📝 Paper Summary
LLM Evaluation
Agentic Simulation
Multi-Agent Systems
AgentSims is an interactive, open-source sandbox that evaluates LLMs by measuring their ability to complete long-term social and economic tasks in a simulated town.
Core Problem
Existing LLM benchmarks rely on static QA datasets or subjective black-box ratings, which fail to capture long-term planning abilities and are vulnerable to data leakage.
Why it matters:
- Static benchmarks (like GRE/SAT tests) cannot evaluate an agent's ability to adhere to instructions in multi-turn dialogue or mimic human social interactions
- Data contamination allows models to memorize test sets, making traditional benchmarks unreliable measurements of true capability
- Subjective metrics (human or GPT-4 rating) are non-reproducible, costly, or biased, whereas task completion rates in a simulation provide objective success metrics
Concrete Example:
In current benchmarks, an LLM might answer a multiple-choice question about leadership correctly. However, when placed in a simulated town as a 'Mayor' (the paper's case study), it might fail to actually resolve resident complaints or build necessary infrastructure because it lacks long-term planning and tool-use coordination.
Key Novelty
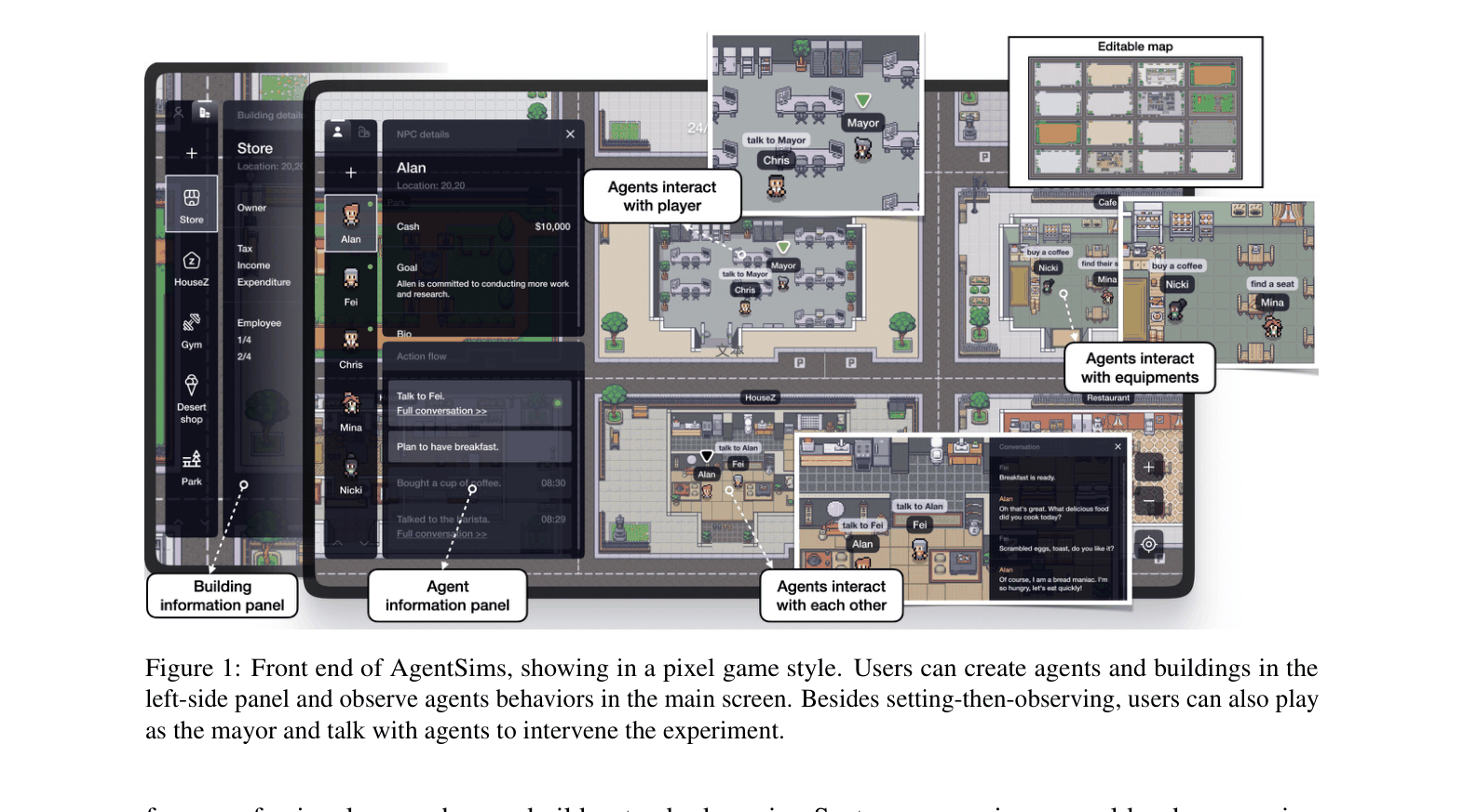
User-Friendly Sandbox Infrastructure for Task-Based Evaluation
- Provides a 'SimCity-like' interactive GUI where researchers can drag-and-drop buildings and agents without coding, lowering the barrier for interdisciplinary researchers
- Modularizes agent support systems (Memory, Planning, Tool-Use) into pluggable components, allowing developers to test specific mechanisms by swapping Python classes
Architecture
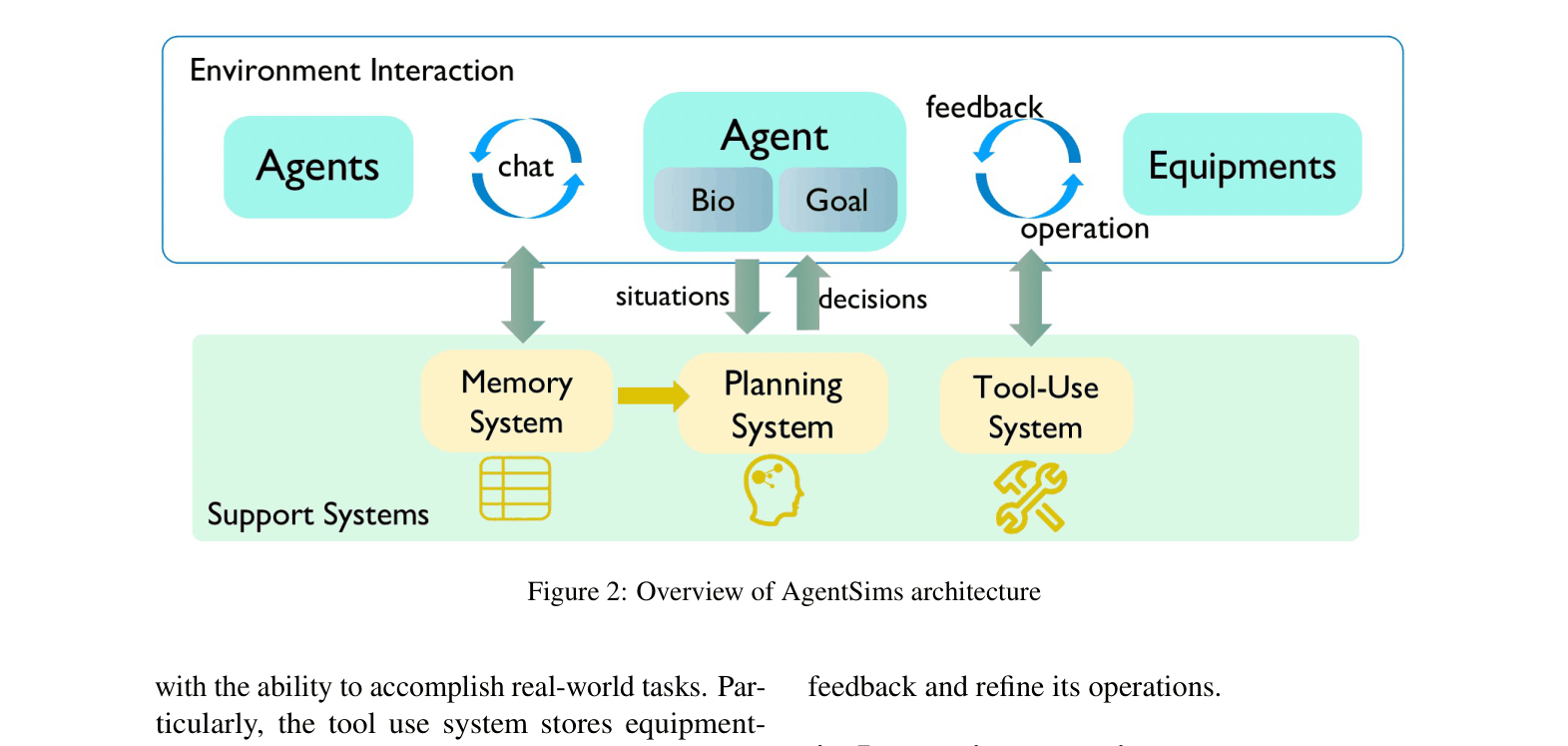
Overview of the AgentSims architecture, illustrating the loop between the Agent (Plan, Memory, Tool Use) and the Environment (Buildings, Equipment)
Breakthrough Assessment
7/10
Strong infrastructure contribution that democratizes agent evaluation with a GUI and modular design. However, the paper is a system description with no quantitative experimental results or baselines.