📝 Paper Summary
Tool-use post-training
Self-evolving Agentic reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
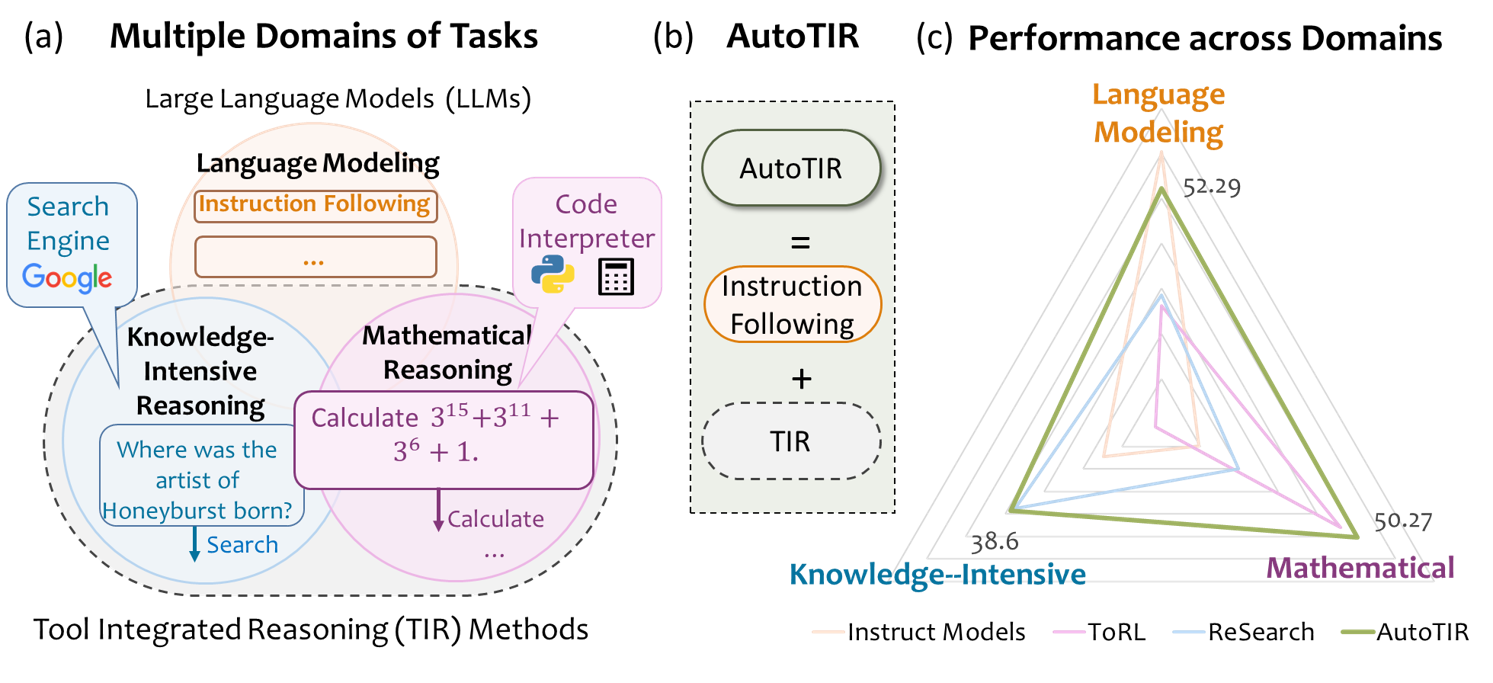
AutoTIR uses reinforcement learning with a hybrid reward system to teach language models exactly when and which tools to use, avoiding the degradation of general language skills common in rigid tool-use training.
Core Problem
Existing tool-use methods rely on rigid, predefined patterns that limit flexibility and often degrade the model's core language understanding and instruction-following capabilities.
Why it matters:
- Fixed tool patterns fail when tasks require adaptive decision-making (e.g., knowing when *not* to use a tool)
- Training on heavy tool-use traces often causes catastrophic forgetting of general language skills (instruction following)
- Current systems lack the autonomous decision-making ability to balance external tool reliance with internal parametric knowledge
Concrete Example:
In a general instruction-following task where no tool is needed (e.g., 'Write a poem'), a model trained with rigid tool patterns might unnecessarily invoke a search engine or code interpreter, failing the instruction. AutoTIR learns to skip tool usage in such cases while correctly invoking a calculator for math problems.
Key Novelty
Autonomous Tools Integrated Reasoning (AutoTIR)
- Treats tool use as a reinforcement learning policy optimization problem where the model learns *whether* to use a tool, not just *how*.
- Introduces a hybrid reward system combining 'Action Rewards' (incentivizing correct tool choice and penalizing redundancy) and 'Output Rewards' (verifying final answer correctness).
- Uses penalty terms to actively discourage unnecessary tool calls on tasks that should be solved via pure language reasoning.
Architecture
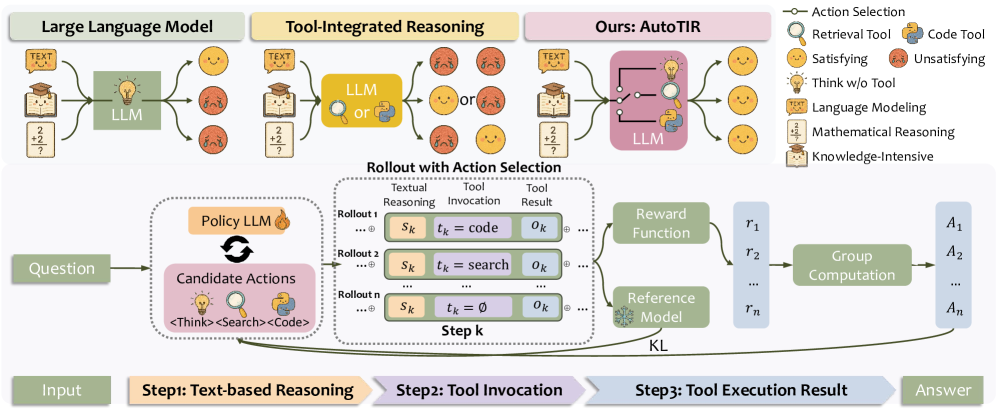
The iterative rollout process of AutoTIR including the <think> phase, decision to use tools (<code> or <search>), execution, and result integration.
Evaluation Highlights
- AutoTIR achieves superior overall performance across knowledge-intensive, mathematical, and general language tasks compared to baselines.
- Demonstrates superior generalization in tool-use behavior, effectively minimizing superfluous tool invocations while maximizing successful outcomes.
- Maintains strong instruction-following capabilities on general domain tasks where tool use is unnecessary, unlike baselines that suffer degradation.
Breakthrough Assessment
8/10
Strong contribution in solving the 'when to use tools' problem via RL, directly addressing the rigidity and degradation issues of SFT-based tool learning. The hybrid reward design is a practical and effective innovation.