📊 Experiments & Results
Evaluation Setup
Continual pre-training on general data followed by zero-shot evaluation on specific tasks
Benchmarks:
- RULER (Noisy context & Long context retrieval)
- LongBench (Long-context understanding (QA, Summarization, etc.))
- NLGraph (Graph reasoning (structured data))
- HybridQA (Table reasoning (structured data))
- MMLU/HellaSwag/ARC (General short-context language understanding)
Metrics:
- Accuracy
- Exact Match (EM)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| RePo significantly outperforms baselines on noisy context tasks within the training length (4K). | ||||
| RULER (Noisy Context 4K) | Average Score | 76.43 | 87.47 | +11.04 |
| RULER (Noisy Context 4K) | Average Score | 59.81 | 87.47 | +27.66 |
| RePo demonstrates superior generalization to longer contexts (up to 16K) despite only being trained on 4K. | ||||
| RULER (QA + NIAH 16K) | Exact Match (EM) | 58.00 | 71.25 | +13.25 |
| LongBench | Average Score | 24.93 | 30.41 | +5.48 |
| RePo helps with structured data tasks where linear order is less meaningful. | ||||
| NLGraph + HybridQA | Average EM | 47.78 | 49.72 | +1.94 |
Experiment Figures
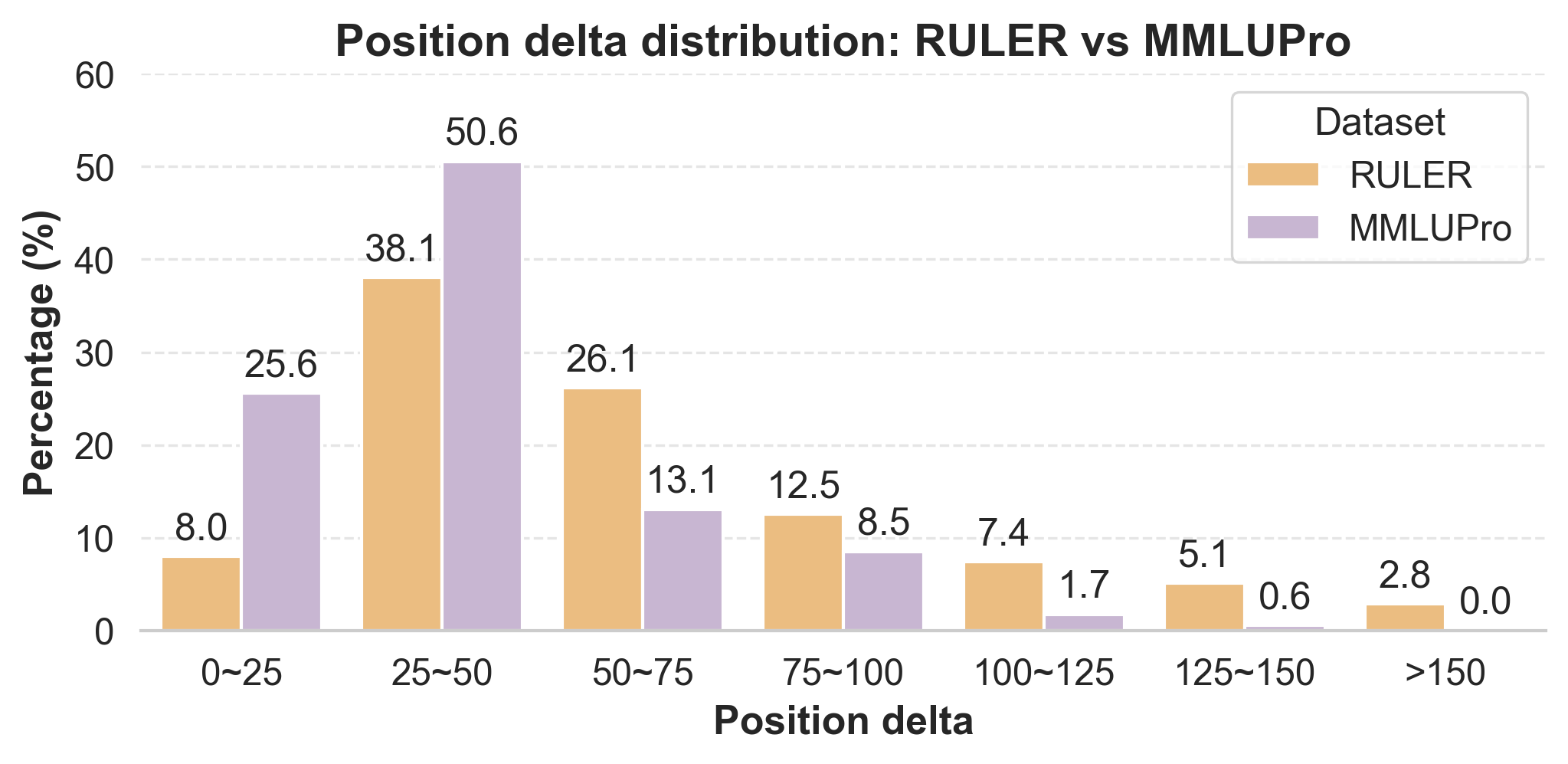
Distribution of assigned position distances and patterns.
Main Takeaways
- RePo effectively reduces extraneous cognitive load, evidenced by massive gains (+11 points) in noisy context tasks.
- The learned positions break locality bias: attention analysis shows RePo assigns 'needle' tokens closer to 'queries' in embedding space, enabling better retrieval.
- The method generalizes to 4x training length (16K tokens) better than strong baselines like YaRN-extended RoPE.
- Learned patterns are non-trivial: they are neither strictly linear nor constant, but a hybrid that adapts to the content structure (e.g., segmenting few-shot examples).