📝 Paper Summary
Robot Learning
Language-Conditioned Manipulation
Synthetic Data Generation
A framework using LLMs to plan and verify robotic exploration data, which is then distilled into a robust language-conditioned diffusion policy for real-world manipulation.
Core Problem
Acquiring robust, reusable manipulation skills typically requires costly human demonstrations or inefficient trial-and-error exploration.
Why it matters:
- Human teleoperation and annotation are not scalable for large-scale data collection.
- Existing automated exploration methods often lack optimality, generality, or complete robot data labels (vision, action, text).
- Reinforcement learning exploration is inefficient for long-horizon, sparse-reward tasks.
Concrete Example:
In a 'catapult' task, a standard planar planner might only solve the easiest goal (closest bin) deterministically, failing to explore other bins. Without 6DoF exploration and automatic retries, the robot never generates the diverse success data needed to learn the full task distribution.
Key Novelty
LLM-Guided Data Generation & Diffusion Policy Distillation
- Use an LLM not as the final policy, but as a high-level planner that guides sampling-based robot utilities (grasping, motion planning) to generate diverse training data.
- The LLM writes its own success-verification code, enabling a 'verify & retry' loop where the robot automatically recovers from failures during data collection.
- Distill this messy, autonomously generated data into a multi-task diffusion policy that conditions on language and vision, inheriting robustness without needing expert demonstrations.
Architecture
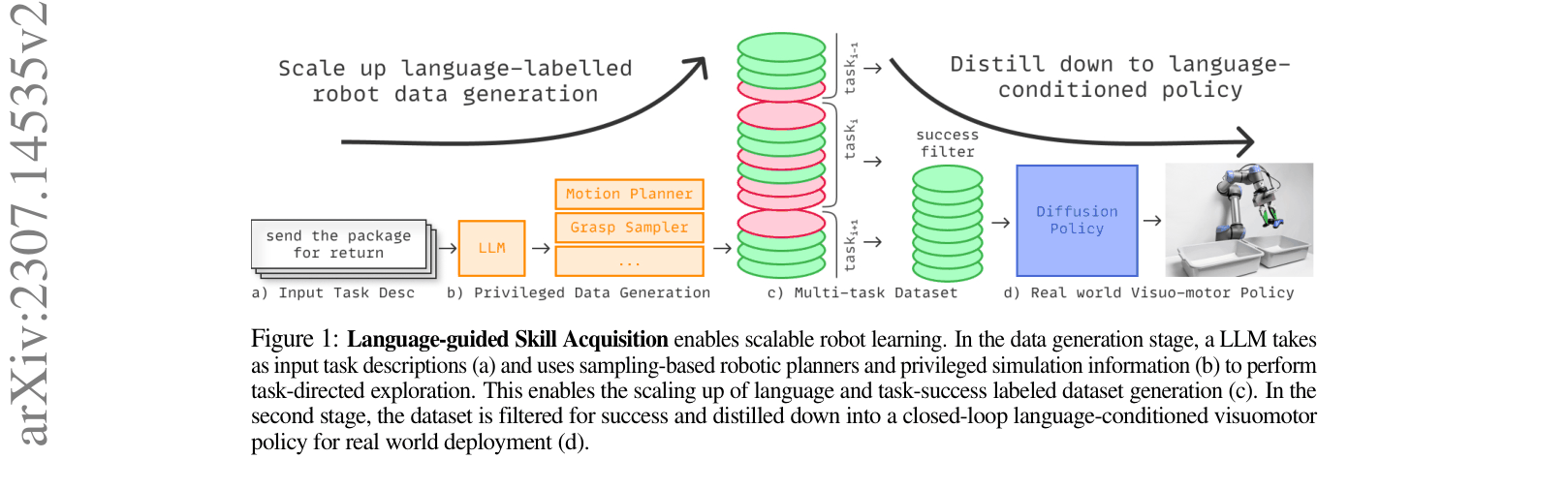
The two-stage framework: (1) LLM-guided data generation and (2) Language-conditioned diffusion policy distillation.
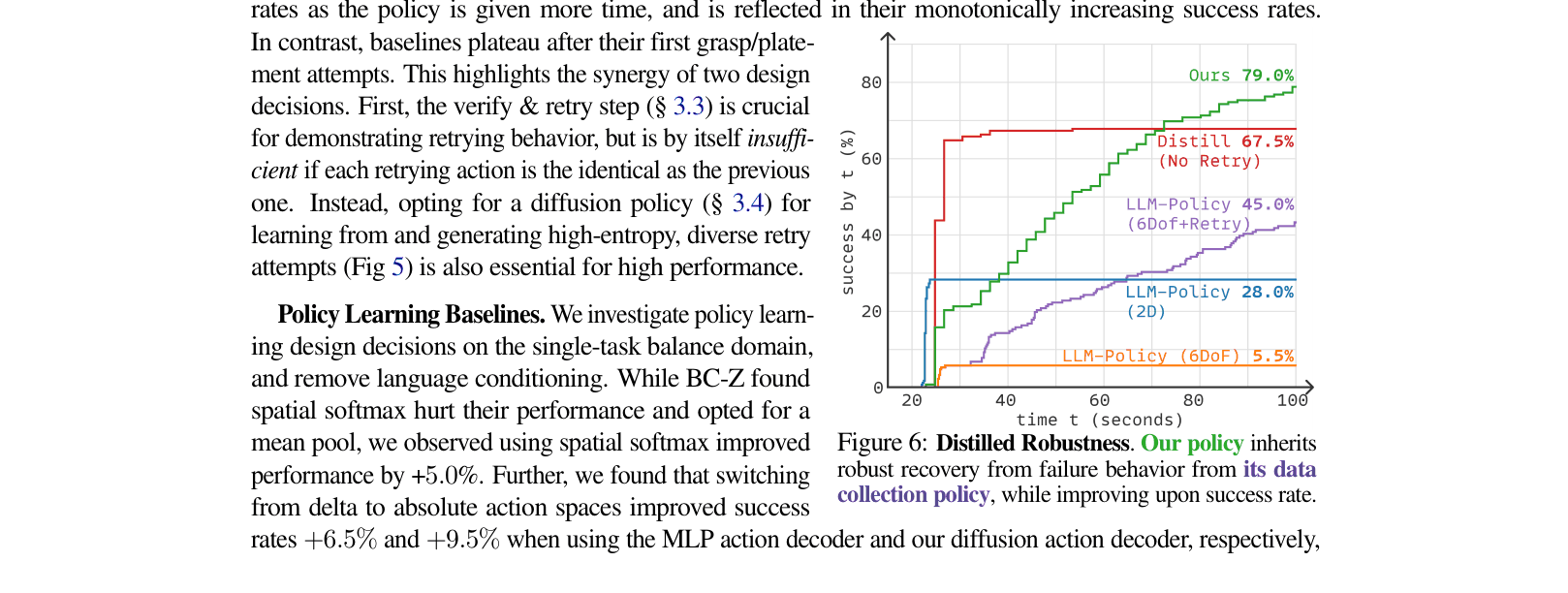
Evaluation Highlights
- Distilled policy improves success rates by +33.2% on average across five domains compared to the LLM data-collection policy itself.
- Achieves 76% success rate in real-world Sim2Real transfer on a transport task with unseen objects.
- The 'Verify & Retry' mechanism in data generation improves collection success rates by up to 13x (in Drawer domain) compared to no retries.
Breakthrough Assessment
8/10
Strong contribution in autonomous data scale-up. effectively bridging the gap between high-level LLM reasoning and low-level control via distillation, with impressive Sim2Real results.