📝 Paper Summary
Multimodal Language Models
Agentic AI
Visual Reasoning
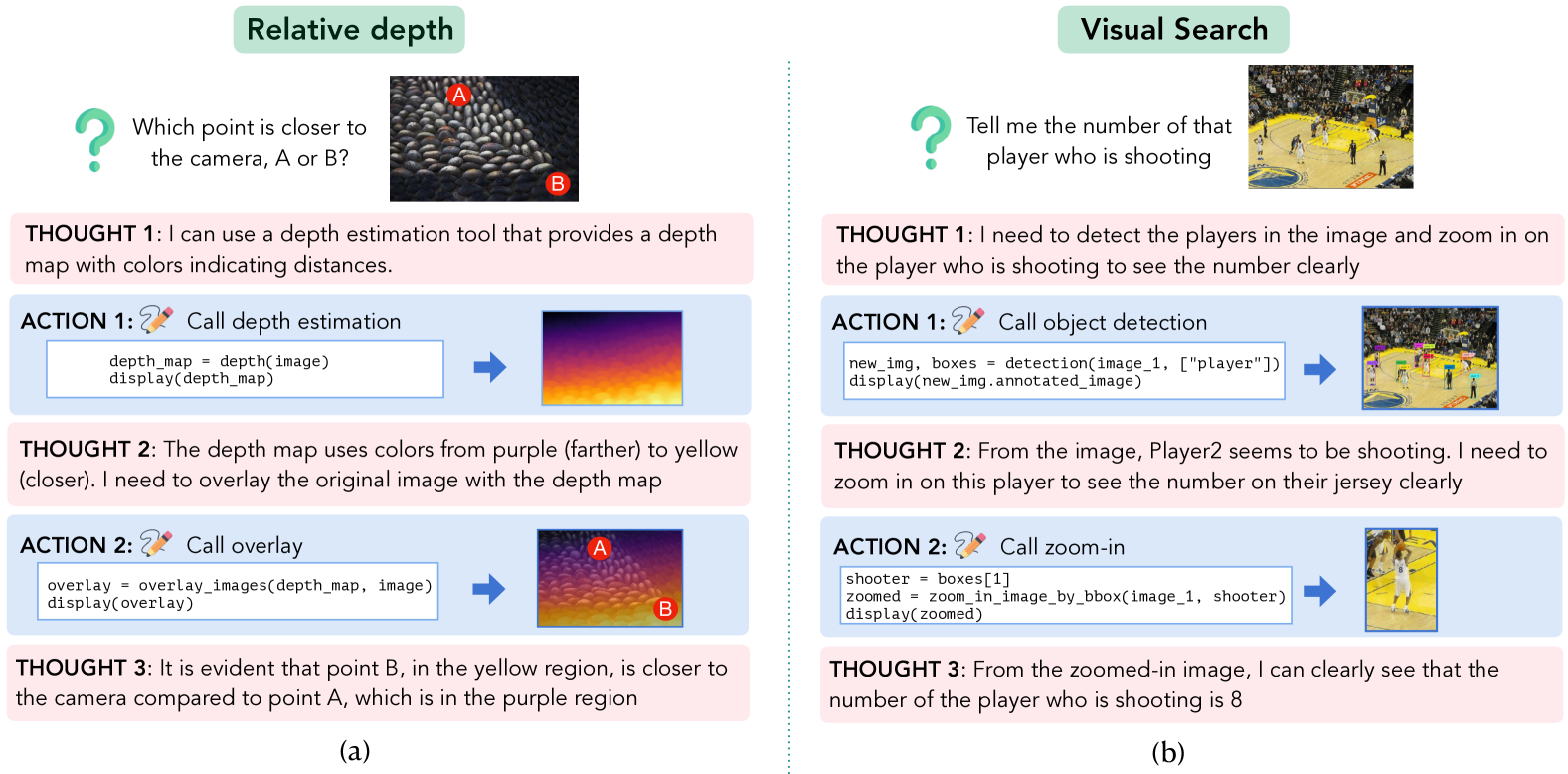
VisualSketchpad provides multimodal LMs with a framework to generate intermediate visual sketches (lines, boxes, masks) using Python tools to facilitate reasoning on complex vision and math tasks.
Core Problem
Current multimodal LMs rely on text-only intermediate reasoning (Chain-of-Thought), lacking the ability to draw visual artifacts (like auxiliary lines or bounding boxes) which are crucial for solving spatial and geometric problems.
Why it matters:
- Humans rely on sketching for problem-solving (e.g., auxiliary lines in geometry, marking maps), but LMs currently cannot replicate this visual-spatial reasoning process.
- Existing multimodal benchmarks (Geometry3K, BLINK) require symbolic grounding and spatial understanding that are difficult to express through text alone.
- Without intermediate visual steps, models struggle with tasks like proving geometric theorems or counting overlapping objects.
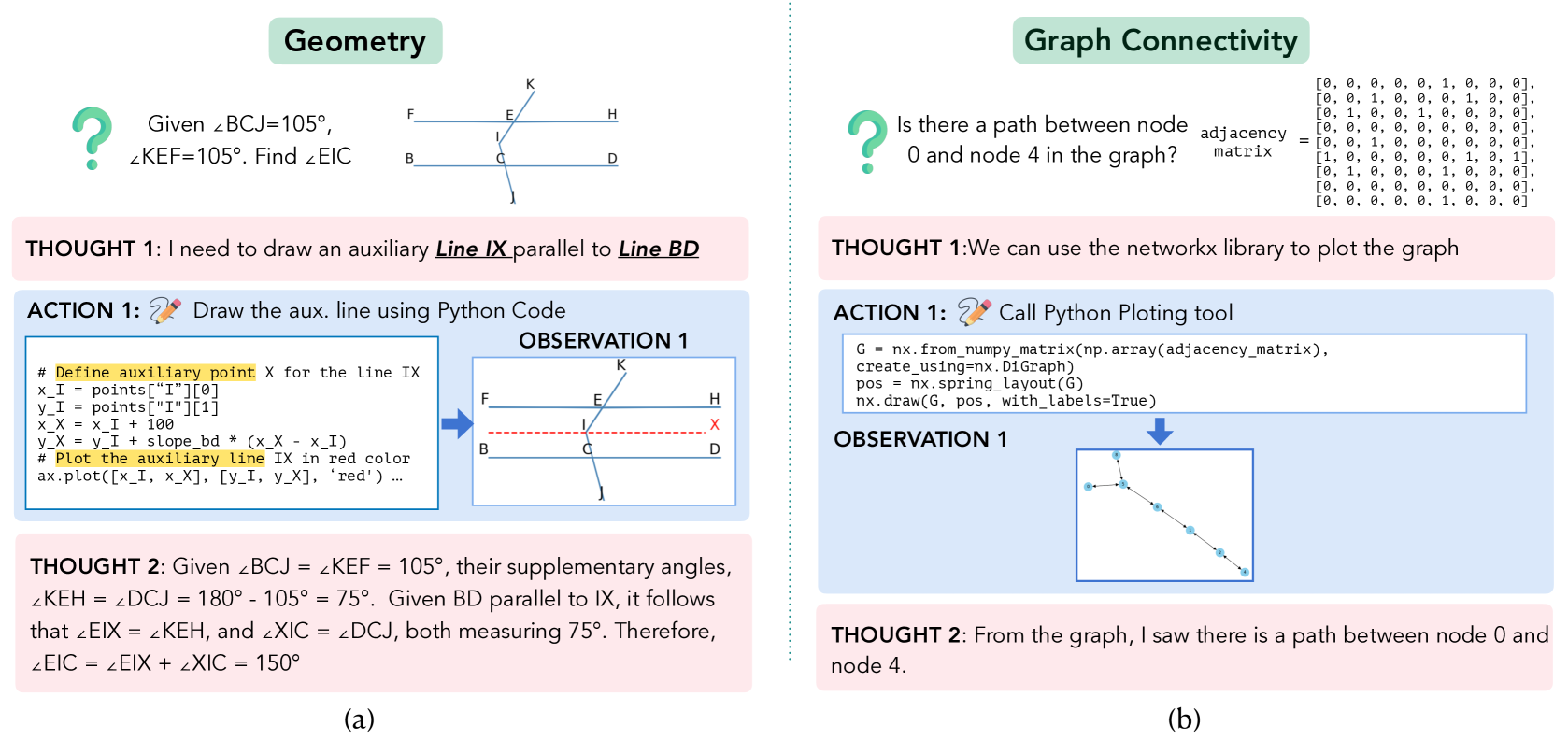
Concrete Example:
In a geometry problem asking to find an angle, a standard LM tries to solve it analytically and fails. With VisualSketchpad, the model writes Python code to draw an auxiliary parallel line on the image, visualizing the new angles to correctly solve the proof.
Key Novelty
VisualSketchpad (Visual Chain-of-Thought)
- Enables LMs to 'think' visually by generating Python code to modify input images or create new plots (e.g., drawing lines, segmenting objects) before answering.
- Generalizes tool use by integrating specialist vision models (detection, segmentation) and plotting libraries (Matplotlib, NetworkX) as sketching tools.
- Operates as an iterative agent: Thought (plan) → Action (generate sketch code) → Observation (view updated image) → Final Answer.
Architecture
The iterative Thought-Action-Observation loop of VisualSketchpad.
Evaluation Highlights
- +12.7% average accuracy gain on math tasks (Geometry, Functions, Graphs, Chess) for GPT-4o compared to baseline.
- +8.6% average accuracy gain on vision tasks (BLINK, V*Bench) for GPT-4o compared to baseline.
- Sets new state-of-the-art on V*Bench (80.3%), BLINK spatial reasoning (83.9%), and visual correspondence (80.8%) using GPT-4o.
Breakthrough Assessment
8/10
Significantly extends Chain-of-Thought into the visual modality without model training, yielding large gains on hard benchmarks. Bridges the gap between LMs and visual tools effectively.