📝 Paper Summary
Memory organization
Multi-call tool use with flexible plan
VideoAgent solves long-form video understanding by constructing a structured memory of event captions and tracked objects, which an LLM interactively queries using specialized tools.
Core Problem
End-to-end multimodal LLMs struggle with long-form videos due to prohibitive memory costs and attention limitations, failing to capture complex spatial-temporal dependencies and object details.
Why it matters:
- Processing lengthy videos with standard transformers is computationally expensive and often exceeds context windows
- Self-attention mechanisms frequently fail to capture long-range relations necessary for reasoning about causal events or specific object states over time
- Current agent-based approaches lack video-specific designs, leading to complicated pipelines that still underperform compared to end-to-end models
Concrete Example:
When asked 'What is the relationship between the boy and the adults?' in a long video, an end-to-end model might hallucinate based on a few frames. VideoAgent retrieves specific segments (9 and 13) showing the boy playing while adults supervise, then synthesizes these observations to infer they are likely parents.
Key Novelty
Unified Memory Mechanism for Video Agents
- Constructs a dual-memory system: 'Temporal Memory' for generic event descriptions (captions) and 'Object Memory' for tracking specific object states and trajectories via a database.
- Equips an LLM with a minimalist set of tools (e.g., segment localization, SQL-based object querying) to iteratively retrieve only relevant information from this structured memory rather than processing the whole video at once.
Architecture
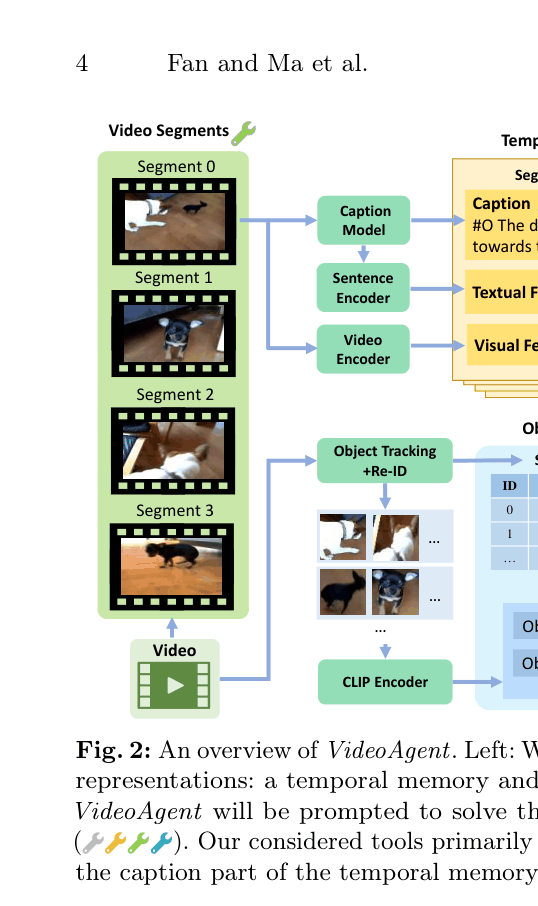
The dual-phase pipeline: Memory Construction (left) and Inference/Tool-Use (right).
Evaluation Highlights
- +26.0% accuracy improvement on EgoSchema (long-form reasoning) compared to Video-LLaVA baseline
- +6.6% average accuracy improvement on NExT-QA compared to SeViLA baseline
- Outperforms Gemini 1.5 Pro on EgoSchema subset (62.8 vs 63.2 is comparable, surpasses on subset logic in text)
Breakthrough Assessment
8/10
Significantly closes the gap between open-source models and proprietary giants (Gemini 1.5 Pro) on challenging long-video benchmarks by using a structured memory approach rather than raw context scaling.

