📝 Paper Summary
Self-evolving Agentic reasoning
Multi-step tool use with flexible plan
TOOLMAKER is an agentic framework that autonomously installs, configures, and wraps complex scientific code repositories into executable tools for LLMs using a closed-loop self-correction mechanism.
Core Problem
LLM agents struggle with complex scientific tasks because they rely on pre-existing, manually implemented tools, and existing tool-creation methods cannot handle the complexity of installing external dependencies or interacting with the operating system.
Why it matters:
- Scientific discovery requires specialized, complex software (e.g., in genomics or pathology) that general-purpose LLM agents cannot use without manual integration
- Privacy restrictions in healthcare often prevent agents from building tools from scratch using sensitive data
- Existing agents like AIDE train simple models from scratch instead of using state-of-the-art foundation models available in public repositories
Concrete Example:
When tasked to 'predict a biomarker from a whole slide image', a standard agent might try to train a simple CNN from scratch (yielding poor results). A researcher would instead use a specialized pipeline like STAMP. TOOLMAKER autonomously installs the STAMP repository, downloads dependencies, and wraps it into a tool the agent can use.
Key Novelty
Autonomous conversion of paper repositories into executable tools
- Treats tool creation as a two-stage process: first autonomously setting up the execution environment (installing dependencies via Docker), then implementing the Python interface
- Uses a closed-loop self-improvement cycle where the agent executes its candidate tool, diagnoses errors (reading logs/files), and iteratively fixes the implementation until it works
Architecture
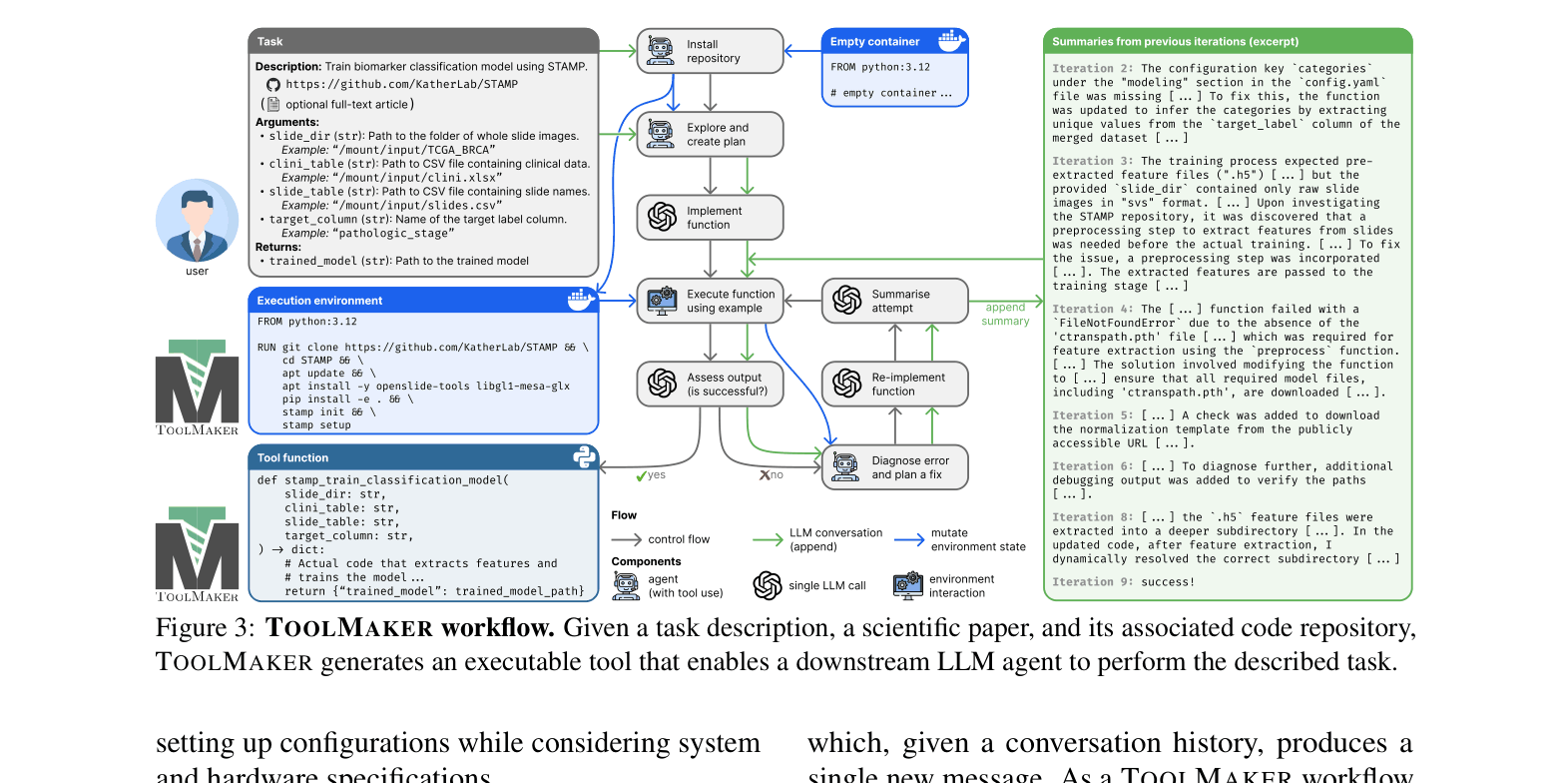
The TOOLMAKER workflow showing the separation of environment setup and the closed-loop implementation cycle
Evaluation Highlights
- Correctly implements 80% (12/15) of complex scientific tasks in the new TM-BENCH benchmark, compared to 20% (3/15) for the SOTA software engineering agent OpenHands
- Passes 116/124 unit tests across diverse domains (pathology, radiology, omics), significantly outperforming OpenHands which passed only 31/124 tests
- Demonstrates cost-effectiveness, averaging $0.94 per tool creation while handling complex multi-step installations involving GPU dependencies
Breakthrough Assessment
8/10
Significantly advances agentic capabilities by enabling agents to 'build their own tools' from existing complex software rather than just writing simple Python functions. Strong empirical results on a hard, realistic benchmark.