📝 Paper Summary
Self-evolving Agentic reasoning
RL-based tool use
Mathematical reasoning
ZeroTIR trains base LLMs to spontaneously learn code execution for math via outcome-based reinforcement learning, revealing scaling laws where accuracy, response length, and tool usage increase predictably with training steps.
Core Problem
LLMs struggle with precise math calculations; Supervised Fine-Tuning (SFT) limits exploration to specific patterns, while existing Tool-Integrated Reasoning (TIR) relies on rigid prompts rather than spontaneous, learned tool use.
Why it matters:
- Next-token prediction often hallucinates calculations, whereas code execution provides deterministic correctness
- Reliance on SFT trajectory data is expensive and constrains the model's ability to discover novel problem-solving strategies
- Existing ZeroRL approaches often ignore external tools, missing the potential for agents to offload computation autonomously
Concrete Example:
When asked to solve a complex equation, a standard LLM might hallucinate an incorrect arithmetic step. In contrast, the ZTRL agent spontaneously generates a Python script to calculate the roots numerically, executes it, and uses the output to derive the correct answer.
Key Novelty
Agent RL Scaling Law & ZeroTIR Framework
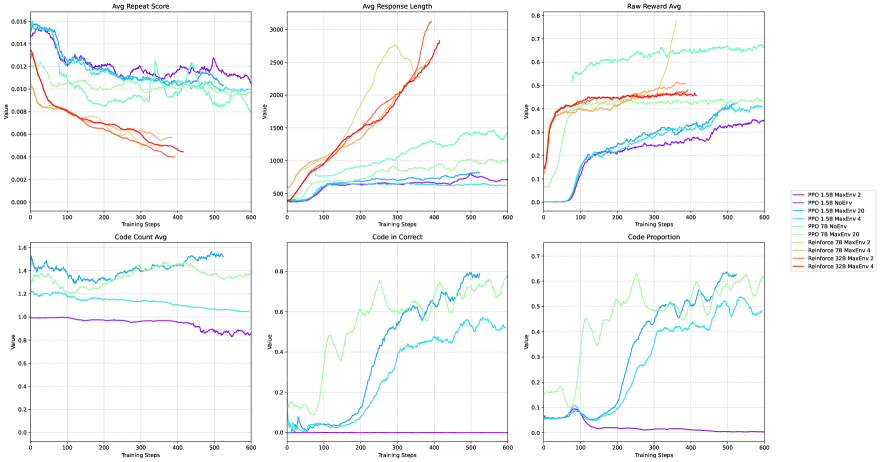
- Demonstrates a quantifiable 'Scaling Law' in Agent RL: as training steps increase, the model spontaneously increases code execution frequency and response length, correlating strongly with accuracy
- Introduces ZeroTIR: a framework to train general base models (not math-specialized) to use code interpreters from scratch using only outcome-based rewards, without supervised tool-use examples
Architecture
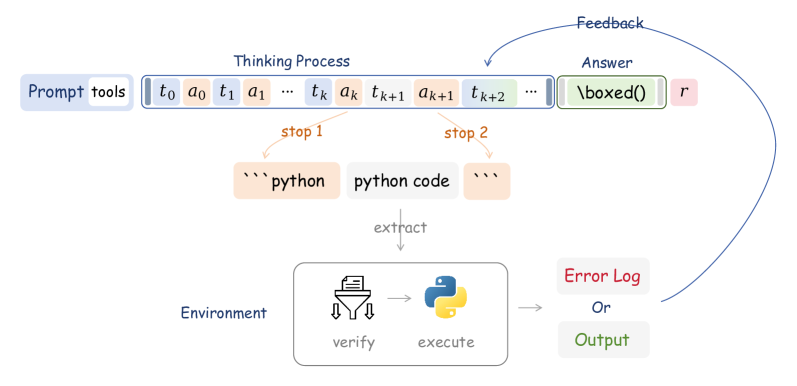
The state-machine interaction mechanism for spontaneous code execution during RL rollouts.
Evaluation Highlights
- 7B ZTRL model achieves 54.0% average accuracy on AIME24, AIME25, and MATH500, outperforming the math-specialized TORL baseline (51.8%)
- Surpasses SFT-based Qwen 2.5 Math Instruct (with TIR) by +10.7 percentage points (52.3% vs 41.6%) on the aggregated math benchmark
- Increasing the tool interaction cap from 0 to 4 boosts average performance by up to ~15 percentage points, validating the benefit of tool use
Breakthrough Assessment
8/10
Strong empirical evidence for spontaneous tool emergence via pure RL (ZeroRL) on base models. The identification of scaling laws for agentic behaviors is a significant contribution to understanding agent training dynamics.