs. Position.
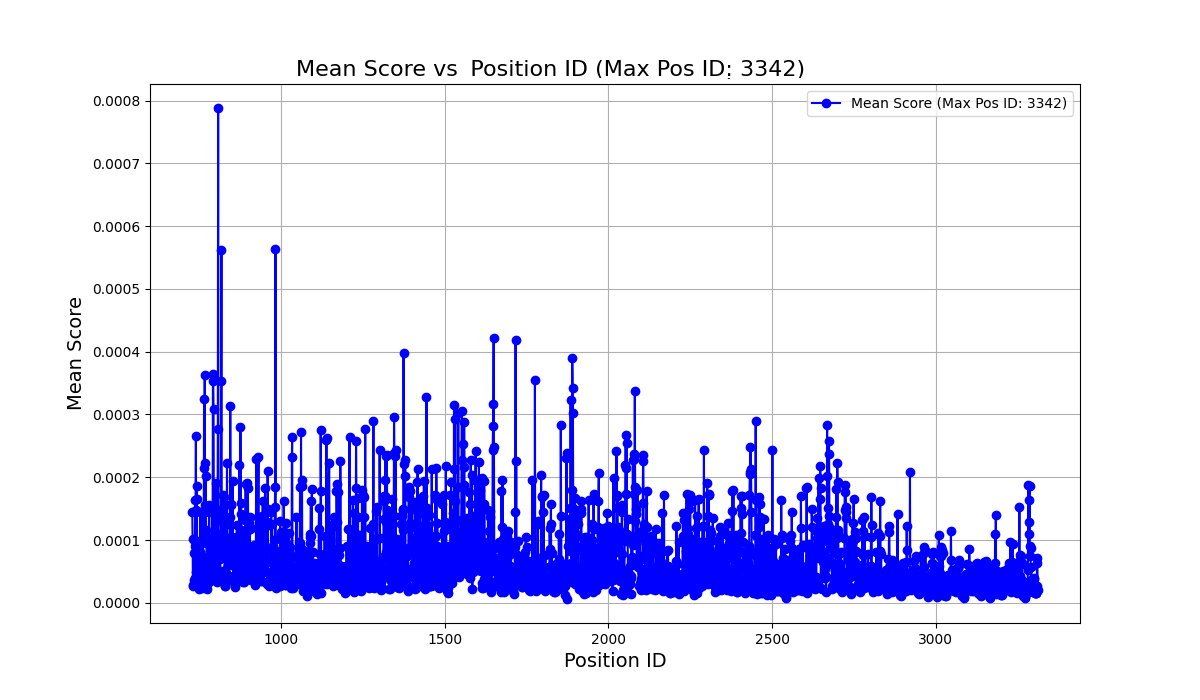
Histogram of Hidden State Norms at Layer 4.
Main Takeaways
- PACT achieves a 50% reduction in visual tokens with negligible impact on model performance.
- At aggressive reduction rates (71.3%), PACT preserves significantly more accuracy (1.4% drop) than competitors (4.4% drop).
- Hidden state norms in early layers exhibit high variance, validating their use as a signal for token importance.
- Combining pruning (removing useless tokens) with clustering (merging redundant tokens) yields better results than either approach alone.